重大升级 | SecGPT V2.0:打造真正“懂安全”的大模型
2025-04-16 10:12:47爱云资讯265
2025 年,AI不再只是内容生成工具,它正成为各行各业的“第二大脑”。
随着GPT-4.5、DeepSeek等新一代大模型的崛起,我们正进入Agentic AI(智能体AI)的时代—— 它不仅能对话,还能思考、执行和协作,正在重塑整个生产力范式:
AI Coding:开发者从写代码者,变为架构师和指挥官
Deep Research:安全研究员配备“超级助手”,漏洞分析效率倍增
Security Copilot:SecGPT不再是提示词工具,而是实战中的“作战参谋”
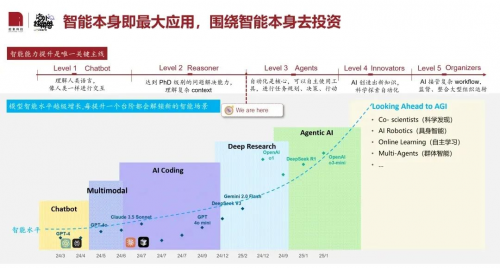
“模型即产品”正在成为现实,Agentic AI 正走入你我身边。
—— 引用自海外独角兽发布材料
而这一次,云起无垠没有止步于“能用”,我们在追求“好用”的同时,更关注真正实战可落地的AI安全能力。
从模型训练、数据构建、能力评测,到安全Copilot应用,我们打造出更聪明、更安全、更懂安全的SecGPT 2.0。开源模型可以去github下载使用。
Github开源地址:Clouditera/SecGPT
模型下载地址:clouditera/secgpt
数据集下载地址:datasets/clouditera/security-paper-datasets
下一站,我们将共同迈入Agentic Security的未来。
欢迎加入这场由“安全智能体”引领的技术革新!
01什么是SecGPT?
在通用大模型席卷全球的今天,云起无垠选择了一条不同的路:打造真正懂网络安全的大模型。
这不是一次“技术热潮”的追随,而是一次面向实战的系统性创新。
SecGPT,正是我们在2023年推出的开源成果——全球首个聚焦网络安全的大模型。
|我们希望它不只是“会说安全”,而是真正能“做安全”的智能体。
自发布以来,SecGPT持续受到全球安全技术社区的高度关注:
GitHub收获Star数突破2,300+
HuggingFace下载量超过10,000+
被数十家安全团队用于安全问答、漏洞归因、攻防演练等实战任务
SecGPT 能做什么?
SecGPT融合了自然语言理解、代码生成、安全知识推理等核心能力,已经能够胜任多种关键安全任务:
漏洞分析:识别漏洞成因、评估影响范围、提出修复建议
日志/流量溯源:辅助分析攻击链、复原攻击路径
异常检测:解析网络行为,判断是否存在潜在威胁
攻防推理:支持红队演练/蓝队研判,完成多轮策略分析
命令解析:识别脚本意图,揭示潜在风险操作
知识问答:成为团队“即问即答”的安全知识库
这些能力不再停留在“能回答”,而是可以被“调用”、“组合”、“协同”执行,支撑起复杂的安全智能任务流。

