人工智能浪潮下的隐私计算应用价值
2023-05-08 11:42:05爱云资讯883

OpenAI开发的人工智能应用ChatGPT自2022年11月发布以来,持续受到了全球的广泛瞩目,甚至被认为开启了第四次工业革命。
而在2023年3月22日,ChatGPT却被曝出存在用户隐私漏洞,用户能够看到其他用户对话历史记录的标题,引发了公众对ChatGPT隐私泄露风险的担忧。3月31日,意大利个人数据保护局宣布禁止使用ChatGPT,德国等其他欧洲国家也陆续跟进发声,表示会考虑禁止ChatGPT收集数据。

近年来,数据安全问题成为社会焦点,数据泄露、滥用等数据安全事件频繁发生,人工智能技术在信息泄露等方面的社会性风险,则因为其使用的庞大数据规模而被进一步放大。如何在人工智能模型训练、智能化应用发展的同时兼顾数据安全,使得人工智能产品满足安全合规要求,成为业界持续关注的热点问题,隐私计算技术因其能够提供隐私安全条件下的联邦学习等机制而受到重点关注。
01人工智能模型训练面临哪些隐私安全风险?
人工智能模型训练需要经过数据采集、存储、共享、计算等阶段,分别面临不同的隐私安全风险:

采集阶段
主要面临样本数据隐私过度采集的风险,按照信息安全法规,企业在采集、保存、使用用户数据时应遵循“用户自愿原则”和“最小化原则”,需要依法依规判定数据的隐私合规性,否则将面临数据隐私违规过度采集的风险;
存储阶段
随着数据安全相关法律法规的完善,数据的分级安全管理等逐渐成为硬性要求,在样本数据存储时,“大汇聚”的数据集中存储模式将承担更大的数据安全管理责任,大规模样本数据的分级、权限管理极其复杂,稍有不慎就会出现影响恶劣的隐私泄露事件,将极大地增加隐私数据安全合规风险;
共享阶段
由于模型训练对数据规模和质量的较高要求,样本数据往往需要跨多个数据所有者进行共享传输,隐私数据可能遭受的攻击面扩大,存在数据越权访问、数据泄露、数据滥用等风险;
计算阶段
不同类型的模型训练任务需要分别构建标注样本集,在执行有监督机器学习时需要由人参与样本集的构建等工作,样本数据集的交叉使用过程中存在隐私数据滥用的风险,最终训练完成的模型在面对模型萃取、成员推理等攻击时,也存在隐私数据和模型成果泄露的风险。
02利用隐私计算机为人工智能隐私安全保驾护航
国务院2022年1月印发的《“十四五”数字经济发展规划》明确提出“鼓励重点行业创新数据开发利用模式,在确保数据安全、保障用户隐私的前提下,调动行业协会、科研院所、企业等多方参与数据价值开发”。隐私计算技术由于其既能促进数据流通又能保护隐私安全的特性,被广泛认为是当前破解数据流通困境的最佳手段。
隐私计算技术融合了人工智能、密码学、数据科学等众多领域,通过结合安全多方计算、联邦学习、同态加密、差分隐私和机密计算等为代表的现代密码学和信息安全技术,能够在保护数据本身不对外泄露的前提下,实现对数据处于加密状态或非透明状态下的计算和分析,达到对数据“可用、不可见”的目的。
