算力与能源正在成为世界的硬通货,看超级计算机安腾如何突围
2024-06-17 16:27:59爱云资讯阅读量:2,962
特斯拉创始人马斯克公开表态称未来两年人工智能行业将由“缺硅”变为“缺电”。据媒体报道,OpenAI的ChatGPT每天消耗超过50万千瓦时的电力,用于处理约2亿个用户请求,相当于美国家庭每天用电量的1.7万多倍。除了这类生成式AI耗能外,还有同样涉及到海量数据、特别是涉及到大规模并行计算的业务也正在成为“电能吞金兽”。全球前十名的超级计算机每小时耗电量高达2万度,堪比一座小型城镇的能源消耗。可见,随着技术革新步伐加快,全球算力竞争将对能源消耗提出更为严峻的考验,算力与能源将成为未来世界的核心硬通货。
以超级计算机为例,其作为解决复杂问题和大规模计算任务的利器,其能耗问题日益凸显,成为制约其长远发展的关键瓶颈。一味追求极致算力而忽视能源效率,不仅削弱了超算的实际价值,也使其发展陷入困境。正如美国加州大学计算机工程博士刘少山所指出,超级计算机是一个精密复杂的系统工程,任何短板都可能导致算力受限。
目前,各国在竞逐超算领导地位的同时,也在积极寻求在节能前提下提升性能的技术路径。
美国能源部于2013年和2018年先后启动“百亿亿次超级计算机”项目,明确要求E级机的功耗上限为20兆瓦,强调需要在不增加能源消耗的基础上提升性能,这表明如果单纯依赖扩大系统规模提升性能,那么E级机的技术选择将面临严格约束。2022年,麻省理工学院林肯实验室超级计算中心(LLSC)的研究人员进一步指出,超算系统的电源效率有巨大提升空间,如通过简单硬件调整如限制单个GPU功率,即可将AI模型训练的能源成本降低20%,仅带来适度的计算时间增长。
面对如何构建“既快又省”的超级计算机这一课题,大名鼎鼎的专用超级计算机安腾提供了一种新的解题思路。

安腾超级计算机丨图片来源:网络
安腾系列超级计算机由D. E. Shaw研究所研发,在能耗控制方面表现极为出色。
以第二代安腾超级计算机(Anton2)为例,其在一个单个机架内提供约2 TFLOPS(每秒万亿次浮点运算)的计算能力,能耗仅为25千瓦,与一辆中型电动汽车的充电功率相当,这一表现在当时同类设备中居于高位。
为什么超算安腾可以做到算得快还省电呢?
原因在于,有别于全面采用CPU、GPU等通用芯片架构的传统超算,安腾采用的是以ASIC专用芯片为主的专用超算的架构。专用超算在应用场景上受到严格的限制,只能处理某个特定领域的算法,例如安腾就是一台完全聚焦在生物计算领域最常用的分子动力学模拟计算的专用计算机,并且开发成本极其昂贵,但是以此为代价,换来的是在该特定领域的极强的加速性能和极低的能耗。
为降低全面计算资源损耗,超算安腾的软硬件采取了全面定制设计,核心组件为大量专用芯片(ASIC),并通过独特的高速三维环形网络实现互连。据称,在硬件上,整个超算安腾的ASIC芯片由288个核心瓦片和24个边缘瓦片构成,整体提供了5.6 Tbps的片外带宽。由于较大的Serdes物理PHYs在芯片的两个边缘都与这些瓦片相连,瓦片直接相邻,从而减少了未使用的芯片面积,简化了物理设计。
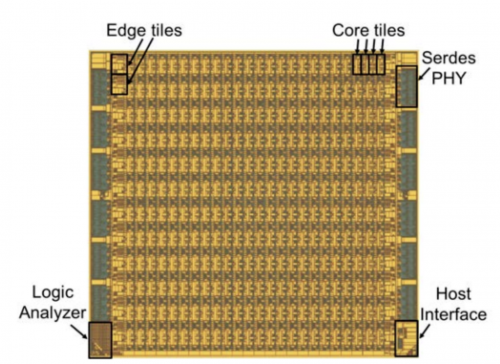
第三代安腾超级计算机的晶片管芯布局
同时,超算安腾的芯片保留了低电阻率的顶部金属层(TM0、TM1等)用于电源分配,从而确保其电源分配网络是完全连续的。为了改善瞬时电流尖峰,安腾将去耦电容、而不是备用单元装入所有可用空间,以良率来换取电源管理。并且,该芯片使用全局时钟网,以最小的偏移实现高时钟速度,这样的网状结构节省了功耗,网络只占芯片TDP(热设计功耗)的5%。
此外,超算安腾的芯片可以分区域、分精度计算不同任务,突破了制约分子模拟速度的瓶颈,这样可以在处理小任务时分配较少的节点用于运算,从而避免多节点时的能源浪费问题。