SecGPT 的定位:安全智能体的核心引擎
在“云起AI安全大脑”体系中,SecGPT是整个系统的统一语言理解与推理核心。
理解自然语言:大幅降低使用门槛,助力非安全专家也能上手
融合安全知识:具备上下文关联与多步推理能力
持续学习反馈:具备智能体持续优化、自我增强的能力
无论是作为单点智能助手,还是嵌入式任务引擎,SecGPT都已具备强大的适配性、扩展性与安全可控性。
02为什么我们要持续更新SecGPT?
自2023年SecGPT开源以来,大语言模型技术持续突飞猛进。从语言理解到逻辑推理,再到工具调用与多任务协同,行业标准几经更替,迈入智能体(Agentic AI)时代。与此同时,云起无垠也在持续推进商业版安全大模型 SecGPT Pro 的多轮迭代,核心能力已实现代际跃升。
但开源版本仍停留在早期阶段,在语言表达、安全理解与接口兼容性方面逐渐显现出技术边界,难以应对当前复杂多变的安全任务需求。因此,我们决定对SecGPT开源模型进行全面升级,持续回馈全球安全社区,并助推安全智能体在更多场景中的落地与演化。
1)模型基础设施演进,旧模型能力边界逐渐暴露
大语言模型领域的基础设施已经发生底层变动。相比早期模型,新一代模型具备更长上下文处理能力、更高效的注意力机制、结构更清晰的工具调用接口,以及支持Agent工作流的任务控制能力。例如,支持MCP协议、ReAct思维链、Routing插件架构、Function Calling、工具上下文记忆、部署端的量化控制与微调架构等,都已成为安全智能体设计中的“新基础”。
一旦开源模型长期不更新,将面临以下技术脱节问题:
无法适配新一代推理引擎(如 vLLM、TGI)
无法兼容结构化插件调用(Function/API 调度)
缺失任务链调度能力(Task-Aware Routing)
微调体系无法与最新安全数据对齐(SFT+RLHF+RAG混合)
随着智能体形态的普及,能力缺口将迅速放大,直接影响用户体验和模型落地价值。
2)安全任务结构升级,对模型能力提出多维要求
早期模型使用者多集中于问答类任务,例如安全知识普及、命令解析、脚本理解等。这类任务主要依赖语言理解能力,结构相对简单。然而,当安全模型真正进入研发、攻防、运营等实际场景后,任务呈现出明显的结构化、多轮化、工具化趋势:
漏洞链条重建→多日志输入+多阶段因果推理
多语言项目审计→代码上下文建模+跨文件引用分析
安全知识图谱构建→抽取实体/关系+图结构生成
安全运营协同→工具调度+状态反馈+报告输出
这类任务要求模型不仅具备语义理解能力,还要具备:
推理路径构建能力(Chain-of-Thought/Tree-of-Thought)
知识检索与融合能力(用于语境增强与准确性提升)
任务规划与阶段控制能力(支持多轮次有状态任务执行)
多工具协同使用能力(如模糊测试 + 漏洞扫描 + 资产识别)
原有SecGPT模型架构难以完成上述能力组合,仅靠 Prompt 注入或零样本提示远远不够。
3)现实挑战:通用模型无法替代专业安全模型
尽管DeepSeek、Qwen、LLaMA等开源大模型在通用语言理解、代码生成等任务中取得显著进展,但在安全场景下,它们面临以下结构性瓶颈,尤其在企业级私有部署环境中更为突出:
(1)知识盲区广泛,缺乏关键安全语料支撑
通用模型训练语料以开放领域为主,严重缺乏如下高价值安全语料:渗透测试日志、攻击链行为样本、系统调用轨迹、漏洞利用(PoC/Exp)、红队审计报告等。这直接限制了其对实战攻防细节的掌握能力。
(2)语义建模能力薄弱,缺乏安全背景意识
在漏洞成因理解、系统语境建模、协议行为解析等任务中,通用模型的理解能力多停留在浅层表述,无法进行因果链条建模与深层语义推理,缺乏“攻防语境”下的专业认知。
(3)工具接口调用不精准,缺失系统适配能力
通用模型未针对安全工具(如模糊测试框架、漏洞扫描器、静态分析引擎等)进行微调和适配,导致在调用第三方接口时经常出现参数配置错误、上下文不匹配、调用逻辑混乱等问题,严重影响任务可执行性和稳定性。
(4)任务链结构理解缺失,推理与执行脱节
安全任务往往涉及多步推理(理解→分析→调用工具→收集反馈→修复建议),通用模型缺乏对这类“任务链”结构的建模能力,常常出现中途跳跃、逻辑断裂、输出不可收敛等现象,无法胜任复杂工作流调度任务。
当前通用大模型在安全场景中往往表现为“语言流畅但逻辑混乱,表达顺畅但结果失真”。在真实系统环境下,其输出容易出现答非所问、指令不收敛、工具调用失败、上下文错乱等问题,难以支撑企业对安全智能体高可信、高精度、高可控的实际需求。
03本次更新,SecGPT能力提升了哪些维度?
本轮升级,我们同步发布了1.5B / 7B / 14B三个模型规格,全面适配从低配CPU、本地4090 GPU到企业级多卡集群等多种运行环境,实现大模型能力的普适化落地。更大规模的32B、72B、671B旗舰版也将在后续分批开放,进一步支撑企业级复杂安全任务的多轮推理与智能决策。
本轮更新亮点
1. 更强的基座能力:通用+安全深度融合
我们基于Qwen2.5-Instruct系列与DeepSeek-R1系列基座模型,结合自建安全任务集与安全知识库,在8台A100 GPU集群上持续训练一周以上,完成大规模预训练 + 指令微调 + 强化学习,显著提升模型在安全场景中的理解、推理与响应能力。
下图展示了一次训练过程中各关键指标的演化轨迹:
训练与验证损失(train/loss 与 eval/loss):二者均呈现出平稳下降趋势,说明模型在训练集与验证集上均持续收敛,未出现过拟合迹象。
学习率曲线(train/learning_rate):采用典型的 Warmup + 衰减策略,有效提升了早期训练的稳定性与收敛速度。
梯度范数(train/grad_norm):整体波动平稳,仅在少数步数存在轻微尖峰,未出现梯度爆炸或消失,表明训练过程健康稳定。
评估表现:eval/runtime与 eval/samples_per_second波动范围小,说明在评估过程中系统资源使用高效,推理吞吐量稳定。
其他指标:如训练轮数(train/epoch)、输入token 数量(train/num_input_tokens_seen)等也表明训练过程如期进行,达成预期计划。

