复杂应用中运用人工智能核心 强化学习
2020-07-27 10:28:34爱云资讯阅读量:516
近期,有不少报道强化学习算法在 GO、Dota 2 和 Starcraft 2 等一系列游戏中打败了专业玩家的新闻。强化学习是一种机器学习类型,能够在电子游戏、机器人、自动驾驶等复杂应用中运用人工智能。在状态和动作空间较大、环境信息不完善并且短期动作的长期回报不确定的游戏中,这些程序可以找出最佳动作。
不只是游戏王者,强化学习作为机器学习的一个分支,在真实系统设计中,它能帮助您针对复杂系统(如机器人和自主系统)实现控制器和决策系统。借助深度强化学习,您可以实现深度神经网络,这类网络运用通过仿真模型动态生成的数据进行训练,从而学习复杂行为。您只需准备一个仿真模型来表示您正在与之交互并尝试控制的环境,而无需提供标注或者未标注的预定义训练数据集。
MATLAB 和 Simulink 支持设计和部署基于强化学习的控制器的整套工作流。您可以:
通过简单的控制系统、自主系统和机器人示例,初步了解强化学习
在常见强化学习算法间快速切换并加以评估和比较,只需对代码稍加改动即可实现
使用深度神经网络,根据图像、视频和传感器数据定义复杂强化学习策略
使用本地核心或云并行运行多个仿真,加速完成策略训练
将强化学习控制器部署到嵌入式设备
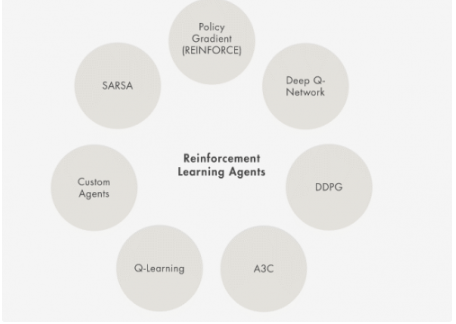
强化学习智能体(agent)
强化学习智能体由策略和算法构成,策略用于执行从输入状态到输出动作的映射,算法负责更新策略。常见算法包括深度 Q 网络、Actor-Critic 和深度确定性策略梯度。算法会更新策略,使之最大化环境提供的长期奖励信号。策略可通过深度神经网络、多项式或查找表进行表达。然后,您可以将内置智能体和自定义智能体作为 MATLAB 对象或 Simulink 模块加以实现。
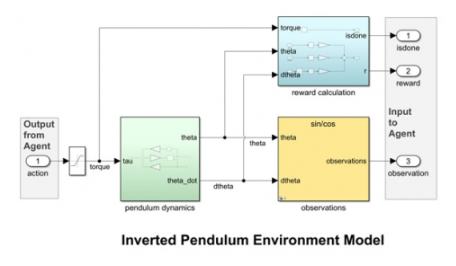
在 MATLAB 和 Simulink 中进行环境建模
强化学习算法训练是一个动态过程,因为智能体需要与周边环境进行交互。对于机器人和自主系统等应用形式,在真实环境中使用实际硬件开展此类训练不仅代价高昂,还可能面临危险。正因如此,人们倾向于采用通过仿真生成数据的虚拟环境模型来开展强化学习。您可以在 MATLAB 和 Simulink 中构建环境模型,以此描述系统动态、智能体的行动对系统动态产生的影响,以及用于评估所采取行动优度的奖励。这些模型在本质上可以是连续的或者离散的,可以采用不同的保真度来表示系统。此外,您也可以通过并行仿真来加快训练。在某些情况下,您还可以重用现有的 MATLAB 和 Simulink 系统模型,只需稍加改动即可将其用于强化学习。
相关文章
- 全球人工智能峰会呼吁全球行动,确保人工智能创新“造福人类”
- 微软推出Copilot Pages功能,为企业打造的新型协作式人工智能平台
- 2024年全球人工智能峰会闭幕日继续改变数据和人工智能格局
- 合合信息上市:专注人工智能及大数据科技,C端产品月活过亿
- TCS在2024年服贸会上发布《人工智能商业应用研究报告 》,揭示AI对企业变革的深远影响
- 标贝科技亮相深圳国际人工智能展 并荣获最佳行业应用标杆奖
- 曼孚科技完成数亿元B++轮融资,以大模型重构人工智能生产新范式
- 探索未来智慧的边界:“纵横”论坛人工智能安全论坛圆满举行
- 九四智能受邀亮相第五届深圳国际人工智能展
- 2024年人工智能技术赋能网络安全应用测试结果公布:安恒信息恶意软件检测场景排名第一
- 好评+2!相芯数字人荣获最佳行业标杆应用、最受欢迎人工智能产品两大奖项
- 第九届“创客中国”生成式人工智能(AIGC)中小企业创新创业大赛圆满落幕
- AMD新战略放弃旗舰级游戏显卡,专注于人工智能领域
- 海淀工匠学院揭牌暨第四届“海淀工匠杯”职工职业技能大赛人工智能应用与网络安全职业技能竞赛启动仪式圆满举行
- 广东省通信学会人工智能专业委员会成立大会暨人工智能技术论坛9月9日隆重举行!
- 对“开源”的新定义可能给大型人工智能公司带来不利





