人工神经网络秒变脉冲神经网络,新技术有望开启边缘AI计算新时代
2021-05-06 09:17:33爱云资讯850
能更好模仿生物神经系统运行机制的脉冲神经网络在发展速度和应用范围上都还远远落后于深度学习人工神经网络(ANN),但脉冲神经网络的低功耗特性有望使其在边缘计算领域大放异彩。近日,奥地利的格拉茨技术大学理论计算机科学学院的两位研究者提出了一种可将人工神经网络转换为脉冲神经网络(SNN)的新方法,能够在保证准确度的同时有效地将 ANN 模型转换成 SNN 模型。该技术有望极大扩展人工智能的应用场景。
现代人工智能还难以在边缘设备中广泛应用,而脉冲神经网络(Spiking neural network, SNN)有望突破造成这一困境的主要难题:基于深度学习的当前 SOTA 大型人工神经网络(ANN)的能量消耗。
尤其是卷积神经网络(CNN),其已经在图像分类以及其它一些应用领域得到了广泛使用。为了实现卓越的性能,这些 ANN 必须规模庞大,因为它们需要足够多的参数才能从训练所用的大型数据集中吸收足够信息。举个例子,ImageNet2012 数据集有 120 万张图像。如果使用标准硬件来实现这些大型 ANN,那么得到的实现结果本质上就具有很高的能耗。
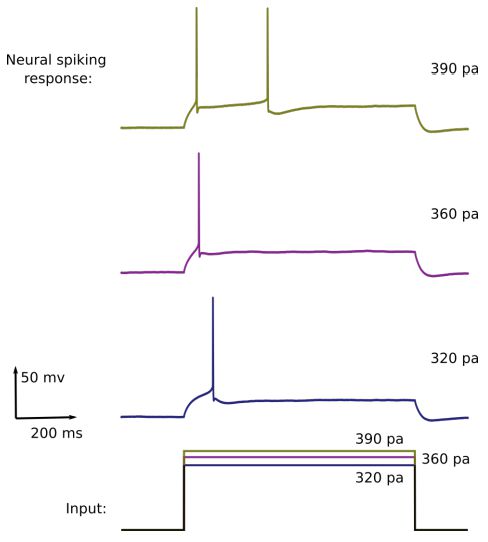
脉冲神经元(Spiking neuron)已经成为开发用于 AI 的全新计算硬件的核心,其有望极大降低能量预算。部分原因是人脑的巨型 SNN(包含约 1000 亿个神经元)的功耗仅为 20 W。脉冲神经元的输出是一系列定型脉冲。因此,它们的输出与 ANN 神经元的输出非常不同,ANN 神经元的输出是连续数值。大多数脉冲神经元模型都可视为神经形态硬件的实现,它们的设计灵感都来自大脑脉冲神经元的简单模型。但是,这些简单的神经元模型不同于生物神经元,并不具备通过不同的时间脉冲模式来编码不同输入的能力——只靠发射率是不行的(下图 1 给出了一个示例)。
此外,大型 ANN 通常会使用越来越复杂精细的深度学习算法来在巨型数据集上进行训练,由此得到的模型能在一些智能任务类别中接近甚至有时还能超过人类表现,但当前一代基于脉冲的神经形态硬件的表现却落后了。对于当前脉冲神经网络的这种情况,还是有希望追赶上大型 ANN 的,因为这些可以直接训练以实现当前 ANN 的大部分性能。
但对于前馈网络而言,如何仅使用少数脉冲来实现与 ANN 性能相近的 SNN,这个问题依然存在。能实现非常好的图像分类准确度的前向 CNN 往往很深很大,而训练对应深度和宽度的前向 SNN 却无法取得类似的分类准确度。研究者认为,可能的原因包括在所得 SNN 的较高层面上的脉冲出现时间问题以及发射率精度问题。一种吸引人的做法是直接将一个表现优异、已训练完成的 CNN 转换成 SNN——使用同样的连接和权重。最常用而且到目前为止也是表现最好的转换方法是基于发射率编码的思想,这种方法是通过脉冲神经元的发射率来仿真 ANN 单元的模拟(analog)输出。该方法已经造就了到目前为止在图像分类任务上表现最好的 SNN。但要通过发射率来传输模拟值,往往需要相当多的脉冲,而这又会拖累网络的延迟和吞吐量。
