WAIC 2023 | 张俊林:大语言模型带来的交互方式变革
2024-07-04 15:05:04爱云资讯阅读量:441
7 月 8 日,在机器之心举办的 2023 WAIC AI 开发者论坛上,新浪微博新技术研发负责人张俊林先生发表了主题演讲《自然语言交互:大语言模型带来的交互方式变革》。在演讲中,他主要介绍了大型语言模型为人机交互方式带来的变革,其中的核心观点是:无论是人机交互还是 AI 之间的交互,都采用自然语言的方式,由此人操作数据的方式将变得更加简单与统一。而大语言模型处于人机交互的中心位置,复杂的中间过程将会隐藏到幕后,由语言模型通过 Planning+Programming 的方式解决。

以下为张俊林先生的演讲内容,机器之心进行了不改变原意的编辑。
现在国内外很多人都在做大模型;而做大模型考虑的核心问题有两个:
第一是基座大模型。打造功能强大的基座需要大量数据、算力和资金。尽管 ChatGPT 出来震惊了世界,但主要原因不在基座模型。强大的基座大模型不是在 ChatGPT 出现时横空出世的,而是慢慢发展起来的 —— 从 2020 年开始国外开发的模型规模逐步增大,效果也在逐渐变好,ChatGPT 的基座大模型可能相比之前效果有所提升,但并没有发生质的飞跃。所以 ChatGPT 影响力如此大的主要原因不是基座大模型。
第二是大模型的命令理解能力。如果要考虑 ChatGPT 为什么有这么大的影响力这个问题,主要原因在此。ChatGPT 做到了让大模型能够理解人的语言和命令,这个可能是最关键的因素,也是 ChatGPT 比过去大模型更加独特的地方。
有一句古诗特别适合形容大模型的这两个关键组件:「旧时王谢堂前燕,飞入寻常百姓家。」
「堂前燕」就是基座大模型,但是在 ChatGPT 时代之前,主要是研究人员在关注和改进。「飞向寻常百姓家」是指 RLHF,也就是 Instruct Learning(指示学习),是 RLHF 让我们所有人都能用自然语言和大模型进行交互。这样一来,每个人都能用它,每个人都能体会到它基座模型的强大能力。我认为这是 ChatGPT 可以引起这么大轰动的根本原因。
今天我要分享的主题是「自然语言交互」,我认为这可能是 ChatGPT 为主的大型语言模型(LLM)带给我们的最根本的变革。
传统人机交互方式
首先我们看一下传统的人机交互方式。

人机交互的本质是人和数据的关系问题。人在环境中进行一些行为,会产生各种类型的数据,这些数据可以分成两大类:一类是非结构化数据,如文本、图片、视频;另一类是结构化数据。企业可能更关注结构化数据,因为企业的内部数据很多都是以数据库或表格的形式存在的。人需要处理各种类型的数据,典型的行为比如创作、增、删、改、查等。
在大模型出来之前,人和数据怎么发生关系?人不能直接与数据发生关系,需要通过一个中介,这个中介就是应用软件。举个例子,即使你做最简单的文本编辑,你也需要一个文本编辑器,高级一点的文本处理工具就是 Word;要是做表格就需要 Excel,操作数据库就需要 MySQL,加工图像就需要 PhotoShop。
从这里可以看到传统交互方式的一个特点:处理不同类型的数据要用不同的应用软件,这是多样化的一种交互接口。另一个特点是传统交互方式很复杂繁琐,很多数据需要专业人士来处理。以处理图像为例,即使给你提供了 PhotoShop, 普通人可能也很难很好地处理图像,因为其中涉及到很复杂的操作,需要从多级菜单中找到自己想要的功能,只有经过训练的专业人士才能胜任。
总结起来,在大模型出现之前,我们和数据的关系以及交互方式是复杂繁琐且多样化的。
大模型时代的人机交互方式
大模型出现之后,情况发生了什么本质的变化呢?

