放眼望去,没一个能打的自动驾驶AI处理器
2018-08-14 16:01:27爱云资讯阅读量:759
关于人工智能(AI)的报导一直不绝于耳。过去几年来,几乎每个月(有时甚至是每周)都会有一款现有或新创公司的全新AI处理器推出市场。
然而,悬而未决的问题是:为什么有这么多的AI处理器?每一款AI芯片的设计是为了解决哪些问题?更重要的是,当今的AI版图中还缺少哪些部份?
Tirias Research首席分析师Kevin Krewell直截了当地说,“AI带来了一种新典范,并改变了整个计算机系统。”现有企业和新创公司都在争夺仍处于混乱中的“AI就绪”(AI-ready)计算领域。
以色列Hailo是一家为“边缘设备深度学习”打造专用芯片的新创公司,今年6月宣布完成1,250万美元的A轮融资。Hailo的目标在于“为任何产品带来智能”(to bring intelligence to any product)。因此,Hailo首席执行官Orr Danon最近呼吁“彻底重新设计计算机架构的支柱——内存、控制和计算以及其间的关系。”
这是一个值得称道的目标。然而,Hailo既不打算透露其架构细节——Danon仅表示“可能就在今年底”,其首款AI处理器最快也要到2019年上半年后才会正式推出。
Danon认为,目前还没有一家自动驾驶车(AV)供应商能在无数的新一代AI处理器中找到适用于其自动驾驶车的芯片。
汽车领域正是Hailo看好其新款AI处理器得以发挥的直接目标市场。Danon指出,当今的测试自动驾驶车实际上都在公共道路上行驶,车后行李箱中还配置了一个数据中心。他说,为了填补这些测试车和自动驾驶车(必须为大量部署而打造)之间的巨大鸿沟,一线(tier one)和汽车OEM需要一种全新的AI处理器,协助其更有效率地执行相同的深度学习任务。
Hailo为此整理了目前每一款AI处理器的每瓦(W)深度学习TMACS。该公司与《EE Times》的读者分享的重点在于深入探讨:自动驾驶车产业在多大程度上仍无法获得推动高度自动驾驶车所需的高效能AI处理器。
业界分析师和其他AI新创公司高层也针对目前在AI发展道路上的重大障碍发表看法。
现代CPU架构并不适用于AI大多数业界观察家一致认为,目前基于冯·诺依曼(von Neumann)架构的CPU处理器无法有效因应当今的AI处理任务。
The Linley Group首席分析师Linley Gwennap指出,“Von Neumann不适用于AI。”他解释说,每一次的计算都必须撷取并译码指令,以及收集并储存数据于缓存器档案中。 “为了提高每瓦计算效能,你必须执行更多的计算和更少的撷取任务。”
Krewell同意这一看法。他说:“Von Neumann架构极其适于控制和循序计算:‘If-Then-Else’操作。相形之下,神经网络就像图形一样,是高度平行的,而且依赖于内存带宽的处理。试图用CPU扩展神经网络是相当昂贵的(包括功耗和成本)。”
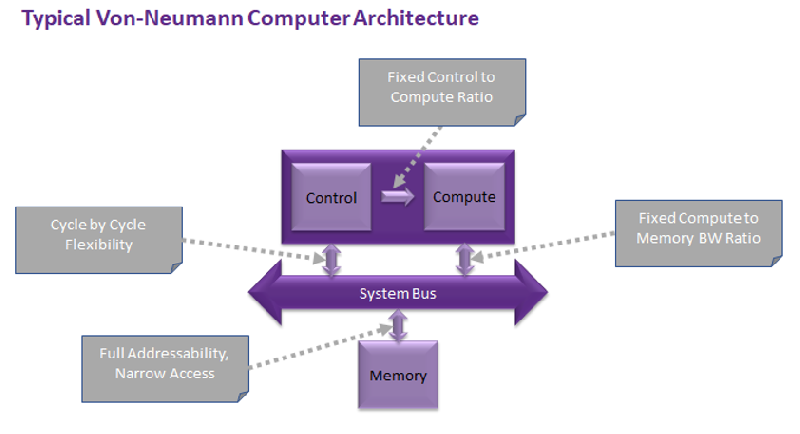
典型的冯·诺依曼(von Neumann)计算机架构(来源:Hailo)
Danon说:“尽管Von Neumann架构和现代CPU一般都非常灵活,但在很多情况下,这种灵活性并不是必要的。”它适用于神经网络和其他操作,例如,为未来的许多周期预先确定行为。在这种情况下,他指出,设计系统的更有效方法是“避免以读取指令来指导每个周期的系统行为。保持每个周期改变元素行为的灵活度非常重要。”
在Danon看来,“神经网络将这一概念推向了极致。‘结构’——决定操作数素之间连接性——确定整个会话的行为(又称‘计算图形’)。”简言之,AI社群需要的不是基于Von Neumann架构的处理器,而是“善于描述神经网络结构的特定处理器”。
重新关注数据流架构由于CPU和GPU的深度学习性能无法满足需求,引发业界积极寻找基于数据流(dataflow)架构的新解决方案。但为什么是数据流?
