GPT-4o 重磅发布 RTC 成为大模型关键能力
2024-05-20 17:09:21爱云资讯7313
北京时间5月14日凌晨,OpenAI 发布了新一代旗舰生成模型 GPT-4o,这是一款真正的多模态大模型,可以「实时对音频、视觉和文本进行推理」。核心亮点包含:支持与 AI 实时语音对话,且响应时间达到毫秒级;交互中可识别人类情绪并以相应的情感做出回应;多语言能力的提升。
包括OpenAI CEO山姆·奥特曼在内的很多人都联想到了科幻电影《Her》里那个幽默风趣、善解人意、似有心灵感应一般的AI,GPT-4o在语音视频上的交互能力,让科幻正在加速走向现实。

大模型的实时音视频交互成趋势RTC成关键能力
相比于GPT3.5、GPT4,GPT-4o最核心的区别在于文本、视觉和音频由同一个神经网络处理,不仅降低了延时,还捕捉到了更多的信息。此前基于GPT3.5或GPT4的AI语音助手是通过STT将语音转成文字再输入给大模型,大模型生成文本响应后再通过TTS输出语音给到用户,平均延时达到2.8秒(GPT-3.5)和5.4秒(GPT-4)。而GPT-4o直接将语音实时输入给大模型,并大幅提升响应时间,最终实现了与真人聊天一样自然流畅,AI的处理反应已经达到人类的高度和速度,而实现这一跨越式技术进步的关键,一是大模型的进化,二是RTC能力的应用。
GPT-4o的发布引起了业界的广泛关注与强烈讨论,也透露出一个重要的信号:支持端到端实时多模态将成为当下大模型发展的新趋势,实时文本、音视频传输能力,将成为实时大模型的标配。在GPT-4o的推动引领下,未来其他大模型厂商或将快速跟进,提供端到端实时多模态能力。
未来大模型的AI交互将更具真实感
GPT-4o还有一大核心亮点就是支持实时视频输入,通过前置摄像头设别你周围的环境,观察用户的面部表情,分析其情绪,再根据场景生成多种音调Tones,带有人类般的情绪和情感,如兴奋、冰冷、含羞等,通过实时视频输入还能让它在线解答各种问题,支持数学运算、游戏输赢判断等。
通过实时语音、视频输入信息的理解和高度拟人化的语音输出,GPT-4o所呈现的AI交互更具真实感与沉浸感,这也是所有大模型一直在发力的方向,未来借助低延时、高音质的RTC技术,有望打造更极致的人与AI交互体验。
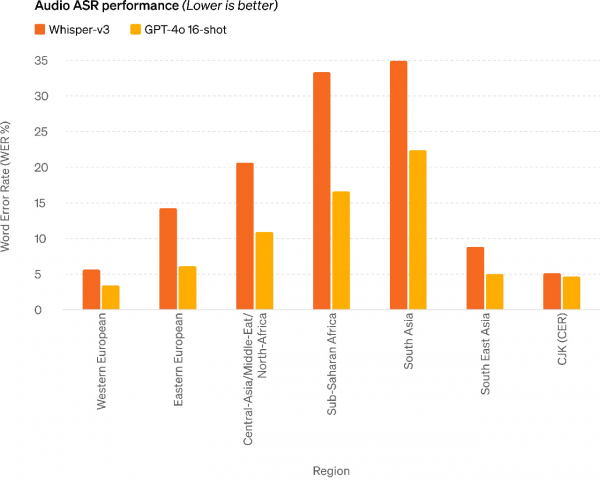
图:相比Whisper-v3,GPT-4o在语音识别性能方面有了大幅提升

图:GPT-4o的视觉理解评估能力也遥遥领先
在大模型的应用场景方面,除了已经在应用的AI口语老师、AI电话客服、AI社交陪聊场景,未来实时互动+AI+智能硬件也有望诞生新的场景。想象一下,一款加载了GPT4o的智能眼镜或耳机可以变成你工作中的助手,解答各类难题,也可以是生活中的“倾听者”陪你聊天,也可以是旅游中的虚拟导游,为你提供视觉攻略,这很可能是下一个时尚与科技兼具的爆款硬件。
在GPT-4o发布后,很多网友也提到了GPT-4o的社会公益价值,例如大模型通过智能眼镜的摄像头开启视觉能力后,可以给盲人带来精准的路线导航,盲人通过与搭配大模型的智能眼镜对话问路,智能眼镜在识别人周围的环境后,做出最精准的路线指引。
声网AIGC一站式音视频解决方案
针对大模型的交互能力,声网目前已可以提供基于大模型的全链路实时音视频方案,可以帮助大模型厂商构建实时音视频互动的能力,用户可通过麦克风与AI进行语音、视频形式的实时互动,并且对话中做到行业内遥遥领先的低延时对话体验。
声网的AIGC一站式音视频解决方案也可以实现像GPT-4o的音频对话能力。声网提供封装完整的SDK,并支持模块化能力的灵活拼装,包含RTC实时音视频、实时消息等多种能力,并支持API快速调用,提供开箱即用的场景化Demo,最快3h即可实现方案快速验证。尤其对于想快速验证新场景的企业与开发者而言,可以节省很多开发时间。
相关文章
- 中科视语提出工业异常检测大模型AnomalyGPT,实现零样本异常检测
- 通义千问新版本发布超越GPT-4-Turbo,微软/微美全息构建多模态AI生产力领先业界
- ChatGPT、Gemini、通义千问等一众大语言模型,哪家更适合您?
- 最新报告揭晓智慧芽专利大模型在知产领域表现超越GPT-4的技术细节
- AI周动态 | 万兴“天幕”公测,支持文生视频60秒+ 商汤日日上新5.0 性能对标GPT-4Turbo
- Nothing 推出集成了 ChatGPT 的 Ear 和 Ear (a)
- 摄影界的ChatGPT来了!百度网盘推出AI摄影创意工具超能画布
- 应对ChatGPT风潮,江波龙旗下行业类存储品牌FORESEE新品重磅亮相
- 融合视觉能力,OpenAI向开发人员提供GPT-4 Turbo with Vision
- GPT颠覆指纹识别,大扭力电机更配中国门,智能锁技术进入新纪元
- 德施曼智能锁引入GPT技术及大扭力电机,突破智能锁技术极限
- 音乐ChatGPT时刻来临!「天工SkyMusic」音乐大模型今日启动邀测
- Anthropic Claude 3大模型重磅来袭!微美全息全力冲刺加入GPT革命!
- 免费开放1000万字长文档处理功能,阿里通义千问文档能力超越ChatGPT
- 富勒科技发布FLUX GPT,打造“数字化员工”
- Sora接棒ChatGPT成AI领域焦点,苹果/微美全息迎变革机遇共谋AIGC新篇章





