百分点感知智能实验室:计算机视觉理论和应用研究
2022-01-27 10:20:23爱云资讯891
编者按:计算机视觉(ComputerVision,CV)是一门综合性的学科,是极富挑战性的重要研究领域,目前已经吸引了来自各个学科的研究者参加到对它的研究之中。
本文中,百分点感知智能实验室梳理了计算机视觉技术基本原理和发展历程,针对其当前主要的研究方向及落地应用情况进行了深入剖析,并分享了百分点科技在该领域的技术研究和实践成果。
一、概览
计算机视觉(ComputerVision,CV)是人工智能的一个领域,它与语音识别、自然语言处理共同成为人工智能最重要的三个核心领域也是应用最广泛的三个领域。计算机视觉使计算机和系统能够从数字图像、视频和其他视觉输入中获取有意义的信息,并根据这些信息采取行动或提出建议。如果人工智能使计算机能够思考,那么计算机视觉使它们能够看到、观察和理解。
计算机视觉的工作原理与人类视觉大致相同,只是人类具有领先优势。人类视觉具有上下文生命周期的优势,可以训练如何区分对象,判断它们有多远、它们是否在移动,以及图像中是否有问题等情况。计算机视觉训练机器执行这些功能,不是通过视网膜、视神经和视觉皮层,而是用相机、数据和算法,能够在更短的时间内完成。因为经过培训以检查产品或观察生产资产的系统可以在一分钟内分析数千个产品或流程,发现不易察觉的缺陷或问题,所以它可以迅速超越人类的能力。
1.计算机视觉工作原理
计算机视觉需要大量数据,它一遍又一遍地运行数据分析,直到辨别出区别并最终识别出图像。例如,要训练计算机识别咖啡杯,需要输入大量咖啡杯图像和类似咖啡杯的图像来学习差异并识别咖啡杯。现在一般使用深度学习中的卷积神经网络(Convolutional Neural Networks, CNN)来完成这一点,也就是说最新的科研方向和应用落地绝大多数都是基于深度学习的计算机视觉。
CNN 通过将图像分解为具有标签或标签的像素来帮助机器学习或深度学习模型“观察”,使用标签来执行卷积(对两个函数进行数学运算以产生第三个函数)并对其“看到”的内容进行预测。神经网络运行卷积并在一系列迭代中检查其预测的准确性,直到预测开始成真,然后以类似于人类的方式识别或查看图像。就像人类在远处观察图像一样,CNN 首先识别硬边缘和简单形状,然后在运行其预测的迭代时填充信息。
2. 计算机视觉发展历程
60多年来,科学家和工程师一直在努力开发让机器查看和理解视觉数据的方法。实验始于1959年,当时神经生理学家向一只猫展示了一系列图像,试图将其大脑中的反应联系起来。他们发现它首先对硬边或线条做出反应,从科学上讲,这意味着图像处理从简单的形状开始,比如直边。
大约在同一时期,第一个计算机图像扫描技术被开发出来,使计算机能够数字化和获取图像。1963年达到了另一个里程碑,当时计算机能够将二维图像转换为三维形式。在1960年代,人工智能作为一个学术研究领域出现,这也标志着人工智能寻求解决人类视觉问题的开始。