根据Gwenapp的说法,业界希望进行更多的计算和更少的撷取,首先尝试开发宽的单指令/多数据(SIMD)架构。“但是你只能将缓存器档案做得很宽。”业界很快地发现,该解决方案是“直接自动地将数据从计算单元移动到计算单元”。他说,“这是一种称为数据流的通用方法,可以大幅降低von Neumann的开销。”
不久前才收购MIPS的Wave Computing,是一家利用数据流技术的AI新创公司。根据该公司首席执行官Derek Meyer表示,Wave Computing设计了一款新的处理单元,“可以原生支持Google TensorFlow和微软(Microsoft)的CNTK”。
Danon坦承Hailo的新款AI处理器也属于架构的“数据流系列”。他解释说,数据流“通常更适合深度学习”,因为“用于计算的大多数参数都不需要移动。相反地,它们用于描述数据流动时的图形。”
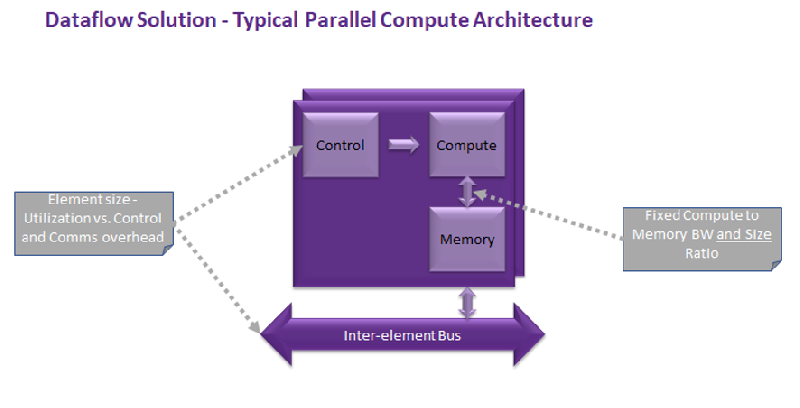
数据流解决方案:典型的平行计算架构(来源:Hailo)
Krewell指出,数据流的概念并不是什么新鲜事儿,也已经成功地在通用计算机硬件实现商用化了。
但是,随着AI改变计算领域,数据流正在寻找机器学习的“新机遇”。Krewell补充说:“透过使用数据流和脉动数组架构,您可以将神经网络处理设计为从一分层到另一分层,而无需太多控制逻辑。”
这种新转折可说是Wave Computing的天赐良机。该新创公司自2010年以来一直在利用其于数据流技术方面的专业知识以及建立专利组合,积极地专注于机器和深度学习。
内存带宽面临瓶颈AI——特别是卷积神经网络(CNN),似乎非常适合数据流设计。但是,Gwenapp强调,这并不表示所有的数据流设计都对AI有利,“系统中还存在着其他瓶颈,如内存带宽。”
业界开始看到这样的暗示:内存导向的装置是客制深度学习硬件的未来。例如,新创公司Mythic瞄准了将神经网络映像到NOR内存数组。该公司将“内存处理器”(processor-in-memory;PIM)架构用于AI,使其芯片得以在闪存中储存并处理神经网络权重,而其结果(最终和中间)则储存在SRAM中。因为这样的内存数组无需将数据移入和移出外部内存,所以,Mythic承诺将在其芯片中实现性能/功耗的巨大进展。
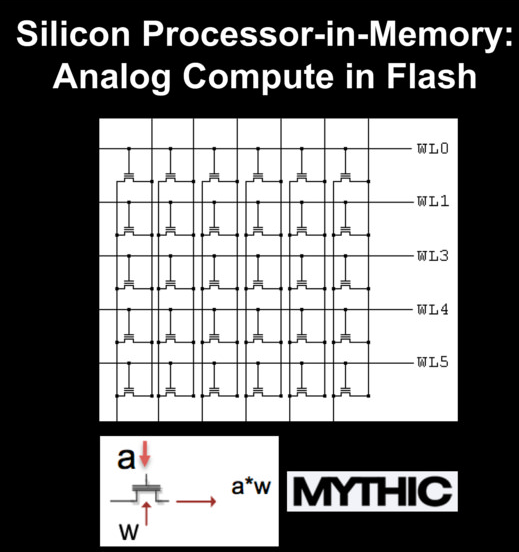
内存处理器(PIM)(来源:Mythic)
