源2.0-M32大模型发布量化版 运行显存仅需23GB 性能可媲美LLaMA3
2024-08-26 17:15:26爱云资讯153029
源2.0-M32量化版是"源"大模型团队为进一步提高模算效率,降低大模型部署运行的计算资源要求而推出的版本,通过采用领先的量化技术,将原模型精度量化至int4和int8级别,并保持模型性能基本不变。源2.0-M32量化版提高了模型部署加载速度和多线程推理效率,在不同硬件和软件环境中均能高效运行,降低了模型移植和部署门槛,让用户使用更少的计算资源,就能获取源2.0-M32大模型的强大能力。
源2.0-M32大模型是浪潮信息"源2.0"系列大模型的最新版本,其创新性地提出和采用了"基于注意力机制的门控网络"技术,构建包含32个专家(Expert)的混合专家模型(MoE),模型运行时激活参数为37亿,在业界主流基准评测中性能全面对标700亿参数的LLaMA3开源大模型,大幅提升了模型算力效率。
模型量化(Model Quantization)是优化大模型推理的一种主流技术,它显著减少了模型的内存占用和计算资源消耗,从而加速推理过程。然而,模型量化可能会影响模型的性能。如何在压缩模型的同时维持其精度,是量化技术面临的核心挑战。
源2.0-M32大模型研发团队深入分析当前主流的量化方案,综合评估模型压缩效果和精度损失表现,最终采用了GPTQ量化方法,并采用AutoGPTQ作为量化框架。为了确保模型精度最大化,一方面定制化适配了适合源2.0-M32结构的算子,提高了模型的部署加载速度和多线程推理效率,实现高并发推理;另一方面对需要量化的中间层(inter_layers)进行了严格评估和筛选,确定了最佳的量化层。从而成功将模型精度量化至int4和int8级别,在模型精度几乎无损的前提下,提升模型压缩效果、增加推理吞吐量和降低计算成本,使其更易于部署到移动设备和边缘设备上。
评测结果显示,源2.0-M32量化版在多个业界主流的评测任务中性能表现突出,特别是在MATH(数学竞赛)、ARC-C(科学推理)任务中,比肩拥有700亿参数的LLaMA3大模型。
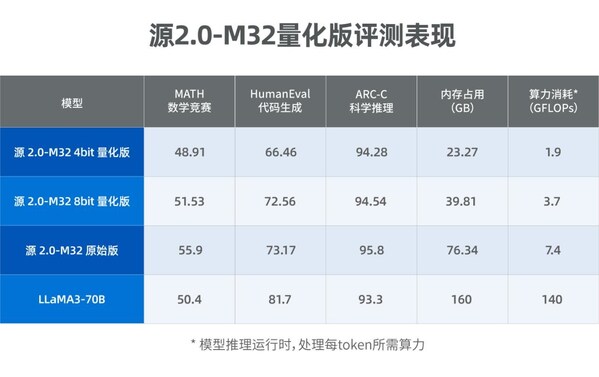
总之,源2.0-M32大模型量化版在保持推理性能的前提下,显著降低了计算资源消耗和内存占用,其采用的GPTQ量化方法通过精细调整,成功将模型适配至int4和int8精度级别。通过定制化算子优化,源2.0-M32量化版实现了模型结构的深度适配和性能的显著提升,确保在不同硬件和软件环境中均能高效运行。未来,随着量化技术的进一步优化和应用场景的拓展,源2.0-M32量化版有望在移动设备和边缘计算等领域发挥更广泛的作用,为用户提供更高效的智能服务。
相关文章
- 联通数科“同舟AI+”:加速大模型落地应用
- 垂类模型接入智能终端 易车蓝图大模型与荣耀YOYO达成战略合作
- 易车蓝图大模型加入荣耀YOYO生态 融合进阶“智能革命”时代
- 鼎捷携手DeepSeek大模型,开启中国制造业AI智慧化新时代
- 率先接入DeepSeek V3最新版!腾讯云大模型知识引擎高效搭建金融AI应用
- 中国AI再出王炸!全球首个音乐推理大模型Mureka O1上线,硅谷彻底碎了
- 腾讯云x DeepSeek:率先上线最新版V3模型API接口、大模型知识引擎内置新模型服务
- 百度发布文心4.5与X1大模型,微美全息软硬协同算力生态树立AI典范
- 宇视发布大模型交通事件检测相机,让道路拥有会思考的眼睛
- 第一线DYXnet协同华为构建AI算网 加速企业大模型私域部署
- AI把脉精准捕捉熬夜信号!知医邦ChatiSS查体大模型助力基层诊疗
- 全球领先宠物医疗AI大模型Vet1正式发布,推动宠物行业智能化变革
- 华为软件应用市场发布:循环智能核心大模型应用产品正式上架授牌
- 把误报降下来!宇视大模型精准打击矿山盗采
- 突破复杂版面及图表解析难题,合合信息“大模型加速器”再升级
- 润和软件亮相华为中国合作伙伴大会2025,发布DeepSeek一体机,引领行业大模型敏捷落地





