Omega全实时框架,让偶数湖仓一体方案与众不同
2022-08-12 16:04:24爱云资讯1305
近十余年,移动互联网的高速发展给互联网用户提供了更便捷的服务途径,不管是在地铁、饭店还是室外,用户都可以随时通过手机、pad等移动设备连接到高速的移动网络,实现购物、社交、商务会议等各种网络服务。与此同时,用户源源不断的产生和获取大量的数据,使得数据流量呈现爆炸式的增长,不论是互联网巨头、零售、政府、金融等行业,在海量数据的存储、查询和分析场景,都需要一个能承载多种数据,支持超高并发、易扩容、易维护的实时湖仓。
那么,最近热议的湖仓一体究竟是怎样的技术?什么又是实时分析处理?实时湖仓一体技术的逐步成熟,能给我们带来怎样的想象空间呢?
大势所趋,云原生实时湖仓一体
传统关系型数据库的技术架构,尤其是 OLTP 数据库在海量数据的存储、查阅以及分析方面出现了明显的性能瓶颈。随着分布式技术的产生和发展,出现了以 Teradata 为代表的基于专有硬件的MPP数据库,以及 Greenplum 和 Vertica 等基于普通服务器的 MPP 数据库。
在21世纪的前十年,大量企业开始采用MPP驱动的新型数据库系统,MPP解决了单个SQL数据库不能存放海量数据的问题,分析型MPP数据库的激增和成本下降也为数据驱动型组织提供了巨大的机会来运营和分析比以往更大的数据集,但与此同时,数据的快速增长也为固有体系带来额外的复杂性,MPP数据库在集群规模上是有限制的,它所支持的应用主要还是适合小集群、低并发的场景。
2010年前后,大数据热推动 Hadoop 技术快速普及,逐步形成了以Hadoop作为数据湖,MPP作为数据仓库的协作模式。这个阶段的 Hadoop+MPP 协作模式,也是“湖仓分体”模式。它让湖和仓有很好的技术特性互补,但是它也会产生严重的数据孤岛问题:同一份数据在多个集群冗余存储,分体模式下的湖和仓各自形成数据孤岛;数据达到PB 级别时, Hadoop 和 MPP 集群规模受限,Hadoop和MPP本身也需要拆成多个集群;在面对高并发数据查询时,易造成业务应用崩溃。另外,湖+仓带来的复杂的实施和运维问题更让从业者头疼不已。
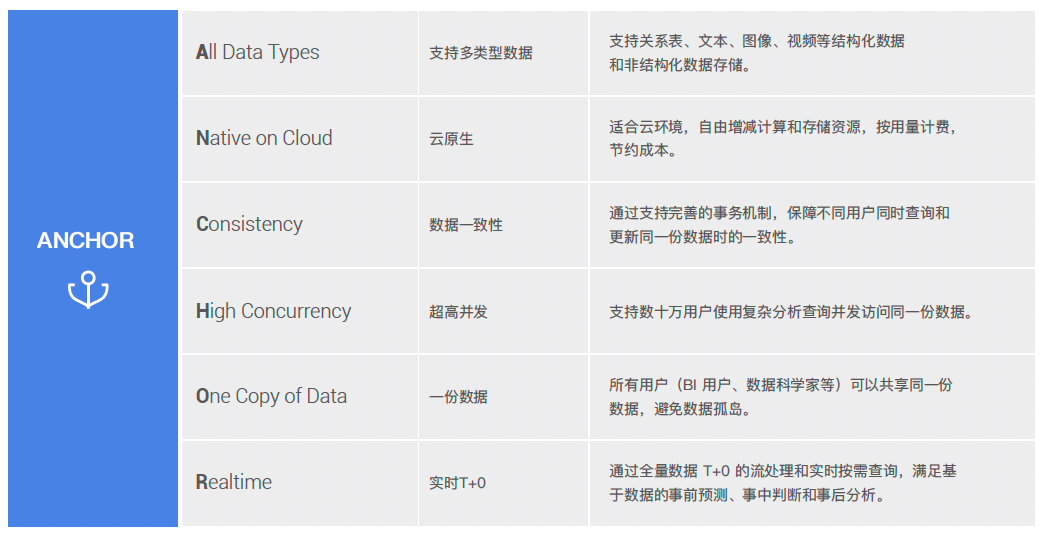
为了保证存储和计算可以独立的弹性扩展和伸缩,数据平台的设计出现了一个崭新的架构,即存算分离架构。显然,传统 MPP 和 Hadoop 都不适应这样的要求。MPP 数据库存算耦合,而 Hadoop 不得不通过计算和存储部署在同一物理集群拉近计算与数据的距离提高性能,仅在同一集群下构成逻辑存算分离。要真正的解决业务的痛点,选择企业适合的湖仓产品,我们可以参考ANCHOR 标准来选型。ANCHOR 中文译为锚点、顶梁柱,或将成为湖仓一体浪潮下的定海神针。ANCHOR 具有六大特性,其 6 个字母分别代表:All Data Types(支持多类型数据)、Native on Cloud(云原生)、Consistency(数据一致性)、High Concurrency (超高并发)、One Copy of Data(一份数据)、Real-Time(实时 T+0)。通过使用 ANCHOR 六大特性,很容易判断出某一系统设计是否真正满足湖仓一体。