1974年引入了光学字符识别 (OCR) 技术,该技术可以识别以任何字体或字样打印的文本。同样,智能字符识别 (ICR) 可以使用神经网络破译手写文本。此后,OCR和ICR 进入文档和发票处理、车牌识别、移动支付、机器翻译等常见应用领域。
1982年,神经科学家David Marr确定视觉是分层工作的,并引入了机器检测边缘、角落、曲线和类似基本形状的算法。与此同时,计算机科学家Kunihiko Fukushima 开发了一个可以识别模式的细胞网络。该网络称为Neocognitron,在神经网络中包含卷积层。
到2000年,研究的重点是物体识别,到2001年,第一个实时人脸识别应用出现。视觉数据集如何标记和注释的标准化出现在2000年代。2010年,李飞飞所带领的团队为了提供一个非常全面、准确且标准化的可用于视觉对象识别的数据集创造出了ImageNet。它包含跨越一千个对象类别的数百万个标记图像,并以此数据集为基础每年举办一次软件比赛,即ImageNet大规模视觉识别挑战赛(ILSVRC),为当今使用的 CNN 和深度学习模型奠定了基础。2012 年,多伦多大学的一个团队将 CNN 输入到图像识别竞赛中。该模型称为 AlexNet,它是由Yann LeCun于1994年提出的Lenet-5衍变而来,显著降低了图像识别的错误率第二名TOP-5错误率为26.2%(没有使用卷积神经网络),AlexNet获得冠军TOP-5错误率为15.3%。在这一突破之后,错误率下降到只有几个百分点(到2015年分类任务错误率只有3.6%)。
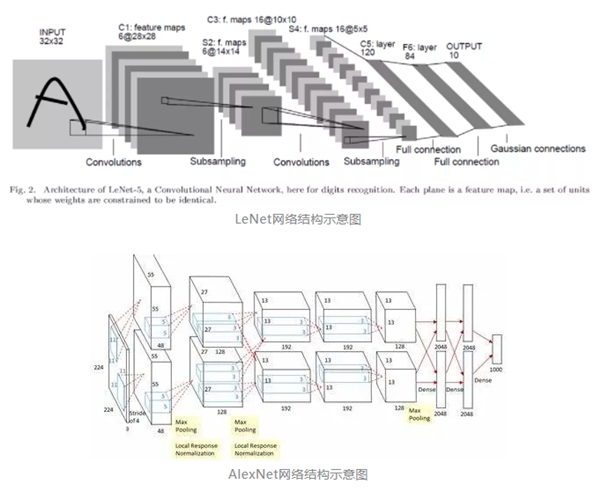
二、计算机视觉主要研究方向
人类应用计算机视觉解决的最重要的问题是图像分类、目标检测和图像分割,按难度递增,其中图像分割主要包含了语义分割、实例分割、全景分割。
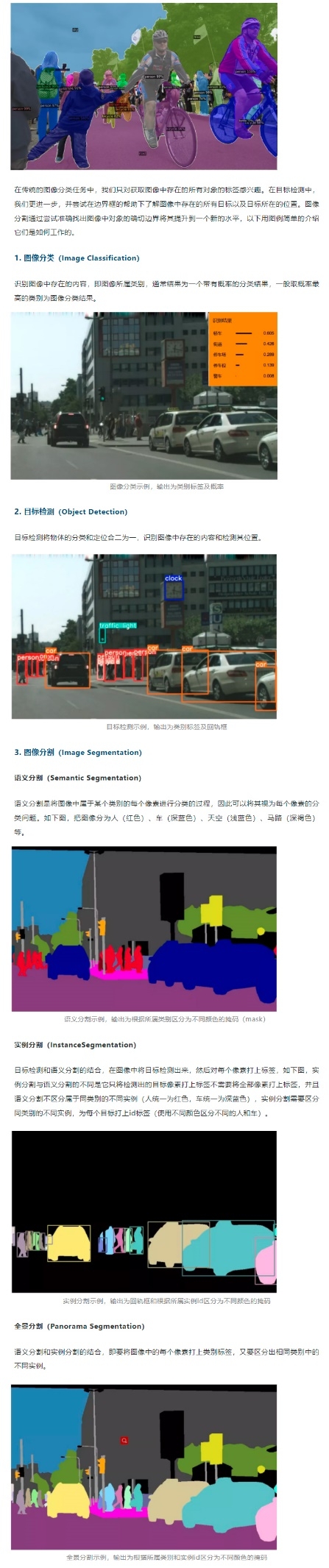
其中图像分类和目标检测也是很多计算机视觉任务背后的基础,接下来将简单地说明一下它们的运行原理。
(1)图像分类运行原理
图像分类的实现主要依靠基于深度学习的卷积神经网络。卷积神经网络是一类包含卷积计算且具有深度结构的前馈神经网络(Feedforward Neural Networks,FNN),是深度学习的代表算法之一 。卷积神经网络具有表征学习(Representationlearning)能力,能够按其阶层结构对输入信息进行平移不变分类(Shift-invariantclassification),因此也被称为“平移不变人工神经网络(Shift-Invariant Artificial Neural Networks, SIANN)” 。
那么人工神经网络(Artificial Neural Networks,ANN)又是什么呢,它是一种模仿生物神经网络(动物的中枢神经系统,特别是大脑)结构和功能的教学模型或计算模型,用于对函数进行估计或近似
人工神经网络由大量的人工神经元联结进行计算,大多数情况下人工神经网络能在外界信息的基础上改变内部结构,是一种自适应系统。