其实关键的变化只有一个:大语言模型站到了人机交互的中心位置。
过去人是通过某个应用软件与某种数据交互,现在变成了人和大模型交互,而且方式很直接、很统一,就是自然语言。也就是说,如果你要做什么事,你就直接跟大模型说就行了。
其实这本质上还是人和数据的关系,只是由于大模型的出现,应用软件被屏蔽到了幕后。
再看看将来的发展趋势。短期来看,对于文本类或非结构化的数据,LLM 可以替代一些应用软件,比如多模态大模型对 PhotoShop 的取代。也就是说,LLM 可以自行完成一些常见任务,不再需要幕后应用的功能支持。目前来看多数结构化数据还是需要对应的管理软件,只是大模型走到前台了,管理软件被隐藏在后台。而如果把目光放得更长远一点,大模型可能会逐步替代各种功能软件,我们若干年以后再看,很可能只有中间的大模型了。
这就是有了大模型之后,人和数据的交互方式出现的根本性变化。这是非常重要的变化。
大模型时代的人机交互看起来非常简单,如果想做什么事,只需要说就行了,剩下的交给 LLM 去做。但背后的事实是怎样呢?

举个例子说明一下,苹果公司做的产品口碑特别好,为什么?是因为他们为用户提供了简单到极致的操作,而把复杂的部分都隐藏到了幕后。
大模型就和苹果公司做软件的思路类似。看起来 LLM 与人的交互模式很简单,但其实复杂的事情都是 LLM 在背后替用户做了。
LLM 需要做的复杂事情可分为三大类:
一、理解自然语言。目前大模型的语言理解能力很强,即使小规模的大模型,语言理解能力也非常强。
二、任务规划。对于复杂的任务,最好的解决方法是把它先拆成若干个简单任务,然后再逐个解决,一般这样效果才会好。这就是任务规划要负责的工作。
三、形式化语言。尽管人和机器交互用的是自然语言,但后续的数据处理一般需要用到形式化语言,比如 Programming(程序)、API、SQL、模块调用。形式有很多,但归根结底都是 Programming,因为 API 本质上就是函数调用外部工具,SQL 是一种特殊的程序语言,模块调用其实就是 API。我相信随着大模型往后发展,其内部的形式化语言很可能会统一成 Programming 的逻辑。也就是说,复杂任务在规划成更简单的子任务后,每个子任务解决方案的外在形式往往是 Programming 或 API 调用这种形式。
下面我们看看针对不同类型的数据,在大模型时代,人和数据是怎么交互的?文本类的就无需多提了,ChatGPT 就是典型。
使用自然语言操作非结构化数据
我们从非结构化的数据说起,首先是图片。
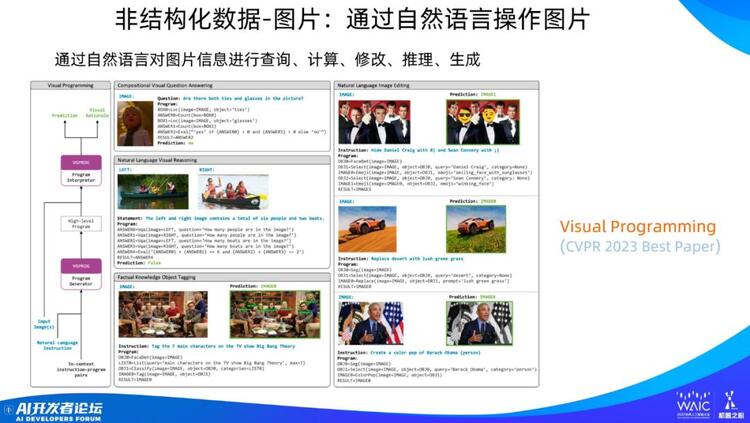