OushuDB与美国 Snowflake,Databricks这一代产品突破了传统 MPP 和 Hadoop 的局限性,率先实现了存算完全分离,计算和存储可部署在不同物理集群,并通过虚拟计算集群技术实现了高并发,同时保障事务支持,成为湖仓一体实现的关键技术。
全新框架,Omega全实时框架实现T+0
目前,实时处理有两种典型的架构:Lambda 和 Kappa 架构。出于历史原因,这两种架构的产生和发展都具有一定局限性。
其中, Lambda 架构由于实时数据和T+1数据走不同计算和存储,难保障数据的一致性,Kappa 依赖 Kafka 等消息队列来保存所有历史,难以实现更新、纠错,故障升级周期长,并且不具备即席查询数据,架构实际落地困难。同时两个架构又都很难处理可变更数据(如关系数据库中不停变化的实时数据),即便引入流处理引擎实现了部分固定模式的实时流处理分析,仍无达到 T+0 全实时水平(此处全实时包含实时流处理和实时按需查询)。因此,我们需要一种新的架构满足企业实时分析的全部需求,这就是基于偶数科技自主研发的云原生数据库OushuDB的Omega 全实时架构。
Omega 架构由流数据处理系统和实时数仓构成。相比 Lambda 和 Kappa,Omega 架构新引入了实时数仓和快照视图 (Snapshot View) 的概念,快照视图是归集了可变更数据源和不可变更数据源后形成的 T+0 实时快照,可以理解为所有数据源在实时数仓中的镜像和历史,随着源库的变化实时变化。因此,实时查询可以通过存储于实时数仓的快照视图得以实现。另外,任意时间点的历史数据都可以通过 T+0 快照得到,这样离线查询可以在实时数仓中完成,离线查询结果可以包含最新的实时数据,完全不再需要通过 MPP+Hadoop 组合来处理离线跑批及分析查询。
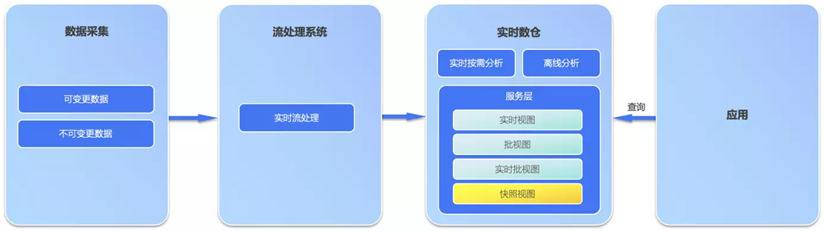
Omega 架构逻辑图
偶数流处理系统WASP既可以实现实时连续的流处理,也可以实现 Kappa 架构中的批流一体,但与 Kappa 架构不同的是,OushuDB 实时数仓存储来自 Kafka 的全部历史数据,而在 Kappa 架构中源端采集后通常存储在 Kafka 中。
因此,当需要流处理版本变更的时候,流处理引擎不再需要访问 Kafka,而是访问实时数仓 OushuDB 获得所有历史数据,规避了 Kafka 难以实现数据更新和纠错的问题,大幅提高效率。此外,整个服务层也可以在实时数仓中实现,而无需额外引入 MySQL、HBase 等组件,极大简化了数据架构。
在 Omega 全实时架构的加持下,偶数率先实现了具备实时能力的湖仓一体,即实时湖仓。实时湖仓统一了湖仓市(数据湖、数仓、集市),避免数据孤岛的同时,极大提升了企业实时数据分析能力,让企业在快速更迭的商业环境中立于不败之地。
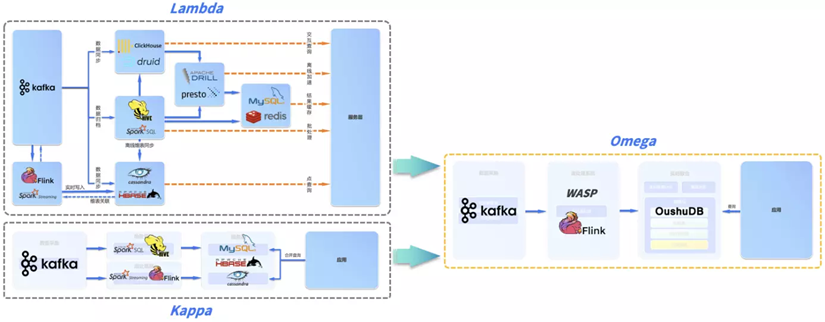
Lambda、Kappa 与 Omega 架构比较
数据说话,高性能OushuDB为企业保驾护航
一个新的Omega架构来实现实时湖仓,确实会令整个行业眼前一亮,但其性能究竟如何,与市面常见数据库产品的性能相比,是否能交出满意的答卷呢?
