实践分享:青云科技KubeSphere 上部署 AI 大模型管理工具 Ollama
2024-07-11 11:18:57爱云资讯19116
随着人工智能、机器学习、AI 大模型技术的迅猛发展,我们对计算资源的需求也在不断攀升。特别是对于需要处理大规模数据和复杂算法的 AI 大模型,GPU 资源的使用变得至关重要。对于运维工程师而言,掌握如何在 Kubernetes 集群上管理和配置 GPU 资源,以及如何高效部署依赖这些资源的应用,已成为一项不可或缺的技能。
今天,我将带领大家深入了解如何在 KubeSphere 平台上,利用 Kubernetes 强大的生态和工具,实现 GPU 资源的管理和应用部署。以下是本文将要探讨的三个核心主题:
1.集群扩容与GPU节点集成:我们将通过 KubeKey 工具,扩展 Kubernetes 集群并增加具备 GPU 能力的 Worker 节点,为 AI 应用提供必要的硬件支持。
2.GPU资源的Kubernetes集成:使用 Helm 安装和配置 NVIDIA GPU Operator,这是 NVIDIA 官方提供的一个解决方案,旨在简化 Kubernetes 集群中 GPU 资源的调用和管理。
3.实战部署:Ollama大模型管理工具:我们将在 KubeSphere 上部署 Ollama,一个专为 AI 大模型设计的管理工具,以验证 GPU 资源是否能够被正确调度和高效使用。
通过阅读本文,您将获得 Kubernetes 上 管理 GPU 资源的知识和技巧,帮助您在云原生环境中,充分利用 GPU 资源,推动 AI 应用的快速发展。
KubeSphere最佳实战「2024」系列文档的实验环境硬件配置和软件信息如下:
实战服务器配置(架构1:1复刻小规模生产环境,配置略有不同)
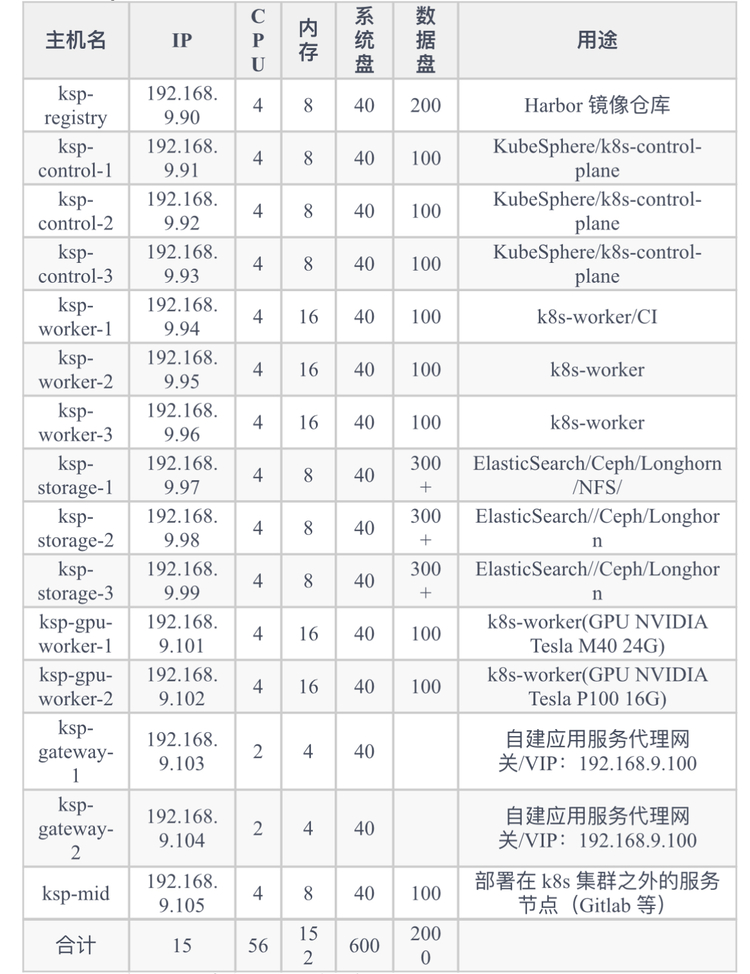
实战环境涉及软件版本信息
操作系统:openEuler22.03 LTS SP3 x86_64
KubeSphere:v3.4.1
Kubernetes:v1.28.8
KubeKey:v3.1.1
Containerd:1.7.13
NVIDIA GPU Operator:v24.3.0
NVIDIA 显卡驱动:550.54.15
1. 前置条件
1.1 准备带有显卡的 Worker 节点
鉴于资源和成本的限制,我没有高端物理主机和显卡来做实验。只能增加两台配备入门级 GPU 显卡的虚拟机,作为集群的 Worker 节点。
节点 1,配置 GPU NVIDIA Tesla M40 24G 显卡。唯一优点 24G 大显存,性能低。
节点 2,配置 GPU NVIDIA Tesla P100 16G 显卡。显存小,但是速度快于 M40、P40 等显卡。
尽管这些显卡在性能上不及高端型号,但它们足以应对大多数学习和开发任务,在资源有限的情况下,这样的配置为我提供了宝贵的实践机会,让我能够深入探索 Kubernetes 集群中 GPU 资源的管理和调度策略。
1.2 操作系统初始化配置
请参考Kubernetes集群节点openEuler22.03 LTS SP3系统初始化指南,完成操作系统初始化配置。
初始化配置指南中没有涉及操作系统升级的任务,在能联网的环境初始化系统的时候一定要升级操作系统,然后重启节点。
2. 使用 KubeKey 扩容 GPU Worker 节点
接下来我们使用 KubeKey 将新增加的 GPU 节点加入到已有的 Kubernetes 集群,参考官方说明文档,整个过程比较简单,仅需两步。
修改 KubeKey 部署时使用的集群配置文件
执行增加节点的命令
2.1 修改集群配置文件
在 Control-1 节点,切换到部署用的 kubekey 目录,修改原有的集群配置文件,我们实战中使用的名字为ksp-v341-v1288.yaml,请根据实际情况修改 。
主要修改点:
spec.hosts 部分:增加新的 worker 节点的信息。
spec.roleGroups.worker 部分:增加新的 worker 节点的信息
修改后的示例如下:
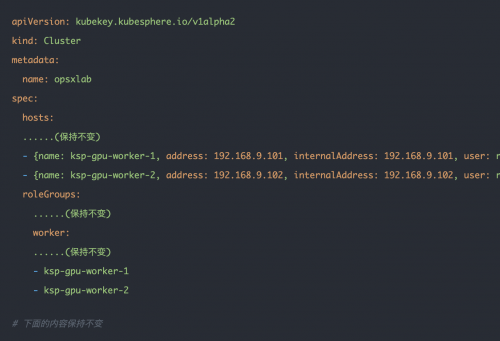
2.2 使用 KubeKey 增加节点
在增加节点之前,我们再确认一下当前集群的节点信息。
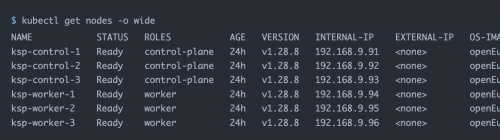
接下来我们执行下面的命令,使用修改后的配置文件将新增的 Worker 节点加入集群。

