如何基于声网“实时声纹变声”实现对声音的“克隆”
2022-03-15 15:26:13爱云资讯阅读量:794
说到声音变声,很多人最早的记忆是《名侦探柯南》中柯南的领结变声器,小时候还曾幻想拥有这样一款神器,那一定很酷。而在互联网时代,这种幻想已经成真,随着很多变声软件的应用,我们经常可以在社交、游戏场景中听到玩家通过变声软件发出与性别、年龄相反的声音。不过,这种变声器往往是将一个人的声音变换成某一种类型的声音,例如男声变成萌妹子的声音,无法像柯南那样将自己的声音变成特定某个人的声音,并不是真正意义上的声纹变声。
由声网音频技术团队研发的「实时声纹变声」将颠覆传统的变声音效软件与AI实时变声体验,通过提取语音的音素特征与声纹特征等一系列技术手段,在实时音视频互动中可以将任意用户的语音实时变换成指定或任意一个他人的语音,实现像柯南变声器那样对声音的真正“克隆”,接下来我们将分别介绍传统主流变声方法与实时声纹变声背后的技术原理。
什么是声纹变声?
在介绍变声之前,我们先回顾一下语音的产生与感知过程。在说话时,我们将自己思想对应的文字,通过发音器官(如肺、喉咙和声道)一起协作,产生含有特定语义的声波信号。由于每个人的发声器官、语言习惯、发音大小、基频等差异,每个人的声纹图谱都是独一无二的,就像指纹一样,因此人们可以通过听觉系统辨别一个人的身份信息。事实上,在感知层面,人们可以很轻松地分离出一段语音的语言学内容(文字)以及说话人的音色信息(声纹)。

声纹变声是指对一段语音的音色做替换,让它听上去像是另一个人在讲同样的内容。声纹变声的处理过程包含语音的感知分离以及合成两个步骤。首先,声纹变声系统中的语音识别模块会将接受的语音中的语言学信息以及说话人音色信息分离。然后,语音合成模块将目标说话人的声纹与前面提取的语言学内容重新合成新的语音,从而实现音色的变换。
介绍完声纹变声的基本原理,我们再来看看传统的变声方法有哪几种,它们又是基于怎样的技术原理实现的?
1、传统的音效效果器:早期的变声一般采用多个音效效果器串联的方式来从各个维度来修改人声。常见的变声效果器包括变调效果器、均衡器、混响效果器、共振峰滤波器等,变调效果器通过改变声音的音调来实现变声效果,比如把男声变成女声就需要把音调提高,电影《小黄人大眼萌》中“小黄人”的声音就是通过变调算法把原本男声的音调提高来实现的。均衡器和共振峰滤波器通过改变人声每个频段的能量分布来改变音色,较高的值可让声音听起来更洪亮或清脆,较低的值可赋予深沉、浑厚的特性。混响效果器则是改变人声所在空间的混响效果。
但这些效果器的方式通用性较差,每个人变成一个目标人的音色都需要重新调整参数,而且语言中每个音的发音变化趋势也不尽相同,采用同一组参数调整的效果器可能只对某些发音是正确的,这就使得很多变声效果十分不稳定。我们在文章开头提到的在社交、直播场景中很多主播
使用的软件变声效果器或者娱乐声卡上自带的变声效果大多是这类方式,这类方式虽然可以做到“实时”,但由于采用的是传统的链路效果器,非声纹变声,不仅变声效果不稳定,变声的音效也非常局限,不能任意变换成某个指定人的声音。
2、AI变声算法:AI技术的发展为传统变声效果器需要对每个人、每个音进行单独调整的繁琐流程找到了破解方式。早期AI变声算法主要是基于统计模型,其核心思想是寻找一种说话人语音到目标语音在频谱上的映射关系,模型需要在平行语料上训练。所谓平行语料,就是说话人说的每一句话,变声目标人都要有一句同样内容的语料。平行语料的训练样本由具有相同语言学内容的原始语音和目标语音组成。虽然基于这个框架的模型在变声上取得了一定成功,但是这种配对的数据比较稀缺,而且很难有效拓展到多说话人变声的场景。