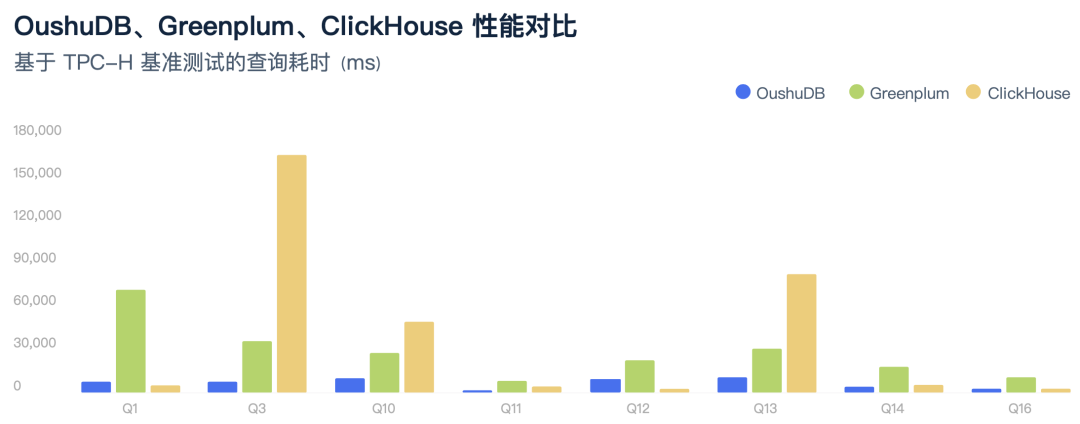
为了更直观的比较OushuDB的查询能力,我们用标准TPC-H来对OushuDB和其他知名的MPP数据库产品Greenplum、ClickHouse进行测试。TPC-H是美国交易处理效能委员会组织制定的用来模拟决策支持类应用的一个测试集,目前在学术界和工业界普遍采用它来评价数据查询处理能力。我们主要的评价指标是TPC-H包的22 个查询(Q1~Q22)各个查询的响应时间,即从提交查询到结果返回所需时间,我们分别对不同平台进行单节点使用Scale为100的数据集进行测试。测试结果显示,OushuDB和Greenplum支持全面支持 TPC-H 的 22 条查询语句,ClickHouse 只支持其中的部分语句;在性能方面,OushuDB表现优秀,总体性能在ClickHouse和Greenplum的5倍左右,很多查询时间快一个数量级以上。
用户信赖,新锐准独角兽脱颖而出
尽管OushuDB只是一个诞生5年的云数据库,但OushuDB却是由国内顶尖工程师自主开发,其研发团队曾主导国际顶级的数据库开源项目,符合国家信创标准。偶数科技作为一家新兴的数据库公司,自2017年诞生以来,作为微软加速器和腾讯加速器成员企业,已经获得世界顶级投资机构红杉中国、腾讯、红点中国与金山云的四轮投资,并入选福布斯中国企业科技 50 强以及美国著名商业杂志《快公司》中国最佳创新公司 50 强。除了OushuDB,偶数科技的实时湖仓一体解决方案还包含自动化机器学习平台LittleBoy 、数据分析与应用平台Kepler以及数据管理平台Lava等多个产品, 深厚的研发实力和优秀的产品性能吸引了广泛的知名用户群,目前已在金融、电信、制造、公安、能源和互联网等行业得到广泛的部署和应用。

相关文章
- Gartner发布2023年最新技术成熟度曲线,偶数科技位列湖仓一体代表厂商
- 偶数科技发布实时湖仓数据平台Skylab 5.3版本
- 入选首批共建单位,偶数科技亮相TDBC2023可信数据库发展大会
- 偶数科技入选 Gartner Cool Vendor ,成为最酷厂商
- 专访偶数科技CEO常雷:ANCHOR云原生及湖仓一体浪潮下的定海神针
- 偶数科技:基于OushuDB的新一代云原生湖仓一体
- Omega全实时框架,让偶数湖仓一体方案与众不同
- 偶数科技受邀参加阿里云生态大会,分享 OushuDB 在云时代的架构哲学
- 偶数全实时数仓Omega技术架构解析
- 偶数科技正式发布湖仓一体研究报告
- 偶数科技OushuDB通过金融信创生态实验室测试
- 偶数科技入选Gartner《中国数据库行业市场指南》
- 偶数科技荣获「优秀中国开源原生创企」奖项
- 偶数科技与海天起点达成战略合作
- 偶数科技入选福布斯中国企业科技50强
- 偶数科技携OushuDB云原生数仓亮相2021腾讯数字生态大会