Mythic的设计概念当然具有吸引力,特别是当大多数芯片设计者试图提高内存带宽时,一般都采用可能造成破坏的方法。然而,Danon抱持谨慎看法,他表示还不确定Mythic的内存处理器芯片能否正常运作,但很可能“将技术推得太远了”。
Danon说,目前更实际和更现实的方法是“共同定位内存和计算”。“我们需要让计算结构能以高利用率存取所需的内存,从而产生非常高的带宽。”他补充说,这对于实现操作数素的高利用率至关重要。
Krewell则解释,“一些挑战是在训练期间保持权重。这就是像GraphCore在芯片上打造大型内存的原因。”他并补充说:“这也就是为什么GPU和英特尔(Intel)的Nervana使用高带宽内存(HBM)、Wave Computing使用美光(Micron) Hypercube内存的原因。”
除了TPU,如何调整软件和硬件?Danon表示,Google经由其Tensor处理器,“展示了一种样板”,用于从头开始设计高效率的架构,并针对推论任务进行了优化。这是个大好消息。然而,坏消息是,如果客户想要使用除了TensorFlow之外的深度学习架构呢?
在这种情况下,他们就需要翻译。虽然许多新兴工具,包括ONNX,都用于翻译几个AI架构,但Danon解释说,在此过程中,即使内容不会在翻译中完全遗失,计算也可能变得“非常低效”。他指出,产生这种困境的原因在于,以简洁方式描述问题的神经网络“结构”必须转换为von Neumann架构的通用处理器所使用的一系列规则操作。
Danon指出,当今的AI处理器在软件和硬件之间缺乏一致性。他说,在理想情况下,软件和硬件二者都使用基于结构的描述方法。Hailo计划将本机描述为“神经网络分层”,从而使其处理器有别于其他处理器。
Danon解释说,Hailo的目标“有点类似于汇编语言本身能够在基于规则的系统中描述规则一样——条件叙述和分支的形式。”
实现更高每瓦性能的竞赛深度学习性能效率是AI处理器竞争对手之间经常引爆的一场大辩论。在英伟达(Nvidia)和英特尔/Mobileye之间,两家竞争对手的高层还公开争辩其于Xavier SoC和EyeQ5的主张。

针对深度学习影像进行处理的实际处理器效率比较(来源:Hailo)
Hailo根据每家供应商发布的数据,编制了一份AI处理器比较表——从Nvidia的Volta V100、Pascal P4和Google TPU,到GraphCore IPU和Wave Computing DPU,详细列出每家供应商的深度学习tera级每秒乘积累加(TMAC)计算和功耗资料。Hailo的目标是为每个AI处理器计算深度学习的每瓦TMACS。Hailo并观察到当前的AI处理器可达到每瓦低于0.1TMACS的效能,而在使用批处理方法时可能略高于此。
