昆仑万维「天工大模型4.0」o1版(Skywork o1)正式启动邀请测试
2024-11-27 14:32:44爱云资讯206689
今天,昆仑万维正式推出具有复杂思考推理能力的系列模型——「天工大模型4.0」 o1版(Skywork o1)。
Skywork o1是由昆仑万维集团发布的具有慢思考推理能力的系列模型。这是国内第一款中文逻辑推理能力的o1模型。不同于现有的复现OpenAI o1模型的工作,Skywork o1不仅在模型输出上内生了思考、计划、反思等能力,同时,该开源模型在标准评测集上,对比普通模型推理能力大幅上升,真正让模型拥有了思考和反思带来的推理能力的提升。团队复现o1的技术路线,使得初始推理能力较差的基座模型在基准测试集上成为生态位SOTA。
此次发布的Skywork o1包括三款模型,既有回馈开源社区的开放版本,也有能力更强的专用版本:
1,Skywork o1 Open:一款基于Llama 3.1 8B的开源模型,该模型在同生态位开源模型中评测指标大幅提升达到SOTA水平,并解锁了许多轻量级模型无法解决的复杂数学任务。该模型的发布也将帮助加速国内开源社区复现o1的进程。
2,Skywork o1 Lite:该模型具备完整的思考能力,具有更好的中文支持和更快的推理和思考速度。在数学、中文逻辑和推理类问题上表现突出。
3,Skywork o1 Preview:这款模型是本次完整版的推理模型,搭配自研的线上推理算法,对比Skywork o1 Lite有着更多样和“深度”的思考过程,更完善和更高质量的推理。
其中,我们开源的Skywork o1 Open,在各项数学和代码指标上均有大幅提高,将Llama-3.1-8B的性能拉到同生态位SOTA(超越Qwen-2.5-7B instruct)。同时,8B的Skywork o1 Open也解锁了很多较大量级模型,如GPT 4o,无法完成的数学推理任务(如24点计算)。这也为推理模型在轻量级设备上部署提供了可能性。


同时,我们也将开源两个推理任务的Process Reward Model(PRM):Skywork o1 Open-PRM-1.5B 和Skywork o1 Open-PRM-7B,相比此前开源的Skywork-Reward-Model仅对整个模型回答进行打分,Skywork o1 Open-PRM能给模型回答中的每个步骤进行打分。
对比开源社区现有的PRM,Skywork o1 Open-PRM-1.5B能达到开源社区8B的模型效果,例如RLHFlow的Llama3.1-8B-PRM-Deepseek-Data,OpenR的Math-psa-7B,Skywork o1 Open-PRM-7B能同时在大部分benchamrk上接近/超过10倍量级的Qwen2.5-Math-RM-72B。Skywork o1 Open-PRM也是第一款适配代码类任务的开源PRM。下面表格为以Skywork-o1-Open-8B作为基础模型,使用不同PRM在数学和代码评测集上的评估结果。


除Skywork-o1-Open-PRM外,其他开源PRM均未针对代码类任务进行专门优化,故不进行代码任务的相关对比。
详细技术报告也将在不久后发布。目前模型和相关介绍在Huggingface开源(开源地址:https://tinyurl.com/skywork-o1)
强推理以及自我反思的能力是如何练成的?
Skywork o1在逻辑推理任务上性能的大幅提升得益于天工三阶段自研的训练方案:
1,推理反思能力训练:通过自研的多智能体体系构造高质量的分步思考,反思和验证数据。通过高质量的、多样性的长思考数据对基座模型进行继续预训练和监督微调。,
2,推理能力强化学习:团队研发了最新的适配分步推理强化的Skywork o1 Process Reward Model(PRM)。实验证明Skywork-PRM可有效的捕捉到复杂推理任务中间步骤和思考步骤对最终答案的影响。结合自研分步推理强化算法进一步加强模型推理和思考能力。
3,推理planning:基于天工自研的Q*线上推理算法配合模型在线思考,并寻找最佳推理路径。这也是全球首次将Q*算法实现和公开。Q*算法落地也大大提升了模型线上推理能力。
关于天工 Q*算法,更多详情可见:https://arxiv.org/abs/2406.14283
亮点功能与实测
Skywork o1模型具有以下能力和亮点功能:
1,模型思考和规划能力
2,模型自我反思能力
3,模型自我验证能力
相较于此前(长文本任务)大模型,无论是常识推理问题、逻辑推理问题、数学推理问题、伦理决策问题、还是“弱智”(类似脑筋急转弯)逻辑陷阱问题等,Skywork o1都处理的游刃有余。整体来说,Skywork o1 Lite和Skywork o1 Preview线上版本在复杂问题分析、思考反思过程、输出答案质量上均有大幅提升。
首先,我们拿一道「2024年全国硕士研究生入学统一考试数学(一)试题」考考它(如下图所示),测试一下它的“智力水平”。

面对难度不小的最新考研数学题,Skywork o1 Preview尽管花费了一些时间,但还是一步步推理出了正确结果。
那么,之前大模型经常翻车的比大小问题,Skywork o1现在的回答水平如何了?

