格物钛:建立公开数据集标准,赋能AI工程化落地
2021-11-05 11:57:19爱云资讯阅读量:504
10月30日,由DataFun主办的AI基础软件架构峰会如约而至,格物钛作为AI基础设施领域的创业明星代表与谷歌、字节跳动、第四范式等顶尖科技公司一同亮相MLOps分论坛,格物钛算法负责人薛林继为线上观众带来了一场《建立公开数据集标准,赋能AI工程化落地》主题演讲。

过去十年,无论是阿尔法狗、自动驾驶,还是基因测序,人工智能技术已经开始走出实验室迎来了广泛的应用落地。在这些AI应用落地的背后隐藏了一套非常复杂的系统工程。除了算法的设计开发之外,也涵盖了定义问题,收集数据,特征工程,模型部署上线等各个环节。一套正确、简单、高效并且能规模化复制的算法需要对每一个环节做精细化治理,而非简单的工具链拼凑嫁接。
正如敏捷开发标准的建立帮助广大开发者实现了软件项目的高效敏捷迭代,k8s原生技术成为实施标准后使通用的应用开发编排伸缩变得更加简单。然而AI工程化领域尚未形成一套成熟的实施标准去帮助AI更好地落地。格物钛看到了数据对AI模型效果的重要性和数据获取的难点,为全球开发者、场景和数据的拥有者提供了一个公开数据托管和协作的平台并形成了一套与之匹配的数据使用标准。
格物钛薛林继认为,如果把数据比作食材,把模型比作厨艺的话,有一句话就可以非常好地去描述数据的重要性,那就是优质的食材往往只需要最朴素的烹饪方式。但无论从采集难度还是成本上来看,获取数据始终是个很困难的事情,因此很多研究机构和企业会选择求助于免费的公开数据集资源,很多顶尖的算法也都是以公开数据集作为标准诞生的。不可否认,公开数据集会成为未来AI创新的核心驱动力,它在很大程度上解决了数据获取的难题,同时以自己的形式构建新类型任务,去推动不同算法的发展。
经过很长一段时间的调研,格物钛发现现有公开数据集的存储方式十分散乱,缺乏统一的托管平台,这种各自为战的方式使得不同的数据集提供方会选择使用不同的文件结构和标注方式,这对数据的交换与分享是极为不利的,开发者很难根据自己的任务去精确检索到自己想要的数据集。像可视化、数据标签分布统计这些基础需求的实现都会因为格式不同发生一些变化,算法工程师需要编写更多的胶水代码和新的逻辑去适配这些不同的格式。
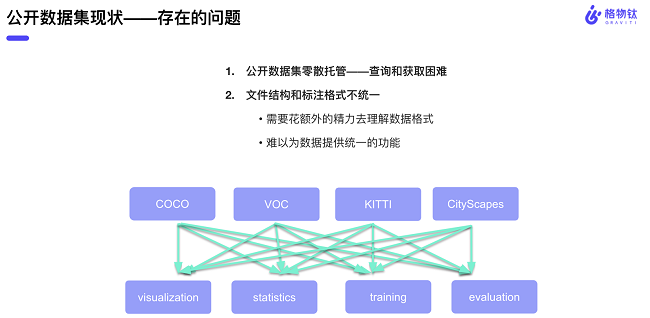
基于对上述痛点的洞察,格物钛认为需要建立一个统一的数据标准来降低数据理解和使用成本,从而去提升整个社区、企业内部的数据交换效率。
格物钛研究了1200多个公开数据集,从数据格式、标注类型、任务类型以及应用场景这四个方面制定了统一的数据集划分规范和标注格式的基础表示方法。在实施的过程中,格物钛将很多类型的数据集放在了公开数据集社区中,目前为止这套标准也是取得了很多社区成员的认可。在推广公开数据集标准的过程中,格物钛发现数据处理是需要很多基础服务的,这些基础服务可以通过数据平台的形式来实现,去解决企业在数据管理层面的痛点。
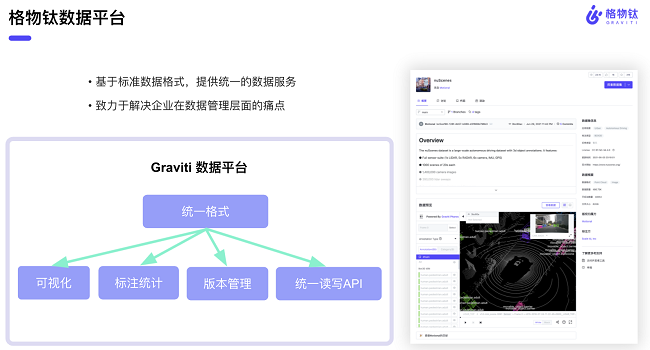
格物钛算法负责人薛林继认为公开数据集社区和数据标准的建立与推广是一个相辅相成的关系,社区为数据标准迭代提供了一个良好的实验环境,每当有一个新的数据集登录到格物钛公开数据社区的时候,都是对当前的数据标准做了一次检验。
格物钛公开数据集社区发展至今依旧面临不小挑战。首先数据集的种类太多,新的数据集层出不穷,只依靠单方的力量去制定标准很难跟得上最新的任务类型和数据种类。其次在一些企业端的场景中,企业数据并不需要去适配公开数据集的标准,用自己的标准就可以满足任务场景的需求。因此,公开数据集标准的设计也需要支持让使用的人自定义标准格式,然后以这种方式去适配多变的数据需求。薛林继在此呼吁希望不断有新的力量加入到社区建设中来,推动数据标准的迭代和演进,共同打造下一代公开数据集标准。
相关文章
- 英特尔® 至强® 可扩展处理器:重塑数据库性能的未来
- 合肥市瑶海区委书记陆勤山一行莅临谷器数据考察交流
- 《The Power of Datafication》作者郭为:数字化不是信息化,数据资产是核心
- 互联网30载,与NAS共筑数据存储新生态
- 刘东:构建跨境数据空间 加速粤港澳大湾区数据流动
- 大连万达x思迈特 | 建立以数据驱动业务的数据化运营体系
- 鲲鹏原生赋能浩瀚深度,网络数据可视化处理更加高效
- 航天信息爱信诺·信易安:跨界亮相,让数据交换更安全、更便捷
- 铁威马F6-424 MAX:引领企业数据管理新潮流
- 广州车展丨车凌科技和EMQ 映云科技就车云数据一体化平台达成合作
- 尼尔森数据背后:Shokz韶音如何在全球运动耳机市场脱颖而出
- AI大数据加速发展,佳都科技参股公司睿帆科技获评国家级专精特新“小巨人”
- 开源数据库 KWDB 获评 GVP-- Gitee 最有价值开源项目
- 抖音电商双11数据发布:“以旧换新”促消费,洗烘套装成交额同比增长202%
- 广发银行行业云:数据驱动运维,智能引领未来
- 中国电信邵广禄:AI和数据驱动,加速高质量发展





