部署DeepSeek-R1全参数模型,云彣48GB大容量存储方案成关键
2025-03-11 15:23:31爱云资讯5181
自DeepSeek-R1发布以来,便在业界引起了广泛关注。其不仅集成了前沿的“思维链”技术,在处理复杂任务时展现出非凡的推理能力,而且还通过算法优化显著降低了本地部署的成本。尽管如此,具备完整671B参数规模的DeepSeek R1模型,对硬件的要求依然很高。

那么,有没有更为经济的方法来实现这一强大的AI模型呢?其实是有的,通过针对性的量化技术对原有模型体积进行压缩,从而能够大幅降低本地部署成本。
什么是动态量化
动态量化是指对模型的关键层实施4到6bit的高精度量化,同时对那些非关键的混合专家层(MoE)采用更为激进的1到2bit量化方法。通过这种针对性的量化手段,DeepSeek R1模型能够被压缩至最少131GB(1.58-bit量化),在保证参数量的前提下,大幅度降低了本地部署的门槛。
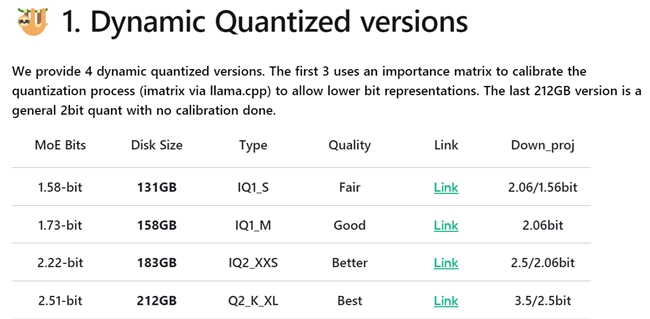
模型选择与配置方案
为了实现更低成本部署,此次我们采用了131GB大小的1.58-bit量化模型,同时以云彣(UniWhen)「珑」系列DDR5 192GB(48GB*4)套条来代替显存方案。

云彣(UniWhen®)隶属于紫光国芯旗下,产品主打国韵设计。云彣(UniWhen)「珑」系列DDR5 192GB套条专为大容量存储需求而生,其单条容量高达48GB。不仅能够满足满血版DeepSeek R1本地部署,同时以高品质原厂颗粒与十层PCB堆叠设计的卓越用料,为AI运算提供强力支持。经云彣(UniWhen)严苛二级验证测试,其广泛兼容市售主流主板,并支持Intel XMP 3.0与AMD EXPO一键超频技术,无需复杂步骤即可一键畅享高效数据处理能力。

外观设计层面,云彣(UniWhen)「珑」系列DDR5 192GB套条从传统文化中汲取灵感,以“龙”元素为主题,配合古代城楼的“飞檐翘角”,令华贵、庄严气质扑面而来。其还提供云锦白与朱砂红两款色泽任君择选,以便彰显个性品味。若追求RGB氛围,则可选择相同设计的云彣(UniWhen)「煌」系列,其顶部覆有1600万色雾化导光条,且支持灯光同步功能。
实战部署指南
下载 LM Studio:访问 GitHub页面 或 官方网站 获取最新版本的安装包和官方文档。
运行安装:以Windows为例,下载安装包后双击运行,等待安装启动和自动结束并打开界面。
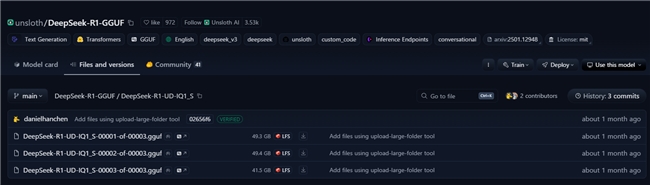
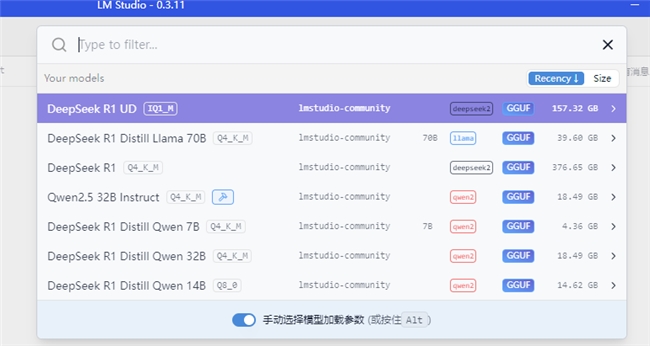
下载模型:从Hugging Face网站下载unsloth DeepSeek-R1 GGUF 1.58-bit量化模型。
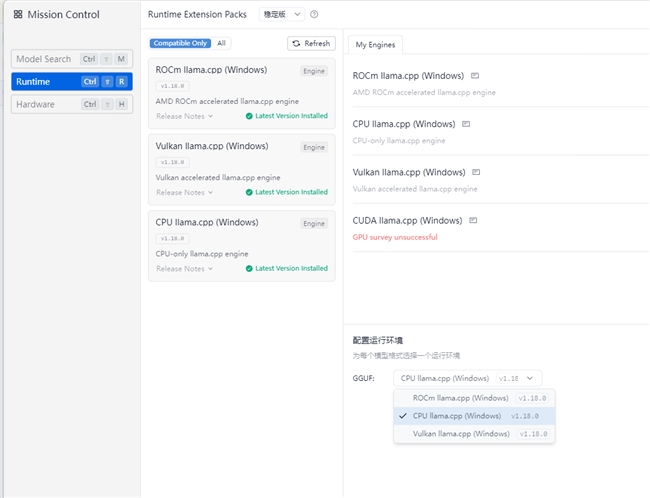
模型配置与微调:在LM Studio设置中选择CPU llama,使用内存加载AI模型。
DeepSeek R1本地部署体验
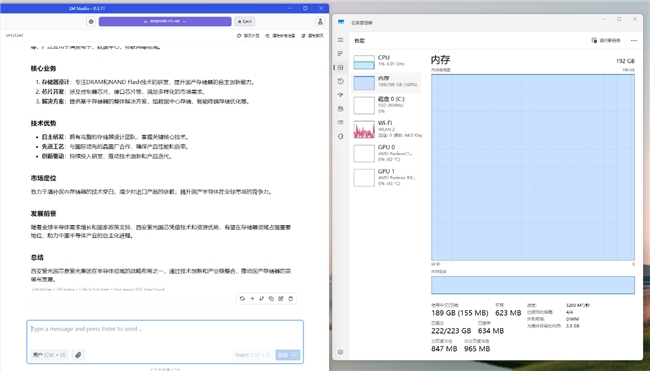
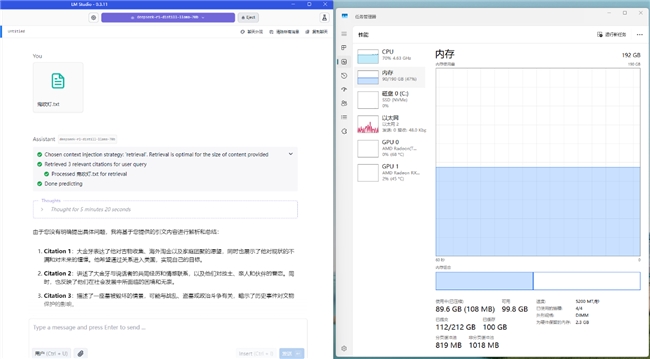
在上下文长度设定为20000,且仅使用CPU运算条件下进行测试。DeepSeek R11.58-bit量化模型经云彣(UniWhen)「珑」系列DDR5 192GB套条加持,运算速度达到2.44 tok/sec,内存使用达到189GB,占用率则为100%。其表现足以证明在日常任务中,可以获得较为流畅的问答体验。

