手把手教您使用DFRobot LattePanda Mu部署DeepSeek-R1蒸馏模型
2025-02-14 13:50:53爱云资讯7532
在大语言模型的训练过程中,提升推理能力一直是科研人员关注的重点。DeepSeek-R1模型通过创新性的强化学习(RL)方法,实现了无需依赖人工标注的自主推理能力提升。它通过自我反馈机制学习处理复杂推理任务,如数学问题和编程逻辑。

DeepSeek-R1的训练分为两个主要阶段:在“冷启动”阶段,模型使用少量高质量样本进行微调,以提高推理清晰度;接着在强化学习阶段,通过拒绝低质量输出进行优化,从而增强推理能力。此外,该模型采用精心设计的数据混合策略,以高效培养特定领域的表现,达到了在低人工干预下实现复杂问题解决的目标。
如何将DeepSeek-R1蒸馏模型实现本地部署?
第一步:选择性价比合适的开发板
传统的高性能主板如Jetson Orin和Nano虽然出色,但往往价格昂贵且尺寸较大,适用性有限。DFRobot LattePanda Mu(拿铁熊猫开发板)是一款高性能微型x86计算模块,搭载Intel N100四核处理器,配备8GB的LPDDR5内存和64GB存储,能流畅运行复杂的深度学习任务。它拥有多种扩展接口包括3个HDMI/DisplayPort接口、8个USB 2.0接口、最多4个USB 3.2接口以及最多9个PCIe 3.0通道,还提供开源载板设计文件,支持根据项目需求进行灵活定制。
第二步:选择合适的框架来高效加载和执行大语言模型
根据Deepseek官方说明,本地部署可以使用VLLM和SGLang的方式,但是通常情况下,这两种调用方法不仅操作复杂还占用量大,小编推荐另一种高效快捷的方法——使用Ollama框架。
第三步:安装Ollama
在Ollama官网下载安装。如果你也使用Ubuntu系统,可以直接通过如下指令来安装。

根据硬件的性能以及实际的需求来选择不同参数大小的模型,没有配备专业级显卡的,推荐用14B以内的模型。(复制代码如下)
1.ollama run deepseek-r1:1.5b
2.ollama run deepseek-r1:7b
3.ollama run deepseek-r1:8b
4.ollama run deepseek-r1:14b
5.ollama run deepseek-r1:32b
6.ollama run deepseek-r1:70b
7.ollama run deepseek-r1:671b
32b,70b,671b对机器的要求如下:
● DeepSeek-R1-Distill-Qwen-32B
VRAM需求:约14.9GB
推荐GPU配置:NVIDIA RTX 4090 24GB
RAM:建议至少32GB
● DeepSeek-R1-Distill-Llama-70B
VRAM需求:约32.7GB
推荐GPU配置:NVIDIA RTX 4090 24GB × 2
RAM:建议48GB以上
● DeepSeek-R1 671B(完整模型)
VRAM需求:约1,342GB(使用FP16精度)
推荐GPU配置:多GPU设置,例如NVIDIA A100 80GB × 16
RAM:512GB以上
存储:500GB以上高速SSD
需要注意的是,对于671B模型:
1.通常需要企业级或数据中心级硬件来管理其巨大的内存和计算负载。
2.使用量化技术可以显著降低VRAM需求。例如,使用4位量化后,模型大小可降至约404GB。
3.使用动态量化技术,可以进一步降低硬件需求,将大部分参数量化到1.5-2.5位,使模型大小降至212GB-131GB之间。
4.对于本地部署,可能需要考虑使用多台高性能工作站或服务器,如使用多个Mac Studio(M2 Ultra,192GB RAM)来满足内存需求。
5.运行完整671B模型时,还需考虑功耗(可能高达10kW)和散热等问题。
总的来说,32B和70B模型可以在高端消费级硬件上运行,而671B模型则需要企业级或数据中心级的硬件配置。选择合适的硬件配置时,还需考虑具体的使用场景、性能需求和预算限制。
第四步:运行DeepSeek-R1蒸馏模型
LP Mu 运行速度参考
对于不同规格的Mu和R1模型,在Ollama的运行速度参考如下(tokens/s):
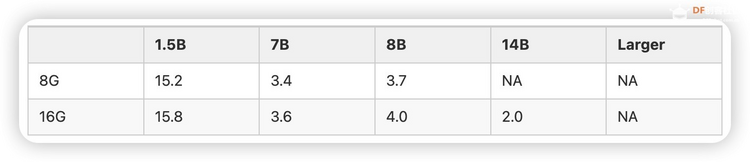
注:8B模型基于Llama-3.1-8B蒸馏,7B模型基于Qwen2.5-Math-7B蒸馏,如果是老师在学校使用更推荐7B。
Ollama官方提供了计算推理速度的工具,只要在聊天窗口输入/set verbose就能使其在每次回复后自动输出运行速度,

输出结果如下所示:

这样,理论上我们已经可以正常使用啦!
随着技术的发展,SBC(单板计算机)和类似 LattePanda Mu 的小型计算平台在边缘计算和定制化应用中展现了更多可能性。同时,DeepSeek 模型的强大推理能力为这些平台带来了新的潜力。DeepSeek 在数据库查询、文本理解等智能应用领域表现出色。未来,随着 LattePanda Mu 和 DeepSeek 的进一步优化,开发者和研究者将在各种硬件环境中更好地利用深度学习和大语言模型,推动更智能、高效的应用实现。
关于如何“如何用DFRobot LattePanda Mu(拿铁熊猫开发板)部署DeepSeek-R1蒸馏模型?”您可以访问:DF创客社区,了解更多详情。
相关文章
- 九科信息bit-Agent智能体,打通企业应用DeepSeek等大模型的最后一公里
- DeepSeek 赋能保险业,帆陌飞保逐鹿低空保险
- 探秘 DeepSeek 落地进展,腾讯云携手业界专家共话 AI 生产力
- DeepSeek预测中大型企业招聘优先挑选AI招聘系统!
- RAGFlow调用DeepSeek,青云科技让用户轻松突破智能检索、知识管理难题
- DeepSeek驱动行业智变提速,腾讯云汇聚大咖共话进阶之路
- Holopix AI携手腾讯云接入DeepSeek,开发者工作效率提升60%-70%
- 鸿蒙版百度地图融合DeepSeek,一句话get智慧出行服务
- 联想小新 Pro 系列携 DeepSeek 来袭,“屏”实力让热 AI 不止!还有 20% 国补等你拿!
- DeepSeek引爆合规刚需,启明星辰发布“大模型应用内容合成水印系统”!
- 新品 AI 背调发布!DeepSeek赋能羽山数据,助力人力背调方案升级
- 上海交通大学鲲鹏昇腾科教创新卓越中心特训营DeepSeek专场圆满举办
- DeepSeek-V3-0324上线,声网对话式AI引擎同步支持
- 弘成企业培训平台接入DeepSeek,解锁业务增长新势能
- 鼎捷携手DeepSeek大模型,开启中国制造业AI智慧化新时代
- 率先接入DeepSeek V3最新版!腾讯云大模型知识引擎高效搭建金融AI应用





