谷歌发布新一代定向人声分离系统,2.2MB模型提升设备端语音识别
2020-11-16 11:38:39爱云资讯1136
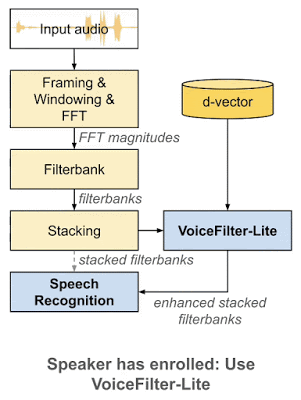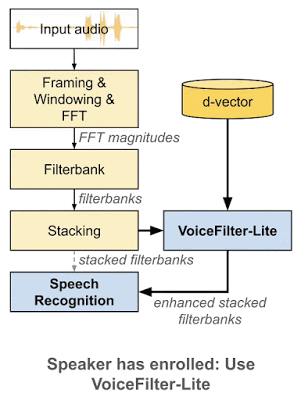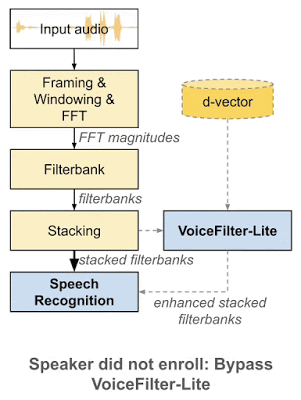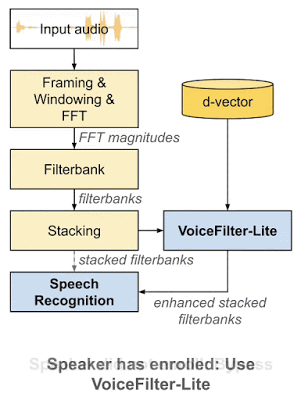
2018 年,谷歌科学家王泉等人发表 VoiceFilter
系统,利用声纹识别实现定向人声分离。最近,王泉等人挑战设备端语音识别难题,提出新一代定向人声分离系统 VoiceFilter-Lite,只需
2.2MB 大小的模型,就能将重叠语音的词错率(word error rate)降低 25.1%。
鸡尾酒会问题一直是语音识别领域中的重要研究课题。在一场人声嘈杂的鸡尾酒会上,人们难以专注于眼前正与自己交谈的那个人的声音。而对于语音识别算法而言,重叠语音信号会使识别准确率大幅降低,甚至有时无法识别出任何文字。
传统的声源分离算法在用于语音识别时,往往面临挑战,例如未知的说话人数量、训练过程中的置换不变性(Permutation Invariant),以及如何从最终分离的多个信号源中找出需要识别的信号源。谷歌 2018 年发表的 VoiceFilter 系统,巧妙地利用声纹识别技术,实现了对特定说话人声音的定向分离,详见机器之心 2018 年的报道:。
VoiceFilter 系统处理重叠语音的示例。
然而,VoiceFilter 系统在用于设备端语音识别时,会面临更多挑战,例如模型大小的限制、对 CPU 和内存的占用,以及设备电池和系统延迟方面的考量。
为解决这些问题,近日谷歌发布博客,介绍了新一代定向人声分离系统 VoiceFilter-Lite。该方法同样基于谷歌的声纹识别技术,但只需要 2.2MB 大小的模型,就能将重叠语音的词错率(word error rate)降低 25.1%。该模型能够用于设备端语音识别,从而让用户在没有网络连接的情况下,也能在嘈杂的背景噪声环境下使用语音助手。
VoiceFilter-Lite 在设备端的使用 demo。
VoiceFilter-Lite 模型:改善设备端语音识别
与之前的 VoiceFilter 系统相比,新的 VoiceFilter-Lite 模型采用了许多巧妙的优化。例如,模型的输入和输出不再是音频波形,而是直接对语音识别模型的输入特征(对数梅尔滤波器组)进行分离,将该特征中不属于目标说话人的成分滤除掉。为进一步压缩模型大小,VoiceFilter-Lite 对模型结构也进行了优化,并通过 TensorFlow Lite 库,对参数进行了量化。模型架构如下图所示:
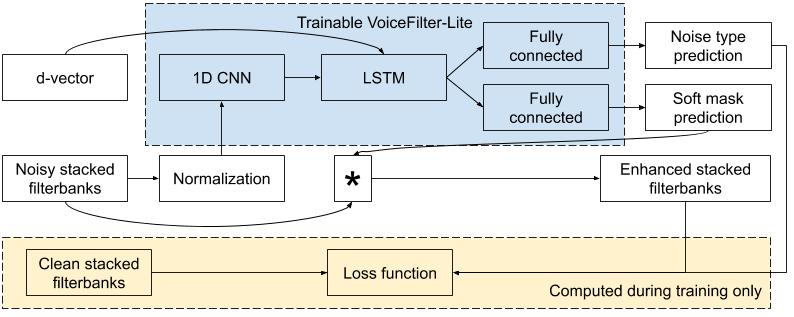 VoiceFilter-Lite 模型架构。
VoiceFilter-Lite 模型架构。
VoiceFilter-Lite 与其他方法相比,一个重要优势在于「即插即用」的特性。也就是说,如果用户没有录入其声纹,系统可以很方便地跳过 VoiceFilter-Lite 模型。因此,VoiceFilter-Lite 模型可以和语音识别模型分别进行训练与更新,这将大幅简化语音模型的工程部署工作。