如图所示,这是典型的 Planning+Programming 模式,可以充分说明上面提到大模型在幕后做的三件事。在这个例子中,人通过语言来操作图片,包括增删改查等等。这个工作叫 Visual Programming,获得了 CVPR 2023 的最佳论文奖。
以图中下方《生活大爆炸》的剧照为例。用户提交了一张合影照片,并给大模型提出了一个任务:「在图片上标记电视剧《生活大爆炸》中 7 个主角的名字」
LLM 怎么完成这个任务呢?首先,LLM 将这个任务映射成程序语句(下面五行)。为什么有五行?这就是 Planning,每一行都是一个子任务,按顺序执行。
简单解释一下每行程序的含义:第一句程序语句的含义是把这张图片中的人脸识别出来;第二句是让语言模型发出一个查询,找到《生活大爆炸》主角的名字;第三句是让模型把人脸和人名对应起来,这是分类任务;第四句是让模型把图片里的人脸框出来,并且打上名字。第五句输出编辑好的图片。
可以看到,这个过程中包含 Planning 和 Programming,它们两位一体,集成在一起,不太容易看到 Planning 这一步,其实是有的。
对于视频也是类似。给你一段视频,你可以用自然语句问问题,比如:「这个视频里面这个人在干嘛?」
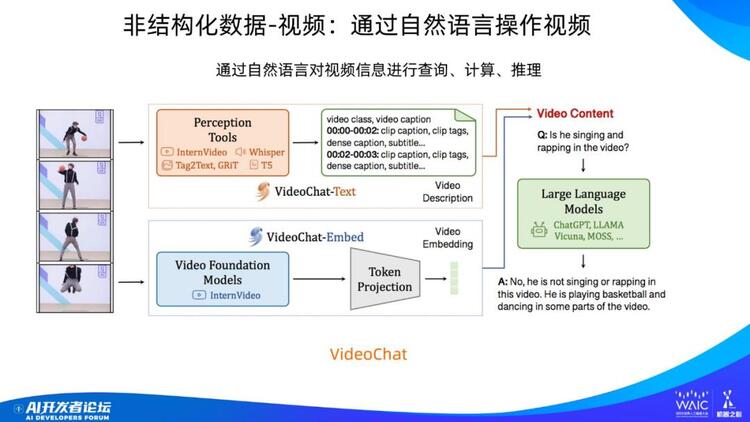
当然,这个任务本质上是一个多模态任务。可以看到,模型首先要对视频进行编码,图中上方是编码文本信息,下方是编码视觉信息。其中文本来自于语音识别。所以这是集成了文本和图片的模型,尽管图里没有画出来,但其内部同样会做各种规划以及推理。
这里跑题一下,我谈谈对多模态大模型的看法。现在大家普遍看好多模态方向,但我个人对多模态大模型的发展没有大多数人那么乐观。原因很简单:虽然现在很多同时处理文本和图像的模型效果还可以,但究其原因,并不是图像或视频技术获得了突破,而是文本模型能力太强,是它带着图像模型在飞。也就是说,从技术能力上讲,文本和图像模型并不对等,而是文强图弱,以文补图。实际上现在图像和视频方面还有严重的技术障碍没有突破。在图像处理上方盘旋着一朵 “技术乌云”,如果无法突破,多模态就面临着阴影和极大障碍,在应用方面很难取得重大进展。
使用自然语言操作结构化数据
下面来看结构化数据,这类数据包含三类典型:表格、SQL、知识图谱。
首先来看表格。我们能够通过自然语言操作表格数据,微软的 Office Copilot 已经做到了。问题是怎么做到的?当然我们不知道微软到底是怎么做的,但其他研究者也有类似的研究工作。