在应用场景方面,隐私计算能够在数据本体不动的条件下,以“数据不动,算法跑路”的方式,在各参与方“数据不出门”的条件下,充分利用多个数据所有方的数据进行人工智能模型训练,为多个数据所有方之间的计算过程提供隐私保护,从而使得既能够有效释放各方数据的潜在价值,又能够规避数据传输相关的责任和风险。所以,隐私计算非常适用于一些数据敏感度高、隐私要求的人工智能模型训练场景,比如制造业利用多方生产数据进行工艺优化智能模型训练、医院利用多机构患者诊疗数据进行疾病智能预测模型训练、金融业利用多源信用数据进行风控评级智能模型训练等,这些场景下各方数据都属于不希望被他人获取的敏感数据,同时存在强烈的智能化模型计算需求。
在智能化模型训练方面,隐私计算技术已经在金融、政务、医疗等行业的智能化模型训练中进行了广泛应用,比如在金融领域,隐私计算能够在智能风险控制应用的模型训练过程中能够发挥重要作用,在“数据不出门”的前提下实现了政府机构、银行、企业间的数据协同计算,将分布式模型计算应用部署在各单位数据中心,智能化模型训练的全过程只交互模型计算结果,通过将个人和企业的税务、水电缴费、征信、消费等多种维度的数据进行融合分析,能够建立跨机构联合风控模型,在各方数据“不出门”的前提下实现信用风险评估画像,有效规避人工智能模型训练过程中的隐私数据泄露和滥用风险。目前,工商银行、交通银行、华夏银行等金融机构都在积极探索隐私计算技术在融资风控、跨境结算、金融保险黑名单安全查询、金融监管等场景下的应用。
03国内人工智能模型训练领域的隐私计算应用实践
据IDC预测,2025年中国隐私计算市场规模将达到145.1亿元,相比2021年的8.6亿元,有超过十倍的增长空间,年复合增长率高达102.7%。据华经产业研究院数据调研统计,隐私计算的应用需求迫切,金融、通信、政务、医疗、互联网、能源领域隐私计算需求分别占比53%、17%、13%、9%、5%、3%,当前国内主要隐私计算厂商重点聚焦在金融、医疗、政务三大领域。
我们以八分量为浙江省玉环市建设的“智能阀门产业互联网平台”为例,从应用实践角度进一步加深对工智能模型训练领域隐私计算应用的理解。
水暖阀门产业是玉环市第二大产业支柱,现有各类阀门加工企业900多家,产业产值接近350亿元,为当地提供了大量就业岗位。然而,在市场多重挑战下,玉环市的水暖阀门产业面临铜棒等原材料价格波动大、小微企业融资难、数据共享信息化基础薄弱等问题,使得产业链上的企业的采购议价能力弱、市场敏感度低、贷款融资不及时等问题,亟需打通整条产业链上下游的数据通路,运用数字化、智能化等手段实现产业赋能,为企业运营提供坚实的智能化数据和金融服务。
在此背景下,八分量针对玉环市水暖阀门产业的数字化转型需求,建设了“智能阀门产业互联网平台”,运用隐私计算、区块链、人工智能等技术,在“数据不出域”的条件下实现了智能阀门产业互联网平台、智能阀门产业互联网平台、阀门产业大数据平台等三方数据的融合计算,完成了多个智能化模型的协同训练。
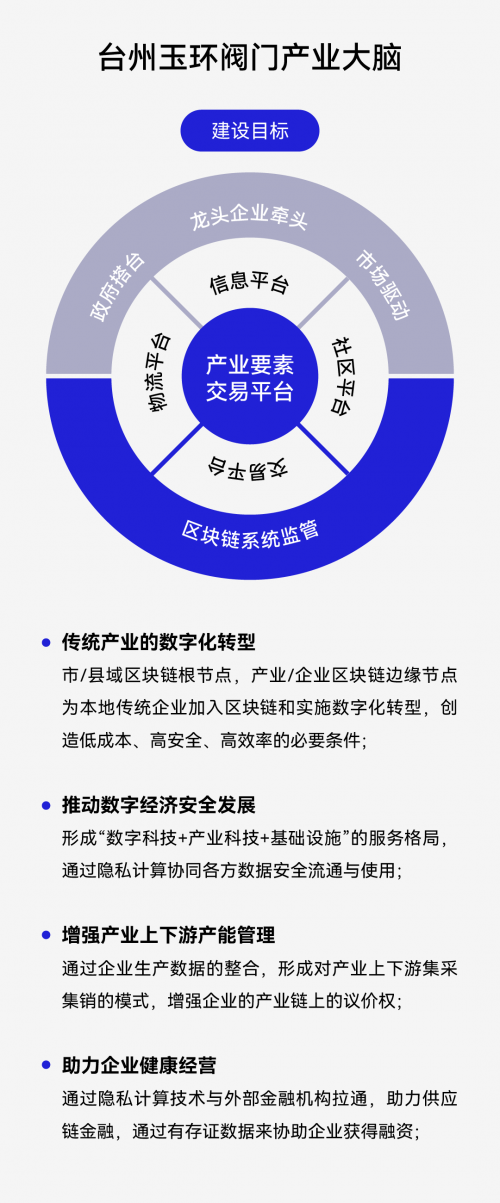
其中,政府大数据平台贯通了经信、工商、税务、商务等部门数据,提供当地水暖阀门、熔炼企业基础数据信息库,为实现水暖阀门产业链上资源整合、数据流通、对接等夯实基础;阀门产业大数据平台提供不同时段“铜采选”“铜加工”“铜价格”“铜消费行业数据”“铜冶炼”等相关数据,为阀门企业的生产销售和前瞻性分析提供垂直产业信息资讯、上下游产品价格预警、国内外产业舆情分析等数据支撑;智能阀门产业互联网平台提供产业要素流通过程中的订单、仓单、运单、发票、银行回单等数据,同时通过区块链对企业的静态数据、动态数据、历史数据等进行了可信存证。通过打通上述三大平台的信息,在“数据不出域”的前提下完成了以下模型的计算:
