近3000道题,商汤大模型拿了金牌
2024-11-08 15:32:19爱云资讯阅读量:15,797
模型表现好,金牌少不了。
刚刚,中文大模型测评基准SuperCLUE发布《中文大模型基准测评2024年10月报告》:
商汤日日新·商量大模型(SenseChat5.5)凭借出色的能力表现,总得分位列国内大模型第一梯队,获得金牌。
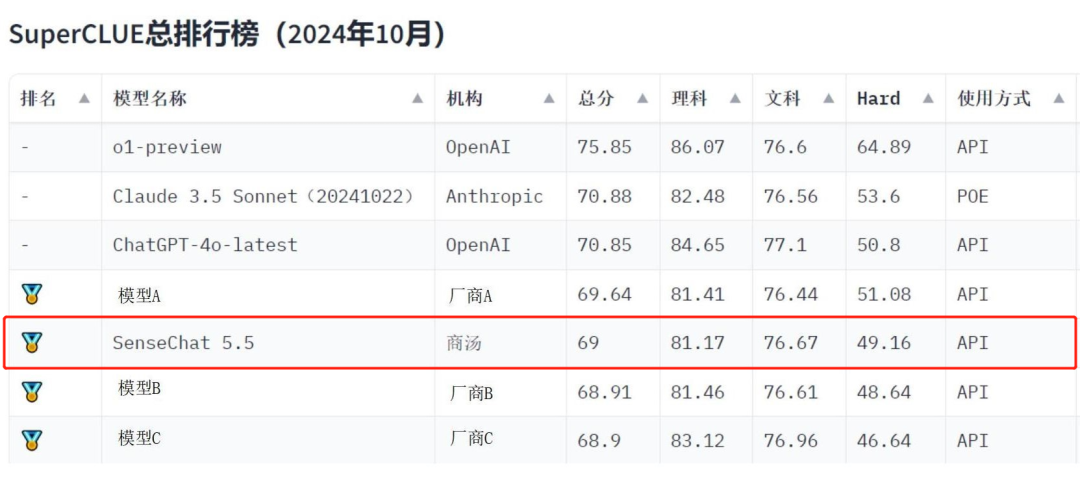
本次SuperCLUE10月报告覆盖23个国内模型,聚焦语言大模型的通用能力评估,分为三大维度:除了考察“文科”、“理科”基础能力外,还有考察模型更高阶能力的“Hard”附加任务,总共2900+道题:
【理科任务】分为计算、逻辑推理、代码、工具使用测评集;
【文科任务】分为知识百科、语言理解、长文本、角色扮演、生成与创作、安全六大测评集;
【Hard任务】分为精确指令遵循测评集,复杂任务高阶推理测评集。

商汤SenseChat5.5在多项评测任务中均位列第一梯队,文科中语言理解、安全等维度表现突出,也是理科中逻辑推理、代码学科的“尖子生”。
值得注意的是,在【Hard】的两项任务——精准指令遵循和高阶推理中,商汤SenseChat5.5是唯一两项任务均位于国内第一梯队的大模型,体现了模型优秀的复杂推理智能。
未来,商汤将继续坚持基础大模型的持续研发与投入,不断提升真正高阶推理及“慢思考”能力。
相关文章
- 提效30%,降本80%!商汤大模型让智慧园区效能倍增
- 商汤董事长兼CEO徐立受邀出席2024香港工商界人士座谈会
- 近3000道题,商汤大模型拿了金牌
- 211亿市场规模,商汤大装置位居前列
- 徐冰最新访谈:商汤最近在做什么,AI最大的新机遇在哪里
- 商汤科技与中智股份达成合作,AI大模型赋能人力资源能力跃迁
- 商汤科技十周年,徐立首提 AI 2.0时代核心战略
- 商汤又“夺金”!SuperCLUE-V多模态大模型基准发布10月榜单
- 商汤元萝卜发布AI下棋机器人四合一启蒙版,象棋、围棋、国际象棋、五子棋任意下
- 商汤科技亮相2024中国算力大会,携手联通共推AI基础设施建设
- 商汤如影联手新东方国际教育,“留子们”的数字人老师来啦!
- 百年投资管理公司OMAI组团到访商汤科技,点赞「日日新」
- 商汤临港AIDC获评全国首个5A级智算中心
- 首批通过!商汤科技金融智脑FinAgent通过可信AI金融智能体评估,获当前最高评级
- 沙利文权威报告:「商汤小浣熊」,百亿级中国AI代码生成市场竞争力第一 !
- 商汤大装置昇腾原生开发实践:集群规模扩展至3倍,线性加速比超97%





