真正满足业务需要的算法!从LTV标签,浅谈基于奇点云DataSimba的MLOps实践
2023-11-08 16:05:45AI云资讯1533
今年8月,StartDT旗下GrowingIO分析云产品客户数据平台(CDP)正式上线了LTV预测标签。通过开箱即用的标签功能,分析师就能一键生成用户价值的预测结果,用于用户运营和价值分析。
LTV预测标签背后是怎样的算法?
为什么LTV算法以标签形式产出结果,能做到又快又稳?
企业在自建算法模型的过程中,还有哪些坑要规避?
本文以LTV算法为例,介绍基于奇点云数据云平台DataSimba的MLOps实践。
索引
1、背景:如何用算法让LTV预测更简单?
2、实践:LTV算法从开发到上线的3个难点
3、解析:基于DataSimba,完成MLOps全链路
4、提效:SimbaOS Kernel加持,让算法工程师专注算法
共4194字,阅读时间约16分钟。
(一)背景:如何用算法让LTV预测更简单?
LTV(Lifetime Value,生命周期价值)指用户与一家公司/品牌建立关系的整个“生命周期”内产生的价值,是企业市场营销、客户关系管理、用户运营中的一项关键指标。
通过分析、预测LTV,企业可以针对性地制定运营、营销乃至定价策略,助企业更高效地达成业绩目标。
过去,当营销活动需要基于用户LTV来制定策略时,有以下2种常见方案:
1、结合历史数据和个人经验制定策略。
这种方案有一定的数据基础,但对业务指标的总结、分析以及LTV的预测较为依赖“老法师”的经验,不确定性较高,且伴随重复、长期、大量的数据分析,无法快速响应业务的高频需求,结合业务发展更新迭代。
2、使用开源框架自研LTV算法。
伴随信息团队的壮大和开源技术的成熟,有越来越多的企业开始自研算法,尝试使用一些开源框架解决问题。但同时又不得不面对适配难、开发周期长、数据在多种工具之间流转安全无保障、训练成本高、缺乏专家经验、效果不够理想等问题,从开发到部署上线、在日常工作中高效使用,还存在鸿沟。
基于客户需求调研,奇点云算法团队和GrowingIO分析云产品团队“一拍即合”,选择开发LTV算法,并将它以“LTV预测标签”的形式嵌入到分析云客户数据平台(CDP)产品中。
LTV预测标签开箱即用,分析师只需要在CDP界面中选择用户表、事件表(核心转化/营收事件),设置LTV预测目标,就可以一键运行算法模型全链路,生成预测结果。
这样做的好处是,调用LTV算法不再需要依赖工程师,技术门槛大大降低,对业务响应速度快、效率高,算法也能基于最新数据自动迭代优化。
(二)实践:LTV算法从开发到上线的3个难点
LTV算法本身是基于一套自学习算法流程进行的自动化建模,需要对用户进行灵活的特征构建,并采用多个内置模型对比以避免模型结果漂移,帮助模型寻找用户群体规律,提高预测准确率。
考虑到LTV算法会在CDP产品中以“标签”形式被调用,除了算法本身的开发训练,算法团队还需要确保在实际的生产环境中依旧表现良好,输出既高效又稳定。
拆解来看,具体有以下3个核心难点要克服:
1、用于处理的数据不标准,配置不确定。
出于行业习惯、企业数据治理程度等原因,不同客户的数据基础往往存在较大差异。日常运营活动中,对于LTV的衡量方式也灵活多变。
因此,LTV算法选择基于UEI模型的标准数据表构建:
UEI(User用户、Event事件、Item实体)是GrowingIO分析云产品核心的数据模型,把所有用户行为、商品、门店等不同维度数据整合在一张表,以一个事件不同属性的形式呈现在宽视图中,以满足不同的分析需求。客户在使用CDP、UBA等产品时,基础数据已按照用户表、事件表、实体表构建。LTV算法直接采用,即可快速得到结果。
进一步,通过选填字段提升算法效果;通过一些识别规则和再处理逻辑的设置,来帮助算法在预处理、特征工程、训练集构建、模型构建阶段,能自适应不同量级、不同时间跨度的数据集,以及短则一天、长则数月的预测周期。