智能企业画像模型
建立了800多家水暖阀门、熔炼企业的智能企业画像,为实现水暖阀门产业链上资源整合、对接等夯实了基础。
采购需求预测模型
通过数据的融合,可对生产所需的上游生产材料、生产设备等进行预估测算,可由阀门协会牵头,通过集体采购的方式来获得更高的议价权。
企业信用评估模型
为金融机构提供了真实可信的应收账款、预付款等供应链数据作为企业资产信用背书,利用隐私计算技术融合多方数据,建立了企业信用评估模型,降低小微企业贷款融资难度,促进普惠金融政策落实,提高了产业转化效率。
通过隐私计算技术的应用,确保了整个智能阀门产业互联网平台相关模型的训练过程中,原始明文数据都没有出本地,真正保护了各方隐私数据。平台通过隐私计算技术保护各个数据源提供的数据不会被其他方获取,参与方只能使用数据而不能获取原始数据,避免了训练过程中各机构间交互明文数据,一劳永逸地解决了智能模型训练在数据采集、存储、共享、计算各阶段的隐私安全问题。
04隐私计算将成为数字化时代激发数据要素价值的利器
人工智能作为这个时代最具影响力的技术进步,已经在逐步改变全球经济的方方面面,随着人工智能技术不断取得突破,人类社会将逐渐迈入强人工智能阶段,而隐私计算技术也将作为人工智能模型的重要安全训练手段快速成长并驱动人工智能应用发展。

同时,我国数字经济“十四五”规划强调强调了充分发挥数据要素价值的必要性,隐私计算技术能够为充分发挥海量数据和丰富应用场景优势,有力促进数字技术与经济社会发展各领域融合发展,加快实现数字化发展、建设数字中国的远景目标提供重要技术基础,成为数字化时代激发数据要素价值的利器。
相关文章
- 人工智能搜索引擎Perplexity的AI语音助手已登陆iOS平台
- 学而思素养携手中国青少年宫协会 开启人工智能科普公益行
- 中国软件行业协会NCT编程考级2025年4月考圆满收官,新增人工智能教育测评体系
- 更能算、更省钱、更懂化工的国产人工智能来了!
- 2025“人工智能+”产业发展大会:开启智能产业新时代
- 云南联通科技创新暨人工智能合作发展大会在昆启幕:科技赋能边疆,智启数字云南新篇章
- 人民出行受邀见证中国-东盟人工智能创新合作中心签约 共启广西智能产业新篇章
- AI赋能,数智创新,慧博云通闪耀2025日本人工智能展览会
- 维基百科将发布专用于训练人工智能模型的数据集,以抵御网络爬虫抓取
- 培生发布智能课程生成器:创新人工智能驱动教师备课方式变革
- OpenAI发布全新人工智能模型o3和o4-mini,首次实现图像思考
- 深度迈进人工智能新纪元,标普云正式更名标普智元
- Meta AI宣布即将使用欧盟用户数据训练人工智能模型
- 英伟达宣布在台积电亚利桑那州工厂投产Blackwell人工智能芯片
- 九章云极DataCanvas入选2025全国企业“人工智能+”行动创新案例TOP100
- 云知声受邀参加2025中国数字经济产业发展大会,携手多方共筑苏州人工智能战略生态