上面的命令执行后,KubeKey 先检查部署 Kubernetes 的依赖及其它配置是否符合要求。通过检查后,系统将提示您确认安装。输入yes并按 ENTER 继续部署。
部署完成需要大约 5 分钟左右,具体时间看网速、机器配置、增加的节点数量。
部署完成后,您应该会在终端上看到类似于下面的输出。

3. 扩容后集群状态验证
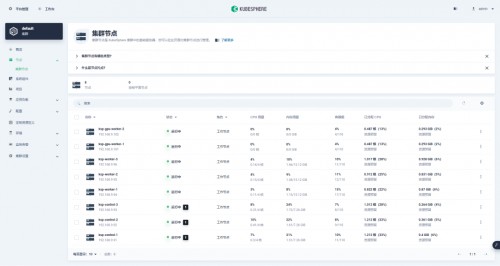
3.1 KubeSphere 管理控制台验证集群状态
我们打开浏览器访问 Control-1 节点的 IP 地址和端口30880,登陆 青云科技KubeSphere 管理控制台的登录页面。
进入集群管理界面,单击左侧「节点」菜单,点击「集群节点」查看 Kubernetes 集群可用节点的详细信息。
3.2 Kubectl 命令行验证集群状态
查看集群节点信息
在 Control-1 节点运行 kubectl 命令获取 Kubernetes 集群的节点信息。

在输出结果中可以看到,当前的 Kubernetes 集群有 8 个节点,并详细展示每个节点的名字、状态、角色、存活时间、Kubernetes 版本号、内部 IP、操作系统类型、内核版本和容器运行时等信息。

至此,我们完成了利用 Kubekey 在现有的 3 个 Master 节点和 3 个 Worker 节点组成的 Kubernetes 集群中增加 2 个 Worker 节点的全部任务。
接下来我们安装 NVIDIA 官方出品的 NVIDIA GPU Operator,实现 K8s 调度 Pod 使用 GPU 资源。
4. 安装配置 NVIDIA GPU Operator
4.1 安装 NVIDIA 显卡驱动
NVIDIA GPU Operator 支持自动安装显卡驱动,但是只 CentOS 7、8 和 Ubuntu 20.04、22.04 等版本,并不支持 openEuler,所以需要手工安装显卡驱动。
请参考KubeSphere最佳实战:openEuler22.03 LTS SP3安装NVIDIA显卡驱动,完成显卡驱动安装。
4.2 前提条件
Node Feature Discovery (NFD) 检测功能检查。