 如何解决过度抑制问题
如何解决过度抑制问题
人声分离算法被用于语音识别时,一个常见的问题是过度抑制(over-suppression),也就是将本应保留的部分有用信号错误地过滤掉,导致识别出的文本缺失大量字词。由于最近的语音识别模型普遍采用大量数据增强方法,所以过度抑制造成的问题远大于抑制不足(under-suppression)。
VoiceFilter-Lite 在设计过程中采用了两种方法来解决过度抑制的问题。首先,在训练过程中,损失函数采用了非对称的形式,也就是过度抑制相比抑制不足会有更大的权重。此外,模型被设计为可以动态检测重叠语音的存在。当检测到输入信号包含重叠语音时,模型将采用更大的抑制强度。
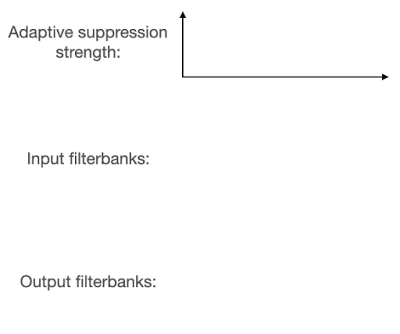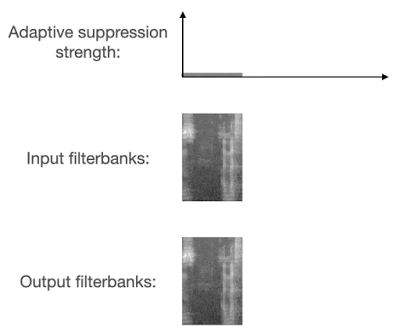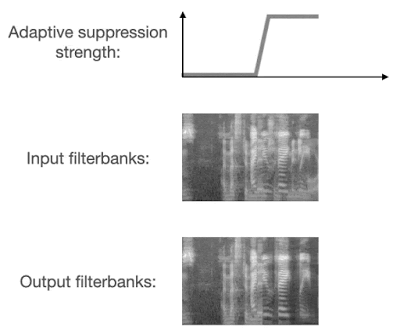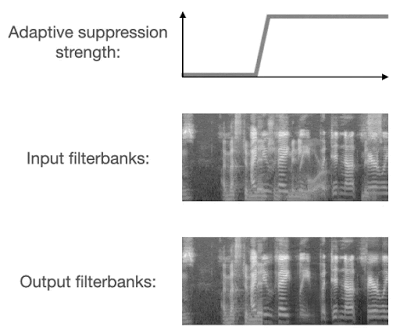 这两种方法的结合使用,让 VoiceFilter-Lite 模型不仅能大幅提升重叠语音的识别准确率,还能在任何其他环境下都不对识别准确率造成负面影响,包括各种噪声背景下的单说话人语音识别场景。
这两种方法的结合使用,让 VoiceFilter-Lite 模型不仅能大幅提升重叠语音的识别准确率,还能在任何其他环境下都不对识别准确率造成负面影响,包括各种噪声背景下的单说话人语音识别场景。
未来工作
鸡尾酒会问题一直是语音识别领域中的重要研究课题。在一场人声嘈杂的鸡尾酒会上,人们难以专注于眼前正与自己交谈的那个人的声音。而对于语音识别算法而言,重叠语音信号会使识别准确率大幅降低,甚至有时无法识别出任何文字。
传统的声源分离算法在用于语音识别时,往往面临挑战,例如未知的说话人数量、训练过程中的置换不变性(Permutation Invariant),以及如何从最终分离的多个信号源中找出需要识别的信号源。谷歌 2018 年发表的 VoiceFilter 系统,巧妙地利用声纹识别技术,实现了对特定说话人声音的定向分离,详见机器之心 2018 年的报道:。
VoiceFilter 系统处理重叠语音的示例。
然而,VoiceFilter 系统在用于设备端语音识别时,会面临更多挑战,例如模型大小的限制、对 CPU 和内存的占用,以及设备电池和系统延迟方面的考量。
为解决这些问题,近日谷歌发布博客,介绍了新一代定向人声分离系统 VoiceFilter-Lite。该方法同样基于谷歌的声纹识别技术,但只需要 2.2MB 大小的模型,就能将重叠语音的词错率(word error rate)降低 25.1%。该模型能够用于设备端语音识别,从而让用户在没有网络连接的情况下,也能在嘈杂的背景噪声环境下使用语音助手。
VoiceFilter-Lite 在设备端的使用 demo。
VoiceFilter-Lite 模型:改善设备端语音识别