从它的思考过程可以看出,Skywork o1的模型思考和规划能力大幅提升。这个解题逻辑非常像人类的思考方法了,“如果整数部分相同,那么就要开始比较小数部分了”。通过严谨的推理过程,准确得出8.8大于8.11,且多给出了一步差值计算。
此外,模型自我反思能力和自我验证能力也都有长足进步。Skywork o1可以准确识别出“nǐ hǎo hěn gāo xìng rèn shí nǐ”,还可以给出后续对话建议。


尽管我们让它回答存在中文读音“陷阱”的问题——“请将qíng rén yǎn lǐ chū xī shī转换为中文”,它也没有被我们绕进去。充分展示了中文逻辑问题思考中的反思能力,它主动发现了“西诗”是不对的说法,而是“西施”。
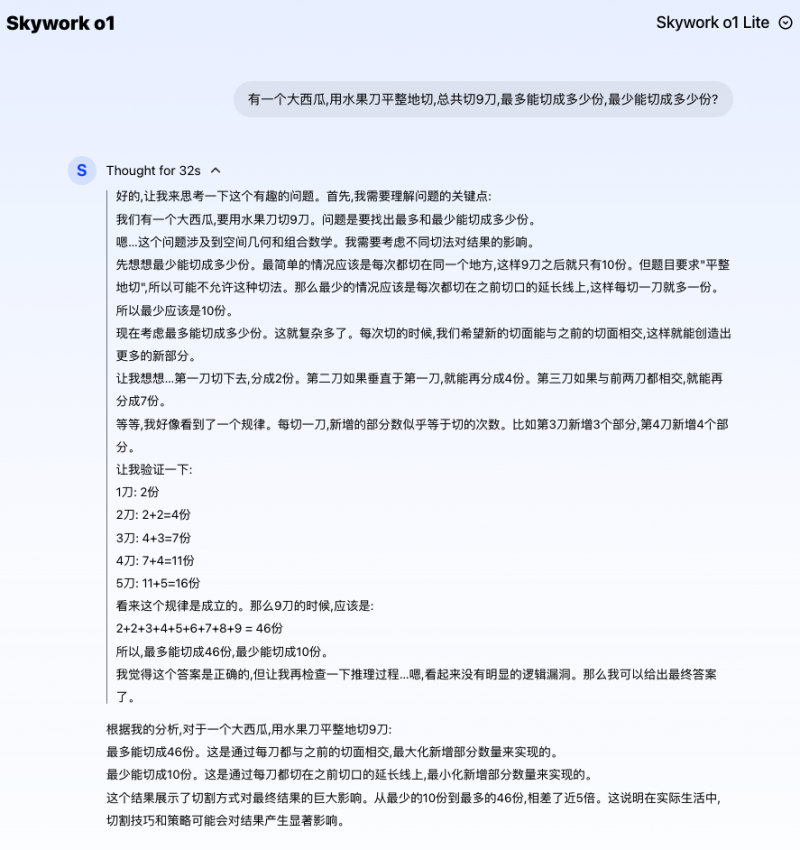
同样的,对于之前的大模型来说,“算24点”的游戏很容易把模型搞崩溃了,但是对于Skywork o1来说,可谓是小菜一碟。它不仅给出了正确答案,重点是它在过程中进行了「自我验证」。它在计算过后,又检查了一遍,确认过程和答案全部符合命题要求,才给出最终答案。

除了上述给出的数学推理、比大小、中文逻辑以及24点计算的任务外,Skywork o1在其他复杂的场景也有较好表现:
竞赛数学:Skywork o1拿到2024 AIME第一题(如下图所示),也从容应对。计算逻辑清晰、公式展示流畅,计算时长也明显具有优势。


密码解密:在复杂密码解密任务中,Skywork o1拥有强大的自我探索和推理能力。

在已知「原文→密文」的前提下,经过一系列复杂推理后成功给出答案(如下图所示)。
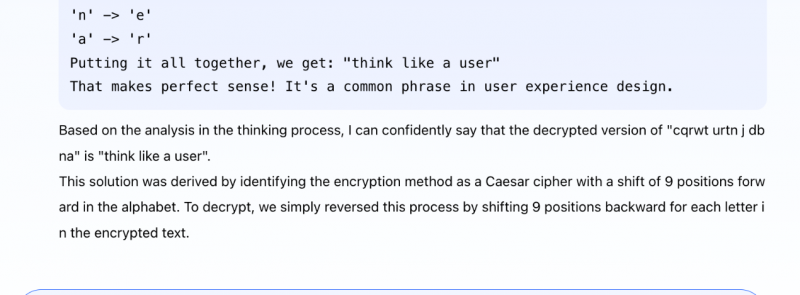
如果反过来呢?已知一段「密文→原文」,能否找出新密文所对应的原文。Skywork o1表示小菜一碟。