模型训练与评估过程示例图
2. 更大的高质量安全语料库:私有 + 公共数据双轮驱动
我们已构建了一个超大规模、结构完备的网络安全语料库,总量超过5TB、共计106,721个原始文件,其中超过40%内容为人工精选与结构化处理。私有数据部分系统整合了具备70+字段 / 14类结构标签体系的安全数据资源,经过统一清洗、语义标注与重构,构建出数百亿 Tokens 级的高质量语料,为大模型深度推理能力提供坚实支撑。
下图展示了该语料库的构成维度,整体采集逻辑遵循“理论支撑 — 实战对抗 — 应用落地”三层结构体系:
理论支撑:涵盖法律法规、学术论文、行业报告等权威资料,为模型提供稳固的知识基座;
实战对抗:包括漏洞详情、CTF题库、日志流量、恶意样本与逆向分析等数据,提升模型对真实攻击行为的识别与追踪能力;
应用落地:涵盖安全社区博客、教育培训资料、安全知识图谱与自动化策略,增强模型在安全运营、辅助决策等场景中的适配能力。
技术亮点:
双轮驱动机制(私有 + 公共数据)保障语料在广度与深度上的协同提升;
多维标签体系使语料具备更强的结构化能力与上下文理解能力;
三层语料构建逻辑覆盖从知识构建、威胁应对到实战部署的完整安全任务链路。

3. 能力跃升:SecGPT正在蜕变为“安全助手”
通过多轮数据优化与任务精调,SecGPT已实现多个能力维度的跨越式进展:
更懂攻击链、攻防语言与行业术语
更擅长处理复杂日志与漏洞描述
更适配私有化部署、边缘推理等现实场景
核心能力提升详解
1. 模型能力评测:全面指标跃升,实战智能初现
为全面评估 SecGPT 的安全实战能力,我们构建了一套覆盖安全证书问答、安全通识、编程能力、知识理解与推理能力的综合评估体系,主要采用以下标准化数据集:CISSP、CS-EVAL、CEVAL、GSM8K、BBH。

在与原始模型 SecGPT-mini 的对比中,训练后的模型在所有指标上均实现大幅跃升,具体如下:
1)模型横向评测对比表

能力跃升解读:
mini→1.5B:具备“能答对”的基础问答能力,适配中低复杂度任务;
1.5B→7B:推理深度、泛化能力显著增强,能理解任务意图并构建较为完整的解决路径;
7B→14B:能力跃迁至“类专家”级,能够处理高复杂度推理、安全策略制定等高阶任务。
模型横向评测对比
相较于基础模型 Qwen2.5-Instruct,SecGPT 在所有评测指标上均实现实质性超越,反映出我们在数据构建、微调范式、安全任务精调机制上的整体优化成效:
 洞察亮点:
洞察亮点:
在CISSP和CS-EVAL等安全类数据集上,SecGPT 在所有参数规模下均表现优于Qwen2.5同规格版本;
表明我们构建的安全任务指令集与精调策略已显著提升模型的实战应用能力与专业问答深度。
2. 安全能力提升:更全、更准、更专业
本轮升级中,SecGPT在安全知识问答方面完成了从信息整合到逻辑输出的能力跃迁,具体体现在:
知识覆盖更全面:引入了涵盖法律法规、攻击战术、逆向分析等14类安全知识领域的结构化语料;
答案生成更精准:通过多轮对话控制与语义优化技术,提升了问答对齐率与上下文记忆稳定性;
推理能力更突出:具备多段知识联结与复合逻辑推演能力,能完成如攻击链分析、威胁研判等复杂任务。
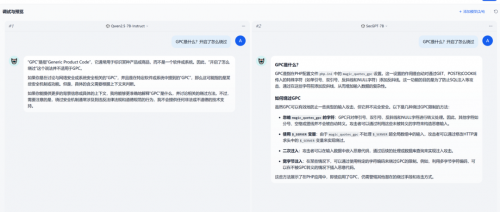
1)渗透测试场景能力
SecGPT 能够模拟渗透攻击流程,从信息收集、漏洞利用到提权横向,具备关键工具命令分析、Payload 构造、利用链生成等能力。