此外,由于所得到的 SNN 往往会产生非常多脉冲,因此其相对于非脉冲硬件的能耗优势也将荡然无存。最后,基于发射率的 ANN 到 SNN 转换方法无法用于那些在 ImageNet、EfficientNet 上取得了最高准确度的 ANN,因为这些方法使用了会假设正值和负值的激活函数:SiLU 函数。
针对这些难题,奥地利格拉茨技术大学理论计算机科学学院的两位研究者提出了一种新型的 ANN 转 SNN 方法。他们称之为 FS 转换,其中 FS 是 Few Spikes 的缩写,即其仅需一个脉冲神经元发射少数几个脉冲。这种方法与基于发射率的转换方法完全不同,并且使用了带有脉冲模式的时间编码选项,其中脉冲的时间可以传输额外的信息。

论文:https://arxiv.org/abs/2002.00860
代码:https://github.com/christophstoeckl/FS-neurons
事实证明,之前人们提出的大多数时间编码形式都难以在神经形态硬件中高效地实现,因为这需要将脉冲之间精细的时间差传递到下游神经元。相较而言,FS 转换的实现仅需使用 log N 个不同值的脉冲时间以及最多 log N 个用于传输 1 到 N 之间的整数的脉冲。在实践中,所需的脉冲数量甚至还可以更少,因为并非所有 N 个值的出现几率都是均等的。但是,FS 转换需要一种修改版的脉冲神经元模型——FS 神经元,该神经元的内部动态针对使用少数脉冲仿真特定类型的 ANN 神经元进行过优化。
研究者使用 FS 转换通过 CNN 得到了一些 SNN 并在 ImageNet2012 和 CIFAR10 这两个图像分类数据集上进行了测试验证。他们表示:这种优化版脉冲神经元模型可以用于指引下一代神经形态硬件的研发。
如何使用脉冲很少的脉冲神经元仿真 ANN 神经元?
ANN 转 SNN 的 FS 转换需要将标准的脉冲神经元模型转换成这里提出的 FS 神经元。下图 2a 展示了 ANN 的一个通用型人工神经元的计算步骤,图 2b 则是通过 K 个时间步仿真它的 FS 神经元。其内部动态由固定的参数 T(t)、h(t)、d(t) 定义,其中 t=1,...,K。这些参数经过优化,以通过脉冲的加权和 。
来仿真给定 ANN 神经元的激活函数 f(x)。z(t) 是指脉冲神经元产生的脉冲序列。更确切地说:如果该神经元在步骤 t 发射,则 z(t)=1;否则 z(t)=0。要在时间 t 发射出脉冲,神经元的膜电位 v(t) 必须超过其发射阈值的当前值 T(t)。
研究者假设膜电位 v(t) 不漏电,但在时间 t 的脉冲之后会被重置为 v(t)−h(t)。用公式表示的话,膜电位 v(t) 的初始值为 v(1)=x,其中 x 是门的输入,然后基于以下公式在 K 个步骤中不断演变:
对于门输入 x,FS 神经元的脉冲输出 z(t) 可以紧凑地定义为:
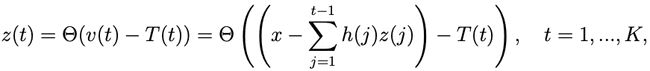