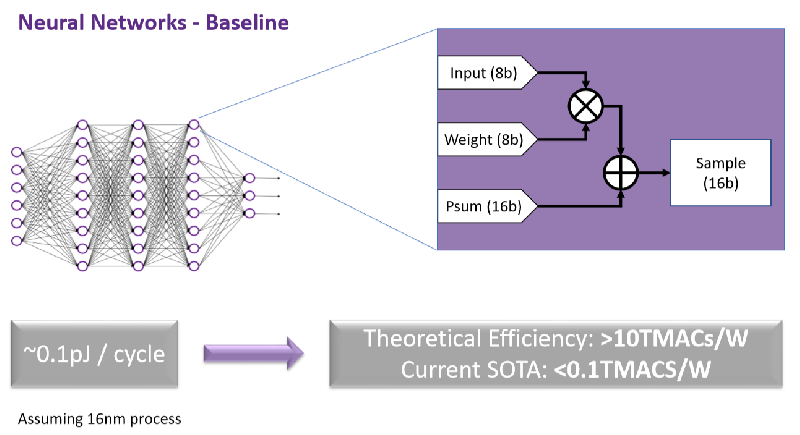
神经网络(来源:Hailo)
Danon以处理高清(HD)视频为例指出,如果车辆以每秒30格(30f/s)的速度接收全高清(FHD)视讯,并使用ResNet50网络进行深度学习。处理FHD视频串流通常需要每个传感器约5TMACS。根据自动驾驶的等级,一般汽车预计将配备4到12个摄像头传感器。
这意味着部署在自动驾驶车的任何现有AI处理器已经让每个传感器消耗约几十瓦功耗,或每辆汽车几百瓦了。Danon认为这已经超出太多了。或者,他怀疑,如果OEM无力应付这么多的电力浪费,他们别无选择,最终将只能在性能上大幅妥协。
理论上,“相较于传统的von Neumann处理器,精心设计的CNN加速器应该能达到更高数十倍的每瓦性能”。但是,Gwenapp说:“即便采用这种方法也不足以满足4/5级自动驾驶车的挑战性要求。”
换句话说,尽管市场上充斥过多的AI处理器,但没有一款能够达到让全自动驾驶车实现商用化可行的性能标准。
但Gwennap仍抱持乐观看法。“幸运的是,我们还处于AI竞赛的早期阶段。预计在未来十年内将能在硬件和软件方面看到大幅的进展。”
相关文章
- 文远知行韩旭收获福布斯出海领军人物奖,开拓全球自动驾驶“大航海时代”
- 沙利文最新报告:华为云位居汽车大模型市场领导者象限,加速自动驾驶落地
- 仙途智能亮相车联网产业发展高峰论坛,以新质生产力引领自动驾驶发展新篇章
- 出海提速,文远知行在新加坡连获两款自动驾驶环卫产品许可证
- Lyft携手Mobileye推动自动驾驶出行服务规模化发展
- 唯一上榜自动驾驶企业!文远知行荣登2024《财富》最受赞赏的中国公司榜单
- UBBF 2024 | 自动驾驶网络峰会在伊斯坦布尔圆满召开
- 德国巴伐利亚州副州长一行参访文远知行,共商自动驾驶欧洲发展蓝图
- 荣耀MagicOS 9.0正式发布,开启手机自动驾驶新时代
- 特斯拉在旧金山湾区测试自动驾驶出租车服务
- 特斯拉自动驾驶汽车Robovan公布,与文远知行旗下产品重名
- 特斯拉擎天柱机器人在自动驾驶出租车发布会上亮相
- 马斯克推出自动驾驶客货两用厢式货车Robovan:一次能最多装载20人
- 特斯拉推出自动驾驶出租车Cybercab 没有方向盘和踏板
- Waymo将与现代合作扩大自动驾驶出租车规模可能会抢特斯拉的风头
- 华为品质宽带创新,加速L4自动驾驶网络演进