典型的人工神经网络具有以下三个部分:
网络结构:定义了网络中的变量和它们的拓扑关系;
激活函数:定义了神经元如何根据其他神经元的活动来改变自己的激励值;
学习规则:定义了网络中的权重如何随着时间推进而调整。
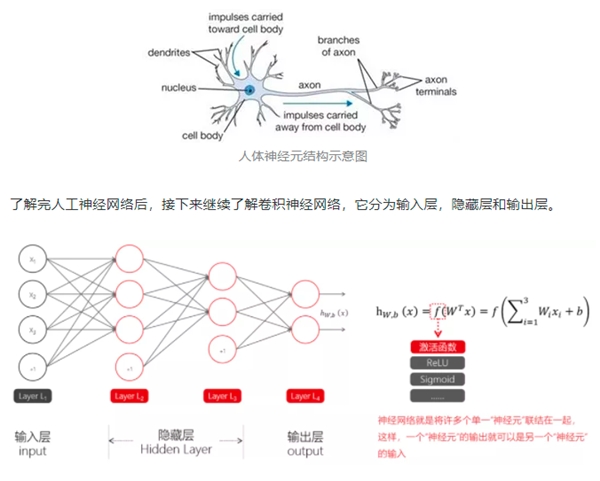
输入层
接收的是图像的三维数组,数组的形状大小为图像宽度、图像高度、图层数,数组的值为每一个图像通道逐个像素点的像素值。
隐藏层主要包括卷积层、池化层和全连接层
卷积层(Convolutional Layer)的功能是对输入数据进行特征提取,其内部包含多个卷积核,组成卷积核的每个元素都对应一个权重系数和一个偏差量,类似于一个前馈神经网络的神经元。卷积层内每个神经元都与前一层中位置接近的区域的多个神经元相连,区域的大小取决于卷积核的大小,也称作感受野,其含义可类比视觉皮层细胞的感受野。卷积核在工作时,会有规律地扫过输入特征,在感受野内对输入特征做矩阵元素乘法求和并叠加偏差量。卷积层还包括卷积参数和激励函数,使用不同的参数或函数,可以用来调节卷积层卷积后获得的结果。
在卷积层进行特征提取后,输出的特征图会被传递至池化层(Pooling Layer)进行特征选择和信息过滤。池化层包含预设定的池化函数,其功能是将特征图中单个点的结果替换为其相邻区域的特征图统计量,可降低图像参数,加快计算,防止过拟合。
卷积神经网络中的全连接层(Fully-connected Layer)等价于传统前馈神经网络中的隐含层。全连接层位于卷积神经网络隐含层的最后部分,并只向其他全连接层传递信号。特征图在全连接层中会失去空间拓扑结构,被展开为向量并通过激励函数。在一些卷积神经网络中,全连接层的功能可由全局均值池化(Global Average Pooling)取代,全局均值池化会将特征图每个通道的所有值取平均,可降低计算量,加快运行速度,防止过拟合。
输出层
卷积神经网络中输出层的上游通常是全连接层,因此其结构和工作原理与传统前馈神经网络中的输出层相同。对于图像分类问题,输出层使用逻辑函数或归一化指数函数(Softmax Function)输出分类标签。

三、计算机视觉前沿技术
随着计算机视觉技术的不断发展,除了图像分类,目标检测,图像分割等主要方向外还有很多新的技术不断产生,生成式对抗网络(Generative Adversarial Networks,GAN)就是其中一个非常有代表性的技术。
GAN是一种深度学习模型。模型通过框架中(至少)两个模块:生成模型(Generative Model)和判别模型(Discriminative Model)的互相博弈学习产生相当好的输出。原始 GAN 理论中,并不要求 G 和 D 都是神经网络,只需要是能拟合相应生成和判别的函数即可。但实用中一般均使用深度神经网络作为 G 和 D 。一个优秀的GAN应用需要有良好的训练方法,否则可能由于神经网络模型的自由性而导致输出不理想。