上面的命令执行结果为true, 说明NFD已经在集群中运行。如果 NFD 已经在集群中运行,那么在安装 Operator 时必须禁用部署 NFD。
❝
说明:使用 KubeSphere 部署的 K8s 集群默认不会安装配置 NFD。
4.3 安装 NVIDIA GPU Operator
1.添加 NVIDIA Helm repository

2.安装 GPU Operator
使用默认配置文件,禁用自动安装显卡驱动功能,安装 GPU Operator。

❝
注意: 由于安装的镜像比较大,所以初次安装过程中可能会出现超时的情形,请检查你的镜像是否成功拉取!可以考虑使用离线安装解决该类问题。
3.使用自定义 values 安装 GPU Operator(可选,离线或是自定义配置时使用)

正确执行输出结果如下:
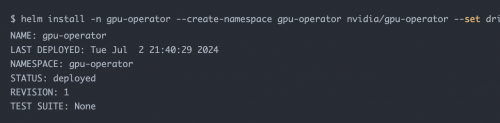
4.4 命令行检查 GPU Operator 部署状态
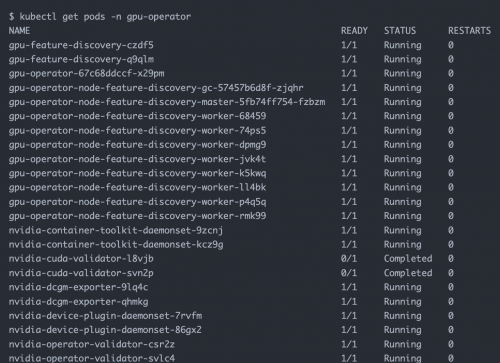
执行安装 GPU Operator 的命令后请耐心等待所有镜像成功拉取,所有 Pod 都处于 Running 状态。
1.命令行检查 pods 状态
查看节点可分配的 GPU 资源
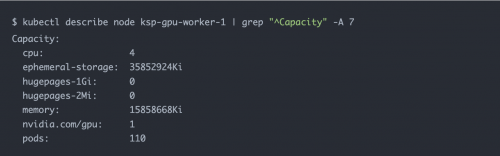
❝
说明:重点关注nvidia.gpu:字段的值。
4.5 KubeSphere 控制台查看 GPU Operator 部署状态
创建成功的工作负载如下:
Deployments
Daemonsets
5. GPU 功能验证测试
5.1 测试示例 1-验证测试 CUDA
GPU Operator 正确安装完成后,使用 CUDA 基础镜像,测试 K8s 是否能正确创建使用 GPU 资源的 Pod。
1.创建资源清单文件,vi cuda-ubuntu.yaml

2.创建资源

3.查看创建的资源
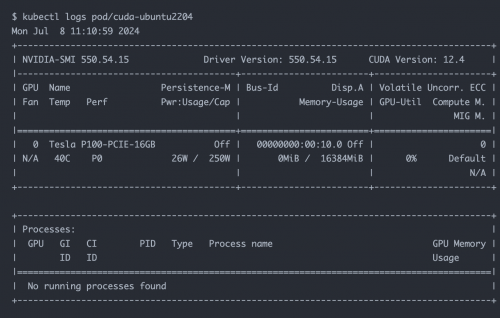
从结果中可以看到 pod 创建在了 ksp-gpu-worker-2 节点(该节点显卡型号 Tesla P100-PCIE-16GB)。

4.查看 Pod 日志

正确执行输出结果如下:
5.清理测试资源

5.2 测试示例 2-官方 GPU Applications 示例
执行一个简单的 CUDA 示例,用于将两个向量(vectors)相加。
1.创建资源清单文件,vi cuda-vectoradd.yaml

2.执行命令创建Pod

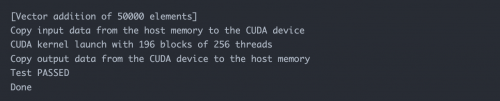
3.查看 Pod 执行结果
Pod 创建成功,启动后会运行vectorAdd命令并退出。