这里看个例子。对于一张销售数据表,其中有很多列,列和列之间的数据有关系,比如一列是销量、一列是单价、一列是销售额。LLM 能很好地处理表格,因为 LLM 在预训练模型里面学到很多知识,比如销售额 = 单价 × 销量。LLM 能够利用学到的知识来处理表格数据。
对于这张销售数据表,用户可以发出一个查询:「把销售额在 200-500 之间的记录点亮。」
LLM(这里是 GPT-4)首先会把这个任务规划成子任务,这里是三个子任务:1)先筛选出销售额在 200-500 之间的条目;2)把背景点亮成蓝色;3)把点亮的数据嵌入回表格。
对于第一步的筛选过程,模型是怎么做的呢?这里简单介绍一下这个流程。首先是写 prompt。图中可以看到,这个 prompt 特别长。
现在写 prompt 已经成为一门学问。有人说 prompt 就像是念咒语,我认为这更像是给大模型做 PUA。我们可以把大模型比作能扮演各种不同类型角色的人,为了让它做好当前的任务,我们需要把它调整为最适合做这个任务的角色。为此,我们需要写 prompt 把这个角色诱导出来:「你是很博学的,你特别适合干这个事儿,你应该干的更专业点,不要太随意。」。诸如此类。
然后再把表格的 schema(即表格每一列的含义)告诉它。GPT-4 就会生成一个 API,这个 API 是一个过滤器,可从所有数据中过滤出满足 200-500 的数据。但看标红的地方,模型在生成 API 时参数写错了。这时候怎么办?我们可以给它一些文档,让 GPT-4 学习,文档中有很多例子告诉它这种情况应该怎么调用 API 和写参数。GPT-4 看完之后,就把 API 改了一下,就改对了。
然后就是执行,就筛选出所需数据。
另一种结构化数据是数据库。我们的目的是用自然语言操作数据库,本质上就是将人的自然语言映射成 SQL 语句。

举个例子,这是谷歌的 SQL-PaLM,基于 PaLM 2。PaLM 2 是谷歌 4 月份重新训练的一个基座大模型,是为了对标 GPT-4 做的。
SQL-PaLM 操作数据库的方式有两种。一是在上下文学习(in-context learning), 也就是给模型一些例子,包括数据库的 schema、自然语言的问题和对应的 SQL 语句,然后再问几个新问题,要求模型输出 SQL 语句。另一种方式是微调(fine-tuning)。
现在这个模型的表现如何呢?在比较复杂的数据库表上,其准确率为 78%,已经接近实用化水准了。这意味着随着技术的进一步快速发展,很可能 SQL 语句不需要人写了;未来你说话把要啥说清楚就行,剩下的交给机器做就可以了。
另一个典型的结构化数据是知识图谱。问题还是一样:我们怎样用自然语言操作知识图谱?

这里用户提出一个问题:「奥巴马是哪个国家的?」大语言模型怎么给出答案的?它一样会进行规划,把任务拆成知识图谱可操作的 API;这会查询得到两个子知识,再去做推理,就能输出正确答案「美国」。
大模型和环境的关系
上面讲的是人和数据的关系,另外还有大模型和环境的关系。最典型的是机器人,现在一般叫具身智能,也就是说怎么给机器人以大脑,让机器人在世界里游走。

具身智能有五个核心要素:理解语言、任务规划、身体执行动作、接受环境反馈、从反馈中学习。
大模型阶段的具身智能和之前最大的不同是这五个环节的核心现在都可由大模型接管。如果你要指挥机器人,只需用自然语言发出需求即可,所有这五个步骤都由大模型去规划与控制。大模型可以给机器人一个强大的大脑,更好理解人类的语言与命令,使用大模型学到的世界知识指导行为,在这些方面比以前的方法有质的提升。
但是有一个问题:很多研究人员并不看好这个方向。原因是什么?如果你要用实体机器人在现实生活中学习锻炼,会面临成本高、数据获取效率低的问题,因为实体机器人非常贵,在真实世界里行动范围有限,获取数据的效率非常低,学习的速度就慢,而且还不能摔倒,因为摔倒意味着很大一笔维修费。
更多人的做法是创造一个虚拟环境,让机器人在虚拟环境中探索。虚拟环境能缓解成本高、数据获取效率低的问题。《我的世界》就是一个常用的虚拟环境。这是一个开放世界,类似于荒野求生,游戏角色在里面学会更好地生存就行了,所以特别适合用来代替机器人在真实世界的活动。