2)日志分析和流量分析能力
在安全日志与网络流量场景下,SecGPT 能自动识别异常事件、构建攻击链图谱、抽取关键 IOC(Indicator of Compromise),辅助完成事件溯源与告警分类。

3)逆向分析能力
基于对反汇编、API调用序列、加壳行为等低层数据的理解,SecGPT能辅助完成恶意样本的静态分析、特征提取与家族归类,具备一定的逆向辅助解读能力。



代码

5)工具使用

04接下来,我们要做的还有很多……
1. 发布首份网络安全大模型基准评测报告
我们即将发布首份网络安全大模型能力评测与选型报告,围绕威胁情报问答、代码审计、日志分析等典型场景,构建一套系统化、透明且可复现的评测体系,全面对比当前主流模型的能力边界。这份报告不仅为安全技术社区提供清晰的对比依据,也将成为合作伙伴制定Fine-tune策略和智能体架构选型的关键参考材料。
2. 全面复盘:如何训练一个真正“懂安全”的大模型
尽管通用大模型在语言理解领域已取得显著进展,但能够真正理解攻击链逻辑、漏洞细节、胜任安全推理与实战辅助的大模型仍然稀缺。 我们将以全栈视角,全面复盘“如何训练一个好用的安全大模型”,包括高质量安全训练数据构建、模型架构调优、多任务对齐训练、能力评测体系设计等关键环节,打通数据→算法→评测的闭环路径,推动安全智能体的实用化落地。
3. 自动化 CTF 解题能力建设:迈向安全智能体的第一步
我们正在持续推进SecGPT在CTF解题任务中的自动化能力,目标是实现“理解题意 → 推理思路 → 构造Payload → 完成解题”的闭环流程。
目前模型已在大量真实题目中完成微调,具备初步能力:理解题意与还原考点,自动构造注入、命令执行、ROP等攻击链,解释与变换攻击命令含义,同类题型的迁移泛化表现良好。
下一步,我们将聚焦标准化数据构建、解题评分指标、自动解题Agent原型开发,以及联合社区开展实战挑战验证。CTF场景将成为安全大模型迈向Agent化的典型突破口。
4. 安全训练数据集逐步开放,共建数据基座
我们正在建设并逐步开放一批具备混合结构、场景标签的高质量安全数据集,覆盖知识问答、代码审计、漏洞挖掘、威胁情报解析、流量分析等关键任务场景。 未来将支持多语言、多模态、多任务协同训练,进一步增强安全大模型的泛化能力和实战适应性。我们诚邀社区、企业、高校共同参与数据共建,共同筑牢安全模型的数据底座。
05最后,邀请你一起参与SecGPT的共建
SecGPT的成长离不开安全社区的反馈与参与。我们欢迎:
安全研究员提供数据、使用场景与测试建议
企业用户参与内测,共同打造实用、可靠、安全的行业模型
欢迎关注我们,即将开放下一轮模型内测与插件测试通道!
你最希望SecGPT能替你解决哪些安全难题?欢迎留言讨论。
相关文章
- 信通院栗蔚:大模型推理应用重塑云智算技术体系
- 重大升级 | SecGPT V2.0:打造真正“懂安全”的大模型
- 亚信科技+阿里云 | 大模型协作新突破,让百行千业用上普惠AI !
- 博大数据高辉对话算力行业专家:AI大模型与算力产业深度融合,推动可持续发展
- 北京筑龙:AI大模型在采购评审中的落地
- AI赋能审计:“知识×AI大模型”推动审计系统变革
- 九科信息bit-Agent智能体,打通企业应用DeepSeek等大模型的最后一公里
- 2024公有云大模型调用量,火山引擎中国第一!
- 腾讯云TVP AI与安全高峰论坛圆满落幕,共探大模型时代的安全破局之道
- 大模型一体机塞进这款游戏卡,价格砍掉一个数量级
- 阿丘科技李嘉悦:大模型驱动的AI检测范式变革——大模型、小模型、智能体的协同进化
- 行业观察 | 酷狗音乐的AI“智变“:当大模型成为音乐体验的基础设施
- 宇视大模型进机场:误报少了,调度快了,旅客笑了!
- 华为与宜兴联合发布城市安全大模型“天机镜”
- 九章云极 DataCanvas Alaya NeW智算操作系统首批首家通过中国信通院“大模型推理平台”标准评估
- 星汉大模型2.0:AI大模型浪潮奔涌 大华股份呈交“智能答卷”