GAN的基本原理其实非常简单,这里以生成图片为例进行说明。假设我们有两个网络,G(Generator)和D(Discriminator)。正如它的名字,它们的功能分别是:
G是一个生成图片的网络,它接收一个随机的噪声z,通过这个噪声生成图片,记做G(z)。
D是一个判别网络,判别一张图片是不是“真实的”。它的输入参数是x,x代表一张图片,输出D(x)代表x为真实图片的概率,如果为1,就代表100%是真实的图片,而输出为0,就代表不可能是真实的图片。
在训练过程中,生成网络G的目标就是尽量生成真实的图片去欺骗判别网络D。而D的目标就是尽量把G生成的图片和真实的图片分别开来。这样,G和D构成了一个动态的“博弈过程”。
最后博弈的结果是什么?在最理想的状态下,G可以生成足以“以假乱真”的图片G(z)。对于D来说,它难以判定G生成的图片究竟是不是真实的,因此D(G(z)) = 0.5。
这样我们的目的就达成了:我们得到了一个生成式的模型G,它可以用来生成图片。

四、计算机视觉落地应用
计算机视觉的应用范围与规模是目前人工智能应用中最为广泛与普遍的,且早已深入日常生活与工作的多方面,典型的应用如生物特征识别中的人脸识别。
人脸识别已经广泛应用在人证比对、身份核验、人脸支付、安防管控等各个领域。

这是一个典型的人脸识别示例,通过人脸识别技术检测到图像中的人脸位置并识别出每个人脸是谁。
现在主流的人脸识别技术多使用黄种人和白种人的面部特征进行模型开发和训练,并且样本中的光照条件良好,因此可以从图片中较好的识别和分析黄种人和白种人的人脸,但是,由于深肤色(如黑人)人脸图像的纹理特征较不明显,并且反光较强,因此现有的人脸识别方法对深肤色人脸的识别和分析存在缺陷,尤其无法应对中偏重黑人人脸光照不佳的情况,不能在视频和照片中很好的识别和分析深肤色人脸,也就是说,现有的人脸识别方法很难对深肤色人脸的特征进行有效分析和提取,从而导致对深肤色人脸的识别准确率较低。
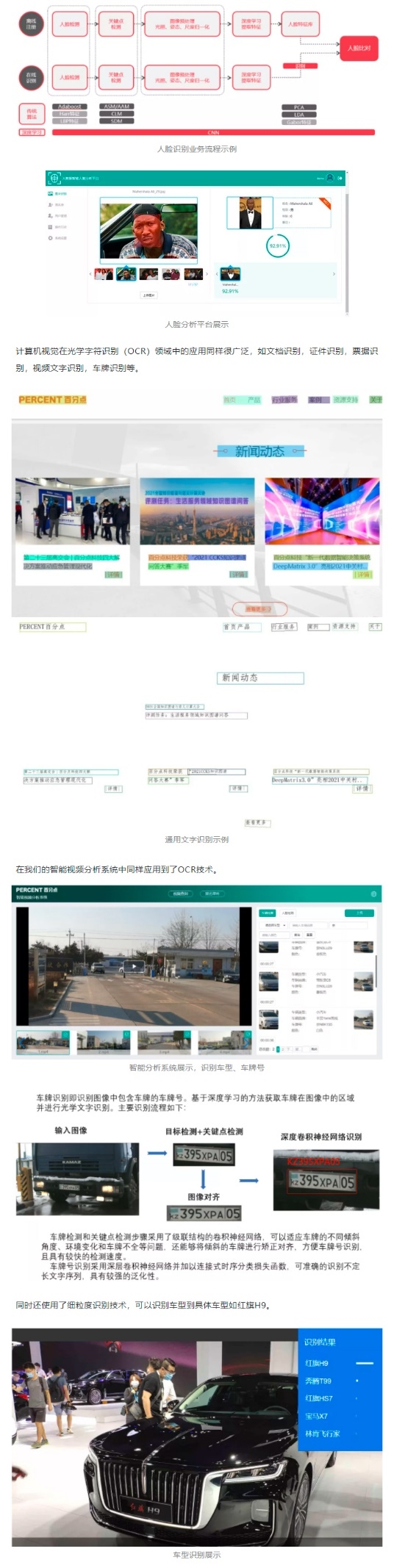
百分点科技采用了创新的方法,如增加拉普拉斯变换融合到图像图层等,采用基于深度学习的图像识别技术较好地解决了深肤色人种人脸识别的问题。具体主要流程如下:
(1)人脸检测
人脸检测和关键点检测步骤采用了级联结构的卷积神经网络,可以适应环境变化和人脸不全等问题,且具有较快的检测速度。
该方法规避了传统方法劣势的同时,兼具时间和性能两个优势。一张图片中绝大部分区域容易区分出为非人脸区域,只有少部分区域包含人脸和难以区分的非人脸区域。为加快检测速度,我们设计使用三级分类器,使得性能逐级提高。
一般算法中只包含一个回归器,如果候选框与真实人脸框相差较大,则无法进行有效的回归。我们使用多级回归器,每一级回归器皆可让结构更接近真实人脸框,在多级回归后结果更准确。
为实现对人脸/非人脸分类、人脸框回归、人脸关键点回归等预测,我们设计出基于多任务的深度学习模型。多任务学习提升了各个子任务的性能,达到一加一大于二的效果。在实现多任务共享深度学习模型参数的同时,较大地减少模型运算量,大幅提高人脸检测速度。