与之前的 VoiceFilter 系统相比,新的 VoiceFilter-Lite 模型采用了许多巧妙的优化。例如,模型的输入和输出不再是音频波形,而是直接对语音识别模型的输入特征(对数梅尔滤波器组)进行分离,将该特征中不属于目标说话人的成分滤除掉。为进一步压缩模型大小,VoiceFilter-Lite 对模型结构也进行了优化,并通过 TensorFlow Lite 库,对参数进行了量化。模型架构如下图所示:
VoiceFilter-Lite 与其他方法相比,一个重要优势在于「即插即用」的特性。也就是说,如果用户没有录入其声纹,系统可以很方便地跳过 VoiceFilter-Lite 模型。因此,VoiceFilter-Lite 模型可以和语音识别模型分别进行训练与更新,这将大幅简化语音模型的工程部署工作。
人声分离算法被用于语音识别时,一个常见的问题是过度抑制(over-suppression),也就是将本应保留的部分有用信号错误地过滤掉,导致识别出的文本缺失大量字词。由于最近的语音识别模型普遍采用大量数据增强方法,所以过度抑制造成的问题远大于抑制不足(under-suppression)。
VoiceFilter-Lite 在设计过程中采用了两种方法来解决过度抑制的问题。首先,在训练过程中,损失函数采用了非对称的形式,也就是过度抑制相比抑制不足会有更大的权重。此外,模型被设计为可以动态检测重叠语音的存在。当检测到输入信号包含重叠语音时,模型将采用更大的抑制强度。
未来工作
最后,博客作者、谷歌声纹识别与语言识别团队负责人王泉指出,目前的 VoiceFilter-Lite 技术只被应用于提升英语的语音识别,未来谷歌将会用相同的技术提升其他语言的语音识别。另外,作者考虑在 VoiceFilter-Lite 的训练过程中直接对语音识别损失函数进行优化,从而进一步提升各种环境下的识别准确率。
相关文章
- 三星与谷歌联手开发AR眼镜,Meta/微美全息硬件先行共绘XR未来蓝图
- 谷歌量子芯片重磅登场掀热潮,微美全息持续打造量子“芯”质生产力
- Meta携手卡梅隆共铸3D沉浸世界,谷歌/微美全息创新引领全息虚拟新纪元
- 抢先OpenAI Sora谷歌新推Veo模型,亚马逊/微美全息加入AI视频生成竞赛引关注
- 谷歌DeepMind发布Gemini 2.0人工智能模型
- 2025年AI Agent商用蓄势待发,微软/谷歌/微美全息纷纷入局重塑AI全产业链
- 谷歌发布突破性量子计算芯片Willow:五分钟完成超算10的25次方年的计算
- 预报天气更快、更准确!谷歌发布AI天气预测模型GenCast
- 谷歌文生视频模型Veo私人预览版在Vertex AI平台上线
- 谷歌Gemini作为原生应用登陆iPhone
- 谷歌推出Learn About实验性新AI工具,重塑学习新方式
- ChaGPT网页搜索引擎上线 OpenAI挑战谷歌
- 谷歌超过四分之一的新代码是由人工智能生成
- Meta在开发自己的人工智能搜索引擎,减少对谷歌和微软的依赖
- 谷歌宣布开源水印识别工具SynthID,可供开发人员和企业免费使用
- 谷歌将于11月21日起从搜索结果中移除站点链接搜索框