说人话:上述动作旨在简化用户使用算法的步骤,在保证算法效果的前提下,尽可能适应数据情况各不相同的企业。
2、算法应当稳定产出优于业务规则的效果。
稳定产出比业务规则、人工经验更好的效果,是开发LTV算法的初衷。
在模型构建过程中,算法团队选用了常用的三个决策树模型,并通过将测试集上的指标效果对比排序来选择模型。主要选择指标如下:

在进行目标金额的误差优化时,往往会损失一定分类排序性能。但用户(分析师、业务人员)在使用该标签时,通常直接将前排排序结果作为运营人群来进行触达。因此算法会对比三个指标的结果进行模型选择,避免模型漂移。
基线的构造方法如下:

基线构造方法
算法相对基线,LTV算法在下列指标上的提升如下:
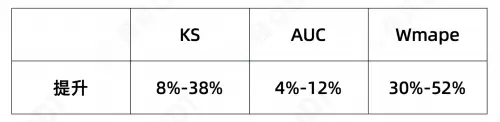
*不同数据集的指标结果相差较大,上表仅展示测试数据集的提升范围。
目前,LTV算法已能够快速、稳定输出优于重复业务策略的结果。同时,它依然拥有很大的优化潜力,可以针对数据集进行更多调整。(CDP提供标准的LTV算法预测标签,针对特定企业的优化属定制化开发项目。)
3、为优化用户体验,在资源和时效上应有保障。
完成开发并不是LTV算法的终点——能在企业生产环境中稳定发挥的算法,才是业务需要的好算法。
在实际生产中,算法运行通常要长时间地占用大量资源,而LTV算法的结果显式地展现为一个CDP标签,客户会对其时间、资源有更严格的心理预期。
因此,算法团队从以下3点优化体验:
· 进行算法资源隔离,确保算法能尽快申请到资源,并减少数据作业和算法作业互相影响而导致任务运行超载的情况。
· 拆分成若干个作业并配置Pipeline,为每个作业配置不同的参数,以减少单个作业的资源占用量,以及整个算法任务对大型资源的占用时间,并支持阶段性地输出运行日志。
· 通过前期大量测试及结果回归,为任务运行预估时间,并设置细致的数据校验,提供报错信息,以减少用户在使用中的焦虑,也更易运维。
其中,前2点能力来自SimbaOS Kernel(数据云操作系统内核,是DataSimba的核心)。
(三)解析:基于DataSimba,完成MLOps全链路
MLOps(Machine Learning Operations),是一种把ML(机器学习)模型的部署管理与DevOps(软件开发运维)相结合的实践和方法论,目标是实现并提升机器学习模型的可重复性、可扩展性和可维护性。
MLOps(的过程及相关工具)通常涵盖模型开发和训练、模型部署、监控和维护、自动化、版本控制和跟踪等环节,并支持团队协作和知识共享。
说人话,就是改“手工小作坊炼丹”为“成熟的工业化制造工厂”,让机器学习从研究及原型开发,真正转化为能满足业务需求的实际应用。
本文所介绍的LTV算法,从数据准备、模型训练到发布,以及作为服务被调用,也就是MLOps的全链路,均在DataSimba上进行。
算法工程师昭游介绍,LTV算法预测标签在上线前进行了约500次测试,其中包括但不限于规则阈值、压力测试、默认参数等等。得益于DataSimba的资源分配、版本管理、持续更新部署等能力,算法团队在作业调试、Pipeline构建及模型部署过程省去了不少烦恼,从而达成“代码管理整洁”、“调整测试便捷”、“部署上线快捷”三大目标。
抽象来看,DataSimba支持工程师完成MLOps的全链路如下图所示:

基于DataSimba的MLOps流程
1、数据集成,通过离线任务将数据保存至研发模块,并定期更新。DataSimba支持集成数据库类型或文件格式的数据。在LTV算法的场景中,底层数据主要来自ClickHouse。
2、在研发模块,进行作业开发。开发过程中的代码版本、更新历史记录、运行日志等,一并存储在DataSimba集成的Git仓库中,进行统一的管理。
3、从Git仓库中拉取最新的代码,配置算法构建任务流,以便持续集成与发布。