正确执行输出结果如下:
4.清理测试资源

6. KubeSphere 部署 Ollama
通过上面的验证测试,证明可以在 K8s 集群上创建使用 GPU 的 Pod 资源,接下来我们结合实际使用需求,利用 KubeSphere 在 K8s 集群创建一套大模型管理工具 Ollama。
6.1 创建部署资源清单
本示例属于简单测试,存储选择了hostPath模式,实际使用中请替换为存储类或是其他类型的持久化存储。
1.创建资源清单,vi deploy-ollama.yaml
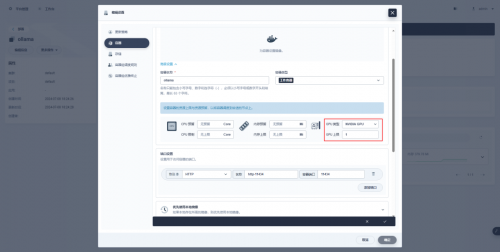
❝
特殊说明:KubeSphere 的管理控制台支持图形化配置 Deployment 等资源使用 GPU 资源,配置示例如下,感兴趣的朋友可以自行研究。

6.2 部署 Ollama 服务
创建 Ollama
查看 Pod 创建结果
从结果中可以看到 pod 创建在了 ksp-gpu-worker-1 节点(该节点显卡型号 Tesla M40 24GB)。
查看容器 log
6.3 拉取 Ollama 使用的大模型
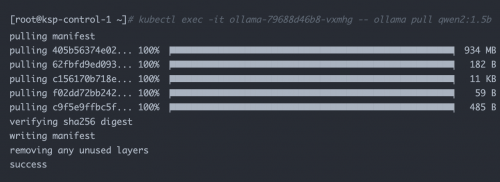
Ollama 拉取模型
本示例为了节省时间,采用阿里开源的 qwen2 1.5b 小尺寸模型作为测试模型。

正确执行输出结果如下:
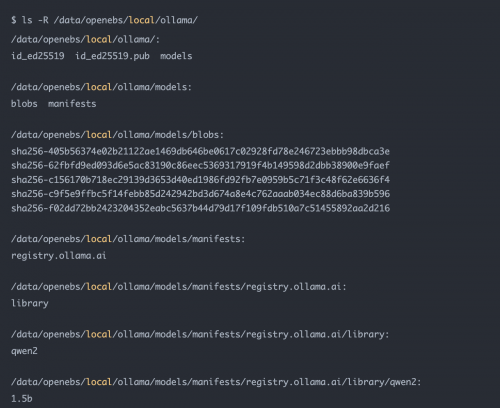
查看模型文件的内容
在ksp-gpu-worker-1节点执行下面的查看命令
6.4 模型能力测试
调用接口测试
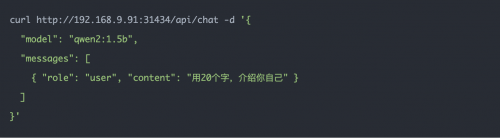
测试结果

6.5 查看 GPU 分配信息
查看 Worker 节点已分配的 GPU 资源

Ollama 运行时物理 GPU 使用情况
在 Worker 节点上执行nvidia-smi -l观察 GPU 的使用情况。
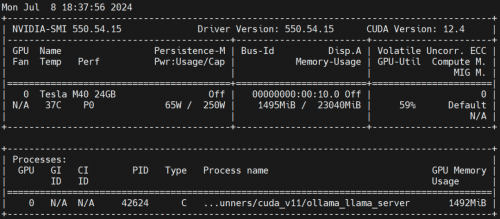
7. 自动化工具
文章中所有操作步骤,已全部编排为自动化脚本,包含以下内容(因篇幅限制,不在此文档中展示):
NVIDIA GPU Operator 离线部署配置文件
Ansible 自动化配置 GPU 节点
Ansible 自动化配置 K8s 集群节点
相关文章
- 青云科技 AI 应用开发平台开启公测,一站式构建企业级应用
- 接入DeepSeek大模型!青云科技助力鼎和保险的专属AI助手正式上线!
- 671B 满血 DeepSeek-R1 上线!青云科技一文教你如何创建自己的 AI 应用
- 青云科技参与北京市科委重点项目,助力京蒙算力智能调度
- 青云科技发布 2024 业绩预告,净利润增长 42.43%
- AI 时代,青云科技与曙光存储携手布局数据航海图
- 青云科技入选“新智榜单”——人工智能应用标杆 TOP100
- 青云科技作为重点厂商入选甲子光年《中国 AI 算力行业发展报告》
- 深度融合华为昇思,青云科技智算通过昇腾兼容性认证
- 青云科技获鲲鹏原生开发认证,共筑金融数字化基石
- 朝阳区金融服务矩阵发布,青云科技作为标杆企业受邀发言
- 青云科技陪伴人形机器人的 AI 训练之旅
- 青云科技加速人形机器人研发与部署落地
- “智算+超算”一套平台搞定!青云科技助力教学科研效率 10 倍提升
- 青云科技 × 摩尔线程,共筑国产 AI 算力新生态!
- 青云科技信创云完成与华为鲲鹏技术认证,助力国产数字化发展