其中 Θ 表示 Heaviside 阶跃函数。FS 神经元在这 K 个时间步骤的总输出会被下一层的 FS 神经元收集。这个总输出可写为:
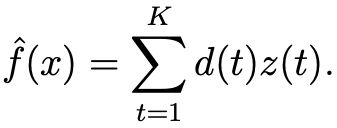
图 2b 为其模型的示意图。
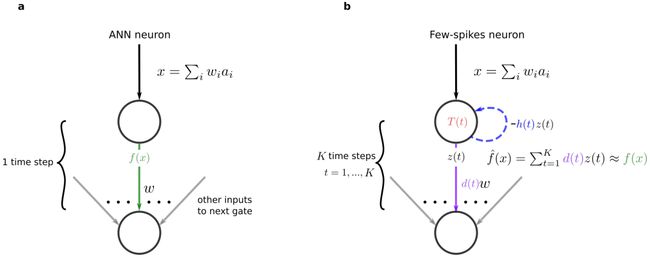
图 2:ANN 神经元到 FS 神经元的转换。a)一个激活函数为 f(x) 的一般 ANN 神经元;b)用 K 个时间步骤仿真这个 ANN 神经元的 FS 神经元,其输出序列表示为 z(t)。
为了仿真 ReLU 激活函数,可以选择 FS 神经元的参数,使得它们可以为位于某个上限值之下所有输入值 x 定义一个由粗到细的处理策略。为了仿真 EfficientNet 的 SiLU 函数,可以实现更好的 FS 转换,即选择参数的方式要使得:对于 EfficientNet 中作为门输入 x 最常出现的 -2 到 2 范围内的输入,它们可以实现迭代式的,也因此更加精确的处理。下图 3 展示了 FS 神经元在 SiLU 和 sigmoid 激活函数情况下所得到的动态。
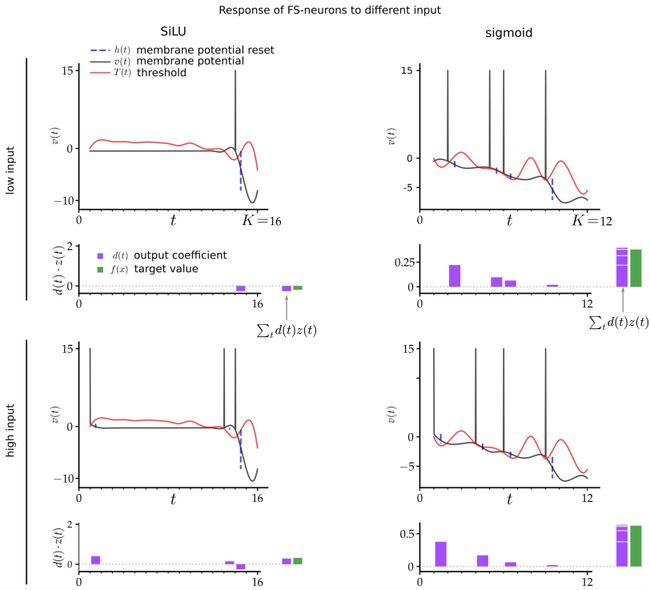
图 3:FS 神经元的内部动态。第一行是 FS 神经元对一个较低输入值(x=-0.5)的响应,第二行则是其对一个较高输入值(x=0.5)的响应。第一列展示了 SiLU FS 神经元的响应,第二列则是 sigmoid FS 神经元的响应。为便于说明,离散时间步骤 t 中 T(t) 和 v(t) 的相关值是平滑插值的。
所有使用同一激活函数仿真 ANN 神经元的 FS 神经元都可使用同样的参数 T(t)、h(t)、d(t),而它们的输出脉冲的权重中的因数 w 可以从训练得到的 ANN 中相应突触连接中简单地提出来。
使用 FS 转换方法时,网络中神经元和连接的数量都不会增加。但一个 L 层前馈 ANN 的计算步骤数 L 会增大 K 倍。但 ANN 的计算能以一种管道流程化的方式仿真,而 SNN 会每 2K 个时间步处理一个新的网络输入(图像)。在这种情况下,FS 神经元的参数会随着 FS 神经元计算而周期性变化,周期长度为 K。这 K 个步骤之后会跟着 K 个 FS 神经元不活跃的时间步,而下一层的 FS 神经元会收集它们的脉冲输入来仿真 ANN 的下一个计算步骤或计算层。请注意,由于所有使用同一激活函数仿真 ANN 神经元的 FS 神经元都可使用同样的参数 T(t)、h(t)、d(t),因此它们在神经形态芯片上仅需少量额外内存。
FS 神经元的 TensorFlow 代码和所选参数都已发布在 GitHub。
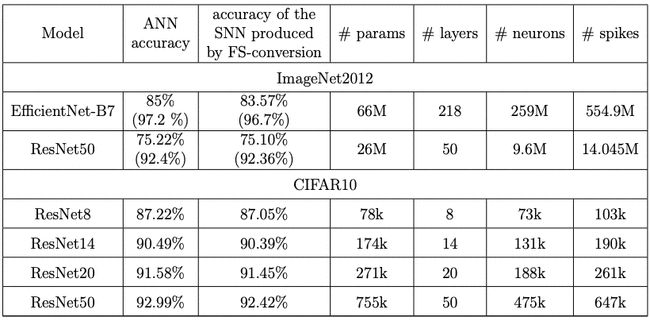
表 1:对两个当前最佳的 CNN 使用 FS 转换,基于 ImageNet 分类图像的准确度和脉冲数量。通过 FS 转换而得到的 SNN 几乎实现了与对应 ANN 一样的准确度,而且每个神经元通常最多使用 2 个脉冲。括号中的数据是 Top5 准确度。推理所需的脉冲数量数据是在 1000 张测试图像上得到的平均值。