(2)人脸识别
特征提取步骤采用了深层次的残差卷积神经网络,且具有优化的损失函数,对比传统方法可以更快更好的提取人脸特征,增加类间距,减少类内距,获得更好的人脸识别效果。
该技术是在残差卷积神经网络的基础上,增加了更多的 Shortcut 网络连接与Highway 卷积层连接,保证了特征生成网络中能够兼具挖掘出人脸样本图像中的浅层与深层纹理特征,并将多重纹理特征进行组合,生成可分性更强的人脸特征,增强人脸识别准确率。同时在特征生成网络中加入了多尺度融合机制,在卷积层中加入多尺度视觉感受,保证了同一人在多方位图片中的人脸特征空间距离接近,有效提升同一分类的图像产生更好的聚类,进而提高人脸识别准确率。
针对不同肤色人种的人脸识别,尤其是深肤色人种,我们使用提取纹理通过对原始人脸图像进行拉普拉斯变换后得到的变换人脸图像描述人脸图像中的纹理强度,因此,由该原始人脸图像及该变换人脸图像进行拼接后得到的该四通道人脸图像,相比较于该原始人脸图像来说人脸纹理特征较明显,这样在基于深肤色人脸的该四通道人脸图像进行特征提取时,可以更高效地获取到人脸图像的纹理特征,进而可以提高对深肤色人脸识别的准确率。
总结
如今,计算机视觉已经广泛应用于人们日常生活的众多场景中。随着深度学习的飞速发展,计算机视觉融合了图像分类、目标检测、图像分割等技术,已在工业视觉检测、医疗影像分析、自动驾驶等多个领域落地应用,为各行各业捕捉和分析更多信息。
百分点科技在计算机视觉领域有着一定的研究和技术积累,并在人脸识别、文字识别、图像及视频智能分析等方面已经取得了不错的成绩,目前已在智慧园区、公共区域重点人员预警、车辆轨迹分析、河流水域智能监控、智能视频分析等多个场景中落地应用。未来,我们将加大力度,继续深入研究,进一步推动计算机视觉技术的发展,更好地为客户提供服务。
相关文章
- 费率再降0.3个百分点!海尔智家:持续转型,持续见效
- 海尔智家三季报费率优化0.3个百分点
- 百分点科技在共建“一带一路”中的实践
- 百分点科技&IDC联合发布数据科学基础平台白皮书
- 聚焦数智化转型 百分点科技2023数据科学峰会即将举办
- 百分点科技联合召开《中国应急管理发展报告(2022)》新书发布会
- 百分点科技荣获“上合国家软件产业国际合作优秀案例奖”
- 百分点科技数据科学产教融合计划继续扩大招募
- IDC发布中国智慧应急报告 大数据与人工智能市场百分点科技第二
- 2022年消费维权重点曝光行业有哪些 百分点科技联合数据猿发布预测报告
- 百分点科技:基于计算机视觉的语义分割技术如何在水域监控上发挥作用
- 8个月大增6.9个百分点,荣耀笔记本成2021中国轻薄本市场增速最快品牌
- 领先当前国际最优水平10.2个绝对百分点 这家企业再获“中国智能科学技术最高奖”
- 百分点感知智能实验室:计算机视觉理论和应用研究
- 百分点科技:声纹识别技术发展及未来趋势研究
- 百分点科技:基于NL2SQL的问答技术与实践