虚拟环境的成本非常低,数据获取效率非常高。但也有问题:虚拟世界的复杂性远远比不上真实世界。
英伟达开发的 Voyager 就是让机器人在《我的世界》里对陌生环境进行探索,它背后起到最主要驱动作用的大模型也是基于 GPT-4,机器人和 GPT-4 之间也是通过自然语言进行交流。图中左侧可以看到,模型会循序渐进、由易到难地学做各种不同任务难度的事,从最简单的伐木到后面做桌子、打僵尸等,一般机器学习语境下,我们把这种 “由易到难、循序渐进” 的学习模式叫做 “课程学习”。而 “课程学习” 这些任务都是由 GPT-4 根据当前状态产生的,你只要在 prompt 里 PUA 大模型让它由易到难地产生下一步任务就行了。
假设现在的任务是打僵尸。面对这个任务,GPT-4 会自动生成能在《我的世界》环境下运行的对应的 “打僵尸” 的函数及程序代码,在写这个函数的时候,可以复用解决之前比较简单任务时形成的工具,比如角色之前学会制作的石剑和盾牌,此时把这些工具通过 API 函数调用来直接使用。形成 “打僵尸” 函数后,可以执行代码来和环境交互,如果发生错误,把错误信息反馈给 GPT-4,GPT-4 就会进一步修正程序。假如程序执行成功,那么这些经验就会作为一个新的知识放到工具库里面,下一次还能用。之后依据 “课程学习”,GPT-4 会产生下一个更有难度的任务。
未来的大模型
上面是从人和数据的关系,以及大模型和环境的关系角度,来说明自然语言交互无处不在。接下来,我们看下自然语言交互在 AI 和 AI 交互过程中是如何发挥作用的。

最近大半年基座大模型方面有什么值得关注的研究进展?除了模型规模在继续变大,总体而言进展不太大,大部分新进展集中在 instruct 部分,这得益于 Meta 开源的 LLaMA 模型。要说基座模型的进展,我认为值得关注的有两个,一是模型输入窗口长度的快速增长,这块技术进展非常快,目前看开源模型 100K 长度甚至更长的输入很快能够达到;二是大模型增强。
我相信未来大模型大概率会是上图这个模式。之前的大模型是静态的单个大模型,将来的应该是由多个不同角色的智能体(agent)构成的大模型,它们之间通过自然语言进行通讯与交流,一起联合起来做任务。智能体还可以通过自然语言接口调用外部工具解决现有大模型的缺点,比如数据过时、幻觉严重、计算能力弱等。
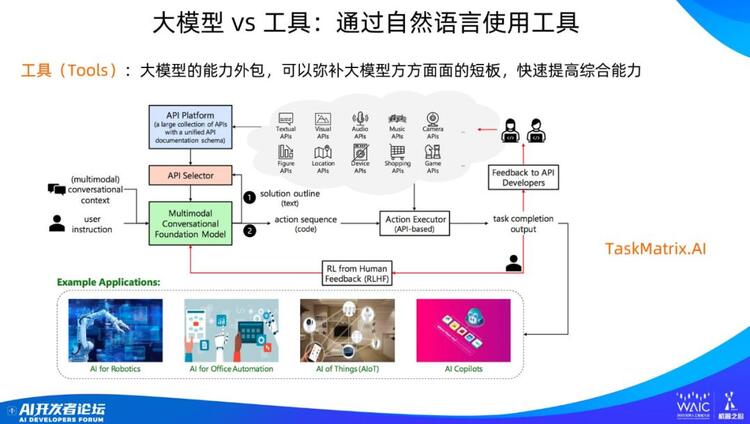
目前大模型使用工具的模式比较统一,如图所示,可以通过一个 API 管理平台来管理大量可用的外部工具。用户给出问题后,模型根据问题需求,判断是否应该使用工具,如果觉得需要使用工具,则进一步决定需要使用哪个工具,并调用对应工具的 API 接口,填写对应的参数,调用完成后整合工具返回的结果形成答案,再把答案返回给用户。
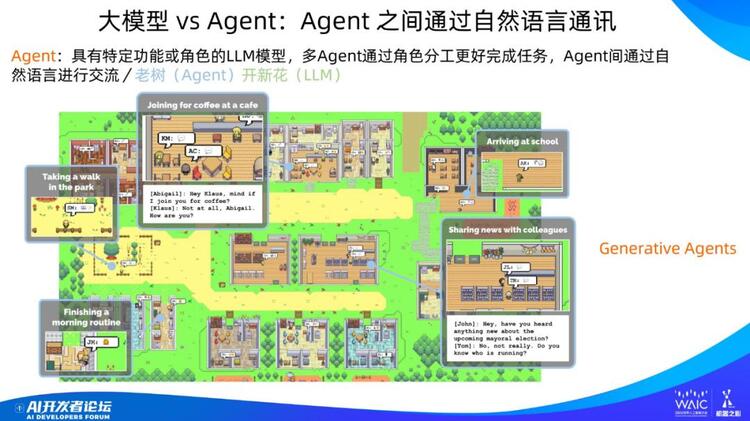
智能体是非常值得关注的技术,但大模型时代的智能体我们目前对其还没有统一的定义。你可以认为智能体是对大语言模型赋予的不同角色,这些角色通过分工的方式完成任务。智能体是有悠久历史的研究方向,几十年历史肯定有了,只是在大模型时代,由于 LLM 的能力加持,使得智能体有了完全不同的能力,并蕴含着巨大的技术潜力。另外,关于其定义,我觉得传统的智能体定义可能无法满足新形势下的情况,大模型时代可能需要重新定义智能体的含义。
上面展示了一个类似游戏沙盒环境下的模拟人类社会的智能体系统,每个智能体有自己的职业身份,不同智能体可以通过自然语言进行交流,并能举办各种聚会活动,看上去就是科幻剧《西部世界》的雏形。