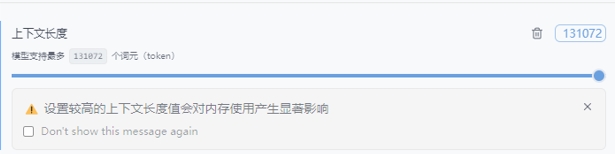
而如果有长文本对话需求的用户,则可以使用非满血的70B蒸馏模型。在最大131072上下文长度条件下,云彣(UniWhen)「珑」系列DDR5 192GB套条依然能够完整加载模型,并高效完成运算百万字数级别小说所需的数据处理任务。其内存使用降至90GB,占用率则为47%。冗余非常充足。
低成本部署的理想之选
面对AI算力逐渐增长的硬件需求,如何以更低成本进行本地化部署,成为中小企业和个人用户共同的难题。而云彣(UniWhen)「珑」系列DDR5 192GB套条,不仅能完美承载满血DeepSeek R1模型,带来更智能的AI体验,还凭借其卓越的材质和杰出性能,在高强度运算中确保高效稳定。相较于传统显存方案,其无疑是预算有限用户更为理想的选择。
相关文章
- AI本土化版图再拓展 三星Galaxy S25系列支持DeepSeek-R1
- 接入DeepSeek-R1!三星Galaxy S25系列AI能力再加强
- 智联招聘“AI招聘助手”Deepseek-R1版上线
- 九章云极DataCanvas上线DeepSeek-R1原装满血API
- 汽车行业首发!腾讯云助力东风风行APP上线DeepSeek-R1满血版
- 360联合北大震撼发布!5%参数量逼近Deepseek-R1满血性能
- 基调听云首发 《大模型服务性能评测 DeepSeek-R1 API 版》第一期
- Infinix AI接入DeepSeek-R1满血版,全新NOTE系列引领无缝AI体验
- 免费不限量、免部署,通义灵码支持DeepSeek-V3 和 DeepSeek-R1 满血版
- DeepSeek-R1 API 服务深度评测:火山引擎全面领先
- 量化技术赋能+通信传输优化!天翼云支撑DeepSeek-R1降本增效
- 思必驰AI办公本先行接入DeepSeek-R1大模型,简直太强了!
- 手把手教您使用DFRobot LattePanda Mu部署DeepSeek-R1蒸馏模型
- 通义灵码全新上线模型选择功能,新增支持 DeepSeek-V3 和 DeepSeek-R1 满血版模型
- 671B 满血 DeepSeek-R1 上线!青云科技一文教你如何创建自己的 AI 应用
- 金山云支持DeepSeek-R1/V3