智力问答:在复杂的中文推理问题上,Skywork o1表现优异,并给出了完整的思考链路。

最后,再让我们再给他出一些有趣的“弱智”问题,来看看它的回答是不是合理。
1,为什么我爸妈结婚的时候没邀请我参加婚礼?
2,被门夹过的核桃,还能补脑吗?
3,午餐肉,我可以晚上吃吗?
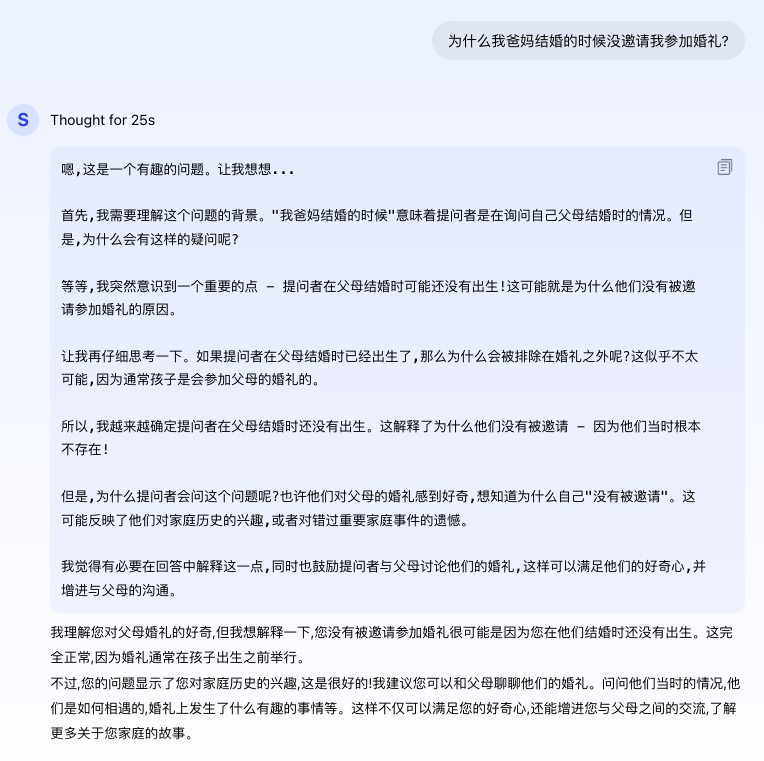


令人惊喜的是,Skywork o1不但没有被问题绕进去,还分析的头头是道,甚至透露出“大智慧”,引申出了一些更底层的思考。
进阶版的复杂人类思考能力的解锁也将进一步在垂类领域增强大模型的应用,例如:
1,中英文常见逻辑推理和复杂任务,如数学/代码类任务,科学研究
2,高质量内容生成,如创意写作,行业报告写作
3,深度搜索,解锁复杂搜索任务的拆解
2024年以来,昆仑万维天工AI持续进化,陆续发布了「天工2.0」、「天工3.0」、「天工大模型4.0」4o版——Skywork 4o,以及今天正式发布的「天工大模型4.0」 o1版(Skywork o1),不仅是我们贯彻“All in AGI 与 AIGC” 战略的重要举措,更是我们构建AI技术栈的重要一步。我们将秉持“实现通用人工智能,让每个人更好地塑造和表达自我”的使命,从模型层、应用层等全方位、多维度来构建公司技术竞争力和生态矩阵。
相关文章
- 昆仑万维旗下天工AI正式上线DeepSeek R1+联网搜索
- 昆仑万维「天工大模型4.0」o1版(Skywork o1)正式启动邀请测试
- 昆仑万维推出「天工大模型4.0」4o版(Skywork 4o),实时语音对话助手Skyo上线在即
- 昆仑万维重磅发布天工AI高级搜索功能,做最懂金融投资、科研学术的AI搜索
- AI视频ChatGPT时刻到来,昆仑万维发布全球首款AI短剧平台
- 全球首发!昆仑万维重磅推出AI流媒体音乐平台Melodio
- 拥抱国产大模型,云捷亮数AI产品全面迁移至昆仑万维天工开放平台
- 昆仑万维开源2千亿稀疏大模型天工MoE,全球首创能用4090推理
- 昆仑万维宣布天工AI每日活跃用户(DAU)超过100万
- 颜水成挂帅,昆仑万维2050全球研究院联合NUS、NTU发布Vitron,奠定通用视觉多模态大模型终极形态
- Suno V3引爆AI音乐产业链机遇 券商看好万兴科技昆仑万维等投资机会
- 昆仑万维旗下Opera全新AI服务器集群成功落地 大模型推理速度提高30倍
- 昆仑万维发布面向人工智能时代的六条人才宣言
- 昆仑万维天工大模型荣获第七届金璨奖“年度创新商业模式奖”
- 昆仑万维天工一刻 | 一文看懂图文多模态大模型
- 完美碰撞!云捷亮数携手昆仑万维开创公路旅行AI新篇章