如果归纳下 Agent 之间的协作方式,主要有两种:竞争型和协作型。竞争型就是不同 Agent 之间互相质疑、争吵、讨论,以此可以得到更好的任务结果。协作型就是通过角色和能力分工,各自承担任务环节中的一个,通过互相帮助和协作来共同完成任务。
最后我们讨论一下自然语言交互的优势和问题。用自然语言进行交互的好处是比较自然、比较便捷、比较统一,用户做事情几乎不需要学习成本;但是自然语言也有模糊性和语言歧义等缺点。

自然语言的模糊性是说有时候你用自然语言不容易讲清楚真实的意图,你以为你说明白了,其实并没有,但是你未必会意识到你没说清楚。这也是为什么现在用好大模型对于写 prompt 的要求比较高,毕竟如果用户说不清楚自己的意图,模型也不可能做好。
自然语言的歧义问题是一直存在且普遍存在的。比如「把苹果拿给我」其实有不同的含义,听者也可以有不同的理解,你怎么让大模型知道到底是哪个含义?
考虑到自然语言的模糊性和歧义性,从人机交互的角度来讲,将来大模型应该增强交互的主动性,也就是说让模型主动向用户发问。如果模型觉得用户的话有问题,不确定到底什么意思,它应该反问「你到底什么意思」或者「你说的是不是这个意思」。这点是大模型未来应该加强的部分。
感谢大家!
相关文章
- 同心智联、元境数融——WAIC 2024智能化、现实化、去中心化数字前沿论坛圆满举办
- 空间智能:迈向下一代人机共融——WAIC 2024「AI预见」产业高峰论坛成功举办!
- 蔚来十二项全栈技术亮相WAIC 2024
- 数据宝实力瞩目WAIC 2024,董事长圆桌对话剖析数据政策红利
- WAIC 2024海飞科GPU算力卡:单卡运行千亿参数AI大模型的先锋
- WAIC 2024×西门子:藏身幕后的巨人,正将工业AI带入下一阶段
- 戴尔科技亮相WAIC 2024
- WAIC创投生态|资本在Future Tech寻找下一个超级应用
- WAIC 2024亮点:T3出行展现AI赋能交通出行,预测自动驾驶商业化拐点
- WAIC 2024多款空间计算产品亮相,Meta/微美全息拥抱AR+AI技术引领潮流
- 商汤方舟多模态新智平台亮相WAIC,首个多模态大模型落地城市服务场景
- 网易伏羲有灵平台亮相WAIC 2024,探索人机共生新纪元
- 2024WAIC民企开放日走进魔珐科技,感受AIGC 3D内容生成技术发展进程
- 萤石网络携最新庭助理机器人RK3亮相WAIC 2024
- 扫描全能王:谢邀,人在WAIC,又上央视
- 标贝科技亮相WAIC2024 | 共筑语料生态链 共享语料新价值