在通信层面,超算安腾各个节点之间通讯采用特殊设计的高速三维环形网络相互连接,形成了超高速低延迟网络。超算安腾共具有 512 个计算节点,它们在空间上的排布使得相当于将被模拟的系统分为 8 × 8 × 8 的盒子,每个盒子只负责 1/512 的原子,每个节点和盒子一一对应,并且只需要和邻近的 6 个节点通信。这些库中通信基于类 MPI 的「共享内存式并行」,把需要共享的数据放到公共空间各自读取;而这里每个节点之间都有点对点的专用信道,不存在访问资源的冲突问题。对于分子动力学而言,主要的通信内容是处在盒子边界的原子的位置,只有进行准确的通信,我们才能够准确计算这些原子与其他原子之间的作用力。由于低时延(约 50 ns)、高带宽的一对一信道的建设,大大减少了计算节点间通信需要的时间。这样,超算安腾可在512个节点并行处理下,能够对达100万个原子的大体系,每天进行10-100微秒量级的分子动力学模拟。相较于其他每天只能模拟几纳秒到几十纳秒不等的通用架构超算系统,512节点的超算安腾完成分子模拟的速度几乎快了100-10000倍。
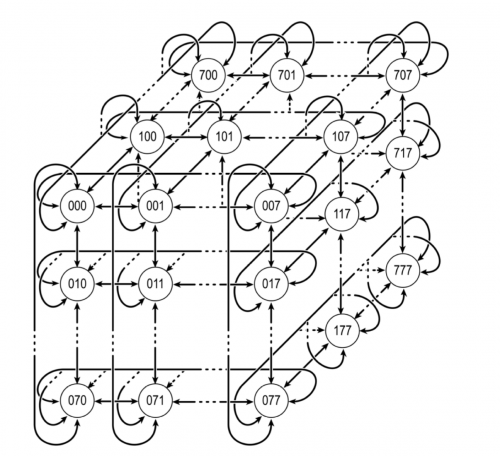
图片来源:众妙斋
2020年3月27日,D. E. Shaw研究所公布了新冠病毒3CL蛋白酶的长达100微秒的MD模拟动画及数据,3CL蛋白酶被认为在病毒增殖和组装中发挥了重要作用,并且是新冠药物开发的热门靶点之一。超算安腾完成的3CL蛋白酶MD模拟结果,为科学家和制药学家透彻理解新冠病毒增殖与组装的机理,从而开发针对性的3CL蛋白酶抑制剂提供了极其宝贵的研究基础。随后的两年里,D. E. Shaw研究所更是陆续围绕新冠病毒公布了超过1000微秒的MD模拟结果,对新冠病毒的病理研究和药物研发起到了非常重大的作用。
在计算效率和能耗方面,哪怕是现如今全世界最强的通用超算中心的算效,针对复杂程度达到百万体系的蛋白质给出100微秒的模拟结果,几乎需要花费数年时间才能算完,期间耗费的电量将达到兆瓦级别,换算成电费将达到数亿元。作为对比,超算安腾则只需要十几天就可以算完,并且至多也只需要几万元的电费,几乎是前者的千万分之一,这就是采用的专用超算架构、经过一系列软硬件功能特化的超算安腾在自己擅长的分子动力学领域能够实现的计算效率和能耗的绝对优势。
我们可以看到,超算安腾凭借其对分子动力学模拟的专注,以及自主研发的软硬件设计,实现了相较于通用计算机高达百倍的计算能效提升,并在此过程中显著降低了能耗。这一成果无疑为国内企业在面对未来计算需求与能源挑战时提供了深刻启示:在特定的高价值应用场景大力发展专用超算路线,有望在大幅提高计算性能的同时有效降低能耗,实现绿色、可持续的科技创新。
相关文章
- 北电数智“北京数字经济算力中心”,让算力更普惠
- “九州”算力光网走向纵深,持续强化“运力”新基建
- 2024长三角(芜湖)算力算法创新应用大赛颁奖典礼圆满落幕 展现芜湖数字经济新动力
- 青云科技 × 摩尔线程,共筑国产 AI 算力新生态!
- 获奖率不足1% !第二届“华彩杯”算力大赛全国总决赛上,兰洋科技突破重围再获殊荣
- 博大数据亮相2024香港金融科技周,领先融合算力助力点亮金融科技新航道
- AI浪潮下的智算中心新趋势:博大数据副总裁杨忠君谈算力基础设施的“九大关键变化”
- 中科视语联合创始人张腊:拥抱澎湃算力,加速大模型场景落地
- 节能减排先锋!博大数据斩获“2023-2024算力中心高质量节能减排案例奖”
- AMD下一代 X3D 芯片即将亮相,Google/微美全息积极投身AI算力布局
- 云从科技与广州数据集团签署战略合作协议 携手打造AI算力新高地
- 九章云极DataCanvas百万度算力免费申领活动狂欢继续!
- 维谛技术(Vertiv)助力海南人工智能计算中心开启算力狂飙
- 00后清华团队引领弹性算力革命,共绩科技挑战行业“不可能”三角
- 2024中国国际数字经济博览会:博大数据以智算引领,构建智能算力新生态
- 讯飞星火与华为数据存储强强联手,“以存强算” 助力AI集群算力利用率飙升30%