而近几年的主流的AI变声算法通过非并行训练框架有效地解决了这些问题,并且极大地丰富了变声的应用场景,比如音色,情绪以及风格的迁移等等。非并行训练方法的核心思想是将语音的语言学特征以及非语言学因子(例如音色、音调)解除耦合关系,然后再将这些因子重新组合生成新的语音。它不依赖于配对的语音语料,极大地降低了数据获取成本。同时,这个框架也十分有利于知识迁移,可以利用一些在海量数据上预训练好的语音识别以及声纹识别模型用于语言学内容与声纹特征的提取。
随着深度学习的发展,当前基于 AI 的变声算法种类越来越多,它们相较于传统的变声方法在目标音色相似度以及自然度上都具有显著的优势。按照单个声纹变声模型支持的原说话人和目标说话人的数目,可以分为 one-to-one, many-to-many, any-to-many, any-to-any,其中,one 代表单一的音色,many 代表一个有限的集合,只能变成少数几种指定的音色。早期的学术研究主要是基于one-to-one 与 many-to-many架构,any-to-many 是当前很多 AI变声软件采用的模型,例如在某变声软件中,任意用户可以从十几个声音音效中选择某一个进行变声。
而 any 是一个开放的集合, any-to-any 意味着可以将任意一个人的语音,变换成任意一个其他人的语音,这代表着声纹变声技术的终极目标,每个人都可以借助它变换成指定或任意一个人的声音,实现对声音的“克隆“,这也是「声网实时声纹变声」想要实现的方向。
从any-to-many 到 any-to-any,实时声纹变声需克服多重挑战
当前,主流的声纹变声借助 AI变声算法虽然可以实现 any-to-many 的变声音效,但声纹变声的研究主要集中在离线或异步使用的场景,例如自己提前用变声软件录一段声音,生成某个指定目标的变声语音后再发给对方。根据调查显示,在社交、直播以及元宇宙等场景中,越来越多的玩家希望在进行音视频互动时能实现实时变声音效的功能,在声网看来,在实时互动的过程中,声纹变声想要做到实时会面临多重挑战:
1、语言学内容完整性:在实时互动过程中,说话人部分词语的丢失或者发音错误,不仅会让听者理解起来十分吃力,而且一些关键词(比如"不")的丢失,还会引起全局语义改变,给互动带来致命的影响。
2、实时率:实时率指的是模型对一段音频的处理时间和音频时长的比值,越低越好。例如处理一段时长为2分钟的语音花了1分钟,那么实时率就为(1/2=0.5),理论上,变声引擎端到端的实时率只需要小于1即可支撑实时变声处理。考虑到计算的抖动,需要有更低的实时率才能保障稳定的服务,这对于模型的大小以及算力有很大的限制。
3、算法延迟:当前大部分变声算法在处理当前帧数据时,依赖于未来语音帧的数据输入,这部分语音的时长即算法延迟。在实时交互场景,人们可以感知到的延迟大约在200ms,过高的延迟会极大程度降低用户参与的积极性。例如用户说完一句话,对方如果需要等待1秒以上才能听到变声后的语音,很多人可能就不会在聊天场景中使用这个功能了。
对此,声网音频技术团队是如何解决算法的延迟与音频处理的实时率,并实现 any-to-any 变声音效的突破?