4、Pipeline在首次运行后,会生成模型文件,在模型中心进行注册与管理。并在后续运维过程中,持续部署、更新模型文件。
5、调用镜像和已注册的模型进行服务配置。后续模型的版本更新会自动从模型中心拉取最新版本。
6、在服务中心,对平台内的所有服务进行统一管理及调用。
7、(实时)终端/业务系统只需访问API,即可实时获取当前最新的模型预测结果;(离线)在Pipeline持续更新模型的过程中,输出的预测结果也会反向存储进数据库,终端/业务系统可通过访问数据库来获取离线的计算结果。
数据是AI的基础,算法依赖大量数据来训练模型,在生产环境中也需要处理数据来产出结果。如果算法工程师不需要从数据云平台导出数据到其他工具,不需要把数据下载到本地开发再导回生产环境做部署,也不需要在多个开源工具中流转,算法生产全流程的安全性及便利性将大大提升。
因此,数据云平台DataSimba不仅能完成“本职工作”(数据集成、研发、运维、治理、服务等),支持数据工程师搞定数据作业,也能支持算法工程师完成MLOps全链路工作——提供经清洗治理的数据,以及数据管理、建模、持续部署、计算资源与存储管理等全流程能力。

(四)提效:SimbaOSKernel加持,让算法工程师专注算法
经不严谨测算(消耗算法工程师3名),相较通过开源组件自建,或借助其他算法平台工具,依托DataSimba的全流程耗时可缩短40%~78%。
据算法团队介绍,一位没有算法基础的售前专家曾基于DataSimba创下1天内做出算法demo的纪录,“即便此前我们已经对他做过2小时培训,他对DataSimba各个模块相对熟悉,但这个速度还是挺惊人的。”
提效一方面得益于DataSimba具备一站式完成数据管理、建模、持续部署、计算资源与存储管理等全流程的能力,为算法提供经过治理的干净数据;
另一方面,则离不开SimbaOS Kernel(数据云操作系统内核)的加持——“包揽”了安全管控、资源管理、任务调度等底层技术问题,把算法工程师从各种权限配置、数据对接、争抢资源的“痛苦”中解放出来,更专注在算法本身。
*SimbaOS Kernel是DataSimba的核心层,将大数据领域的存储、计算、服务、调度、安全、租户等常用功能,抽象为一组标准对象模块。用户只需直接使用封装好的对象的能力,无需关注复杂的底层体系。
举2个例子:
1、不用抢,资源也有保障
依托SimbaOS Kernel和企业设定的资源调度规则,可以对算法作业配置资源及运行环境,确保算法能尽快申请到独立的资源,从而确保算法与数据作业运行无冲突,资源不抢占。
同时,SimbaOS Kernel的任务域支持作业Pipeline构建,可配置定时调度,拥有全套的任务失败恢复和基线告警机制,保证算法任务的高效执行。
2、全方位全链路守护安全
除了无需把数据导出平台、规避因多工具流转而带来的安全风险,SimbaOS Kernel更拥有一套完整的权限体系和数据安全策略,为上层的所有数据应用(包括SimbaMetric、CDP、UBA等)统一解决用户管理、身份认证、资源访问权限等安全相关问题,例如:
· 精细化管控用户权限,并通过项目划分确保数据隔离,算法任务只对必要数据有访问权限;
· 支持敏感数据自动识别、加密脱敏(如使用的数据表中涉及敏感数据),并可提供数据访问、调用、开发处理等行为的审计记录;
· 对业务数据、算法模型等数据资产提供异常操作行为识别、告警、防泄漏等安全保障。
目前,在DataSimba R4.9 LTS以上版本,均具备上述MLOps能力。同时,旗舰版套餐还包含专门为算法模型开发全生命周期管理提供的一站式平台工具SimbaML(算法工厂),以及包括推荐引擎、复购预测、流失预警、销量/销售预测、GraphOneID图计算等开箱即用的算法模型,帮助企业初步建立数据科学应用能力。详情可咨询奇点云客户经理/技术顾问了解。








