喜马拉雅论文被ICASSP 2022收录 受邀展示自研跨语言语音合成技术
2022-01-26 09:56:08爱云资讯阅读量:1,089
近日,喜马拉雅自研的跨语言语音合成创新技术论文被2022年IEEE国际音频、语音与信号处理会议(2022 IEEE International Conference on Acoustics, Speech, and Signal Processing,ICASSP 2022)收录,并受邀于今年5月在新加坡举办的会议上向全球展示相关技术成果。

ICASSP是由IEEE(电气电子工程师学会)主办的在信号处理及其应用方面的顶级会议,在国际上享有盛誉并具有广泛的学术影响力。今年是ICASSP的第47届会议,会议主题为“以人为本的信号处理”。
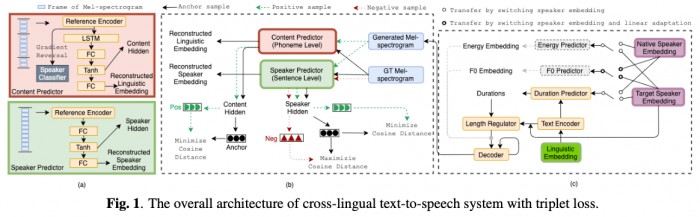
多语言建模已经成为语音合成系统必须拥有的能力。在实际的建模过程中,常需要根据单语种数据,构建一个拥有多语言能力的音色,比如需要能同时说中文和英文的某个音色,而该音色只有中文数据。针对这种情况,业界主流的建模方式是构建一个跨语言的语音合成系统,使该纯中文音色去学习另外一个带英文数据音色的英文能力。但该类跨语言语音合成系统在构建时往往有一些不足之处,比如学习到的英文发音不尽人意,或者由于学习英文发音,中文的韵律或者发音准确度下降,特别是在高表现力的音色建模上(如有声书朗读风格的音色)。为了进一步解决上述跨语言语音合成系统中所存在的问题,喜马拉雅在论文中提出了其自研的创新训练方法。
这一创新训练方法着眼于让模型能够接受所有音色和语言的组合的训练。例如音色A是一个纯中文数据,音色B是一个纯英文数据。在一些主流的跨语言语音合成系统的训练中,系统只能被<音色a,中文>和<音色b,英文>两种组合的数据进行训练。但是在实际语音合成推理中,却需要让音色A说英文(<音色a,英文>)和让音色B说中文(<音色b,中文>),而这两种组合都没有对应数据进行训练。此次喜马拉雅在论文中提出的方法,通过训练发音判别器和音色相似度判别器,使得系统不仅接受已有数据组合(<音色a,中文>,<音色b,英文>)的训练,也可以被跨语言数据组合(<音色a,英文>,<音色b,中文>)训练,从而使得训练和推理两个过程中的音色和语言组合完全对齐。
实验结果显示,新提出的方法不仅在跨语言可懂度上显著超越了基线模型,并且在保留音色相似度的前提下,也提升了跨语言语音合成的自然度。该方法不仅可以用在中英跨语言语音合成建模上,同样可以扩展到其他任何语言的建模上,例如方言跨语言迁移等。
喜马拉雅已在TTS(语音合成)领域潜心钻研多年,并在内部专门成立了喜马拉雅智能语音实验室这一核心部门,长期专注于语音合成、识别、语音信号处理、编解码以及智能音效的研究和开发,而这次的论文研究成果便来自于这一部门。目前,语音合成技术在喜马拉雅已经广泛被运用于评书、新闻、小说等多种内容的制作中,正助力喜马拉雅在现有的“UGC + PGC + PUGC”内容生态之外,进一步拓展AIGC的可能性。

2021年,喜马拉雅通过将自主设计单独的韵律提取模块融入到 HiTTS 技术框架,完美复现了单田芳的“声音”,目前已用单田芳的AI合成音上线了80张左右的“单田芳声音重现”专辑,其中,《毛氏三兄弟》和历史类作品的声音完播率远超过普通人声作品,为未来出版物大量有声化提供了新的解决方案。如今有了跨语言的语音合成技术,我们接下来将有望听到单田芳先生的“声音”来播讲英文内容。同时,2021年,还有新京报、环球时报、潇湘晨报、时代周报、海外网、刺猬公社等众多主流媒体入驻喜马拉雅,借助喜马拉雅TTS技术加速制作新闻类音频节目,让听众有了更多的渠道听到更权威的新闻。
未来,喜马拉雅将持续投入TTS技术的研发升级,不断打开对于声音的想象,让技术加持声音、让声音服务生活。