首先,「声网实时声纹变声」先通过语音识别模型提取语音中帧级别的音素特征,声纹识别模型提取声纹特征,然后将两者一起传递给语音合成模块,合成变声后的频谱特征,最后利用 AI声码器合成时域波形信号,这三个模块均支持流式的数据处理。流式处理主要是针对数据的新鲜度价值很高,需要提供更快的有价值信息,通常在触发器开始后的几百甚至几十毫秒内需要得到处理结果,在实时声纹变声中,流式处理表现为音素、声纹数据的实时处理、低延迟,人们在使用变声效果对话时还需要保证沟通的流畅性,不能一方说了一句话另一方过了好几秒才听到变声。
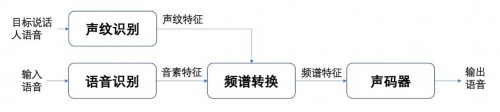
在神经网络设计层面,声网主要采用 CNN (卷积神经网络)和 RNN (递归神经网络) 的网络结构分别提取语音信号中的局部以及长程时序特征。语言信号具有短时平稳的特性,用CNN 可以很有效的提取帧级别的音素特征。RNN 对语音中随时间变化更为缓慢的特征(字词)建模,一般一个字的发音会持续几百毫秒,所以声网利用基于 RNN 这种具有时序记忆能力的网络来构建频谱转换模块对语音的时序性特点进行建模。
RNN 处理的数据是 “序列化” 数据,训练的样本前后是有关联的,即一个序列的当前的输出与前面的输出也有关,比如一段语音是有时间序列的,说的话前后是有关系的。通过这种设计,不仅有效地节省了算力,而且也显著减少了算法的延迟,目前「声网实时声纹变声」的算法延迟最低可以做到 220ms,处于业内领先的水平。
此外,声网基于海量数据单独训练了语音识别模块,可以准确地提取帧级别的音素特征,极大程度地减少了变声后出现错字或者漏字的情况,保障了语言学内容的完整性。类似地,声网也基于海量数据训练了声纹识别模型,用于提取目标说话人的音色特征,显著地提升了变声后语音和目标说话人的音色相似度,最终实现了any-to-any的变声能力。
(我们可以通过声网微信公众号找到这篇文章,文章中的视频Demo可以更直观的体验实时声纹变声带来的变声效果,Demo是由音频技术团队在实时的过程中录制。)
相比于传统的变声软件,实时声纹变声凭借实时性以及 any-to-any 的变声能力,将在语聊房、直播、游戏、元宇宙等场景中发挥更大的应用价值,不仅可以增强应用场景中用户的沉浸感与娱乐性体验,对应用的用户活跃度、使用时长、营收等也有望带来进一步的提升。
例如在传统语聊房场景中,变声软件只能变成萌妹子或大叔的声音,实时声纹变声可以将用户的声音改变成与某些明星类似的声音,将原本枯燥的语聊房变成明星聊天室。而在Meta Chat等元宇宙场景中,实时声纹变声可以搭配3D空间音频进一步增强用户的沉浸感,例如某社交APP与《海绵宝宝》达成合作后获得动漫中角色IP的形象与声音授权,用户在操控着专属的动漫角色聊天时,声音可以变成对应的海绵宝宝、派大星、章鱼博士等角色的声音,感知层面仿佛进入了真实的动漫世界,用户的沉浸感得到有效提升。
基于此,实时声纹变声也可以进一步扩展影视、动漫IP的声音价值,知名影视、动漫角色的配音都可以运用在语聊房、直播间、游戏语音等场景的实时音视频互动中,对于应用本身而言,更丰富的娱乐性体验可以提升用户在应用内的使用时长、付费率等。
目前「声网实时声纹变声」现已开启开放测试,如您想进一步咨询或接入实时声纹变声,可通过声网微信公众号找到这篇文章,并通过文章底部的「阅读原文」留下您的信息,我们将与您及时联系,做进一步的沟通。
相关文章
- 声网 VoIP CallKit 上线 支持智能硬件与微信小程序实时通
- 声网钟声:分布式端边云结合将成为实时 AI 基础设施的
- 声网钟声:分布式端边云结合将成为实时 AI 基础设施的未来
- 声网荣膺金帆奖「年度优秀出海产品技术服务」
- 声网CEO赵斌:RTE将成为生成式AI时代AI Infra的关键部分
- 声网解读泛娱乐2024:行业趋势洞察,新动向展望
- 声网RTE2024泛娱乐出海专场:“AI+”带来泛娱乐出海新机会?
- 声网 AI x IoT 解决方案 构建智能硬件低延时语音交互体验
- 构建AI实时音视频互动 声网这套方案听、看、思、说样样精通
- 声网对话式AI解决方案上新 构建实时多模态AI交互
- 声网《读懂实时互动》新书发布 记录RTE的过去、现在及未来
- 声网4K 60帧超高清游戏直播,激活游戏社交互动新体验
- 声网北美出海观察:本土开发者稳居泛娱乐头部市场,国内出海以短剧为主
- 声网联合 Unity 中国正式发布 UOS Hello 为开发者提供一站式游戏语音服务
- 声网发布Linux Server SDK 支持大模型Python与Go语言
- 声网&小天才 实时字幕,嘈杂环境视频通话“听”得清





