Adobe进军生成式人工智能视频领域 推出文生视频AI模型
2024-10-15 06:46:32爱云资讯10026

(爱云资讯消息)Adobe公司正进军生成式AI视频领域。自今年年初以来,Adobe的Firefly视频模型就已开始预热,现在将在包括Premiere Pro在内的一些新工具中推出,使创作者能够扩展视频片段并从静止图像和文本提示中生成视频。
第一款工具是生成式延伸,现已在Premiere Pro中进行beta测试。它可以用于延长略短的镜头的结尾或开头,或者在拍摄过程中进行调整,比如纠正因眼神飘移或意外动作而产生的问题。
剪辑只能延长两秒钟,因此生成性扩展仅适用于小的调整,但它可以取代重新拍摄镜头以纠正细微问题的需要。扩展的剪辑可以以720p或1080p的分辨率和24帧每秒的帧率生成。它也可以用于音频,帮助平滑剪辑。比如它可以将音效和环境音延长至多10秒。
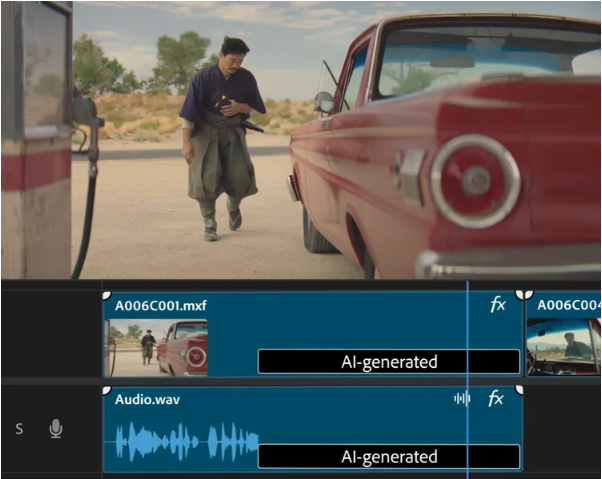
另有两款视频生成工具即将在网络上推出。Adobe的文本转视频和图片转视频工具于今年9月首次亮相,现已作为有限的公开测试版在Firefly网页应用中推出。
文本转视频的工作原理与Runway和OpenAI的Sora等其他视频生成器类似,用户只需将所需生成的内容的文本描述输入其中即可。它可以模拟各种风格,如常规的真实电影、3D动画和定格动画,生成的片段还可以通过一系列模拟摄像机控制的设置进一步细化,这些选项模拟了诸如摄像角度、运动和拍摄距离等元素。

图像转视频功能更进一步,让用户在文本提示旁边添加参考图像,以更好地控制生成的结果。Adobe建议该功能可用于从图像和照片中生成备播片段,或通过上传现有视频中的静帧来帮助可视化重拍场景。然而,下图的前后对比显示,该功能实际上并不能直接替代重拍,因为在生成的结果中可以看到一些错误,如晃动的电缆和移动的背景等。

短期内也不可能用这项技术来制作完整的电影。目前,文本转视频和图片转视频的片段的最大长度为5秒,画质最高为720p和24帧每秒。相比之下,OpenAI表示Sora可以生成长达一分钟的视频同时保持视觉质量和遵循用户的提示,但这一功能虽然在几个月前就已宣布,但目前尚未对公众开放,比Adobe的工具晚了几个月。

文本转视频、图像转视频和生成式延伸功能都需要大约90秒的时间来生成,但Adobe表示正在开发加速模式来缩短这一时间。尽管目前存在局限,但Adobe表示其基于AI视频模型的工具在商业上是安全的,因为它们是基于创意软件巨头被允许使用的内容进行训练的。考虑到其他供应商如Runway的模型被指控训练数据来自数千个从YouTube上抓取的视频,对于某些用户来说,商业可行性可能是决定性的因素。
另一个好处是,使用Adobe的Firefly视频模型创建或编辑的视频可以嵌入Content Credentials,以帮助在发布到网上时披露AI的使用情况和所有权权利。目前这些工具还处于测试阶段,但至少它们已向公众开放——这比我们能对Open AI的Sora、Meta的Movie Gen和谷歌的Veo生成器说的要多。
Adobe在Adobe MAX大会上宣布了AI视频发布功能,还在其创意应用程序中推出了一系列基于AI的功能。
相关文章
- 2025中关村论坛丨百度王海峰:看到通用人工智能曙光
- 2025中国互联网科技大会暨中国人工智能应用发展大会在北京隆重启动
- 引领人工智能时代,天翼云息壤智算一体机获信通院权威认证
- 共筑AI产业新未来 2025人工智能基础设施峰会成功召开
- 全球AI巅峰盛会!2025 AGIC深圳(国际)通用人工智能大会暨产业博览会正式启航!
- 为国产化服务,为经开区赋能——国产化算力筑基人工智能之城
- 微软推出具备深度推理能力的Copilot人工智能助手
- 智启未来,共筑南海人工智能新高地 | 科大讯飞佛山人工智能产业基地正式成立
- 践行“人工智能+”行动 《北京新闻》聚焦四维图新地图众源更新创新应用
- 广州市委书记郭永航莅临钛动科技,深入调研“人工智能+出海营销”赋能中国企业全球化
- 苹果调整人工智能部门高管层 Vision Pro负责人接管Siri
- 金山云Q4 AI收入同比增长近500% 人工智能收入占比处行业领先地位
- 从“政务助手”到“故障预言家”,人工智能可以赋能哪些场景?
- 人民出行首批入选广西人工智能垂直模型,以科技投入带领行业前行
- 英矽智能完成1.1亿美元E轮融资,加速人工智能与机器人驱动的药物研发创新
- 人工智能+行动深化 第一线DYXnet私域DeepSeek方案助构AI智能体





