国产大模型超越Llama3!岩芯数智RockAI重新定义端侧智能
2024-08-20 14:25:22爱云资讯5923
8月18-19日,AICon全球人工智能开发与应用大会在上海举办,以“智能未来,探索 AI 无限可能”为主题,聚焦大模型开发与应用领域。RockAI CEO刘凡平应邀出席并发表《非Transformer架构的端侧大模型创新研究与应用》主题演讲,重新定义端侧智能,引发了行业对端侧AI落地方向的全新思考。
众所周知,端侧AI通常指在终端设备上直接运行和处理人工智能算法的技术,具有减少云端算力依赖、保证用户数据安全等优势。目前,行业普遍将算力限制和数据匮乏视同端侧AI技术发展的拦路虎。而RockAI则认为,基础架构和核心算法的创新才是突破端侧AI发展局限的关键。基于对算法和架构的创新,即使面临算力限制,端侧AI仍可在终端设备上实现流畅的智能多模态运用。
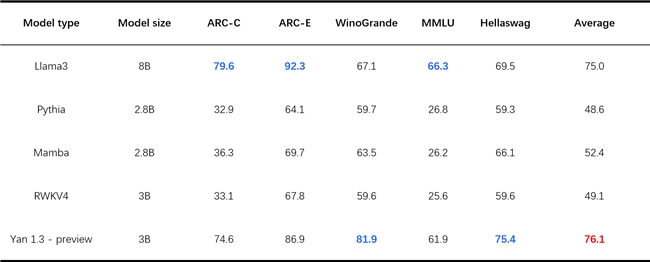
这一观点也在RockAI关于Yan架构大模型的创新实践上得到了证明。其推出的国内首个非Attention机制的Yan架构大模型,可在主流消费级CPU等端侧设备上无损运行,达到其他模型GPU上的运行效果。全面升级后,Yan1.2多模态大模型,已经可以在树莓派、机器人、手机等低功耗计算平台无损流畅运行,将端侧应用场景拓宽至智能家居、物联网等领域。而最新数据显示,3B参数的Yan1.3 preview大模型在各项测评中的平均得分甚至超越了8B参数的Llama3,达到极高的知识密度。
论坛现场,刘凡平深入剖析了当前端侧AI技术的发展现状及局限性。他指出,目前大多数“狭义端侧模型”的核心目标在于为用户提供大语言模型推理服务,受限于模型参数、算力、软件生态、功耗控制等诸多难题,往往会通过压缩、分割等软硬件协同优化实现大语言模型在终端设备上的本地化应用。但端侧AI的未来不仅仅在于推理能力的提升,更在于能够实现模型的自我学习和优化,以适应不断变化的应用场景和愈发广阔的用户需求。而通过以上处理手段,模型是无法在端侧进行训练和微调的,更不必说实现自我学习。
刘凡平强调,RockAI不做“狭义的端侧模型”,而是着眼于更广泛意义上的端侧智能,即让世界上每一台设备都拥有自己的智能。这要求端侧模型除了语言理解及生成能力外,还应该具备抽象思考、因果推理、自我反思以及跨领域迁移学习等更复杂的认知功能。因此,端侧模型需要至少支持“理解表达、选择遗忘、持续学习”三种基础能力。
为达成这一目标,RockAI在基础架构创新和实现消费级终端无损部署外,首创了“同步学习”机制。该机制可以使大模型在推理的同时进行知识更新和学习,建立自己独有的知识体系,实现模型的边跑边进化。同时,通过跨模态关联学习,增强模型在多场景下的应用能力,实现秒级实时反馈的人机交互,真正做到端侧模型的自我学习、类人感知和实时交互,推动端侧AI向自适应智能进化阶段演进。
RockAI基于Yan架构大模型的技术突破和创新实践,打破了当前端侧AI发展的技术壁垒,不仅为整个行业的发展提供了新的思路和方向,也预示着端侧AI正朝着更广泛的应用场景稳步前进。待同步学习+全模态+实时人机交互落地后,Yan2.0的诞生将重新定义端侧智能,真正赋予机器自主学习与自我优化能力,构建持续进化乃至群体智能涌现的AGI智慧生态。





