深度揭秘AI换脸原理,为啥最先进分类器也认不出?
2020-04-20 16:47:19爱云资讯阅读量:527

4月20日消息,AI换脸已不是新鲜事,手机应用市场中有多款换脸app,此前也曾曝出有网络IP用明星的面孔伪造色情影片、在大选期间用竞选者的脸制作虚假影像信息等。
为了规避Deepfake滥用带来的恶性后果,许多研究者尝试用AI技术开发鉴定分类器。
然而,谷歌公司和加州大学伯克利分校的研究人员最近的研究显示,现在的鉴定技术水平还不足以100%甄别出AI换脸作品。另一项由加州大学圣地亚哥分校主导的研究也得出了相同结论。
这些研究结果为我们敲响了警钟,要警惕AI换脸制作的虚假信息。
目前谷歌和加州大学伯克利分校的研究已经发表在学术网站arXiv上,论文标题为《用白盒、黑盒攻击绕过Deepfake图像鉴别工具(Evading Deepfake-Image Detectors with White- and Black-Box Attacks)》

一、实验准备:训练3种分类器,设置对照组
实现AI换脸的技术被称为Deepfake,原理是基于生成对抗网络(generative adversarial networks,GAN)合成虚假图片。GAN由一个生成网络和一个判别网络组成。
GAN模型的学习过程就是生成网络和判别网络的相互博弈的过程:生成网络随机合成一张图片,让判别网络判断这张图片的真假,继而根据判别网络给出的反馈不断提高“造假”能力,最终做到以假乱真。
研究人员共对3个分类器做了测试,其中两个为第三方分类器,一个为研究人员训练出的用于对照的分类器。
选用的第三方分类器分别采用两种不同训练方式。
第一个分类器模型基于深度残差网络ResNet-50(Deep residual network)。
用到的ResNet-50预先经过大型视觉数据库ImageNet训练,接下来再被训练用于辨别真假图像。采用包含720000个训练图像、4000个验证图像的训练集,其中一半为真实图像,另一半是用ProGAN生成的合成图像。合成图像采用空间模糊和JEPG压缩方法增强。
经过训练后,这个分类器能准确识别出ProGAN生成的图像,而且还能分类其他未被发现的图像。
第二个鉴定分类器采用的是基于相似性学习(similar learning-based)的方法。经过训练后这款分类器可以准确辨认出由不同生成器合成的图像。
研究团队还自己搭建了一个鉴定分类器模型,作为前述两个鉴定分类器的对照示例。这个分类器采用100万个ProGAN生成的图像进行训练,其中真假图像各占一半。论文中指出,这个分类器的训练管道比前述两种简单很多,因此错误率也更高。
研究人员根据分类器是否开放了访问权限,选用了不同的攻击方式。对开发访问权限的分类器采用白盒攻击;对不开放访问权限的分类器采用黑盒攻击。
另外,研究人员用接收者操作特征曲线(ROC曲线)评估分类器的正确率。评估标准是曲线下面积(AUC)的大小。AUC的取值范围为0~1,一般来说AUC>0.5即代表分类器有预测价值,AUC值越大代表分类器准确率越高。
二、4种白盒攻击方法,AUC最低被降至0.085
对于开放了访问权限的分类器,研究人员用白盒攻击评估其稳健性。
白盒攻击即攻击者能够获知分类器所使用的算法以及算法使用的参数。在产生对抗性攻击数据的过程中,攻击者能够与分类器系统产生交互。
攻击过程中用到的所有图像都来自一个包含94036张图像的视觉数据库。
开始白盒攻击之前,基于这个数据库的分类器的AUC数值为0.97。即使在执行典型的清洗策略隐藏图像合成痕迹后,分类器的AUC数值仍保持在0.94以上。
接下来研究人员使用了4种白盒攻击方法。这4种攻击在之前的对抗性示例中已有过研究。攻击的具体方式是对图像进行修改,使分类器误认为它们是真实的。
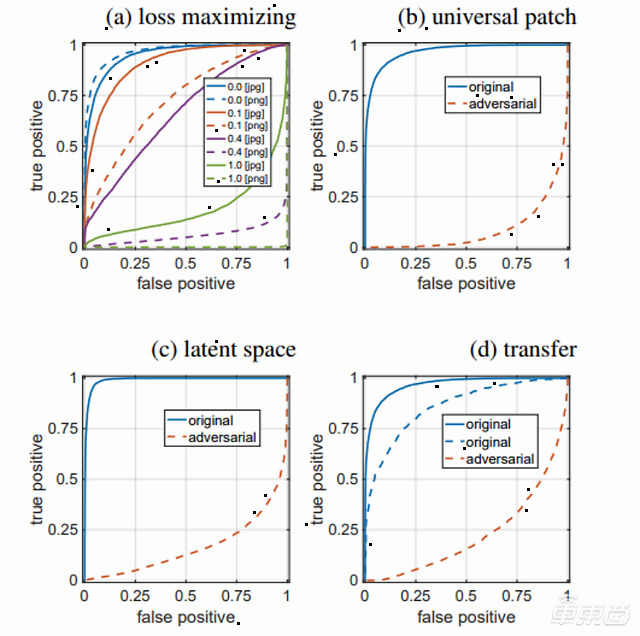
▲四种攻击前后,分类器的ROC曲线图。蓝色实线代表JPEG格式的合成图像,蓝色虚线代表PNG格式的合成图像
第一种是失真最小化攻击(Distortion-minimizing Attack),即对合成图像添加一个较小的加法扰动δ。假设一个合成图像x先被分类器判定为假,施加扰动后,(x+δ)就会被判定为真。
结果显示,像素翻转2%,就会有71.3%的假图像被误判为真;像素翻转4%,会有89.7%的假图像被误判为真;像素翻转4~11%,所有的假图像都会被误判为真。
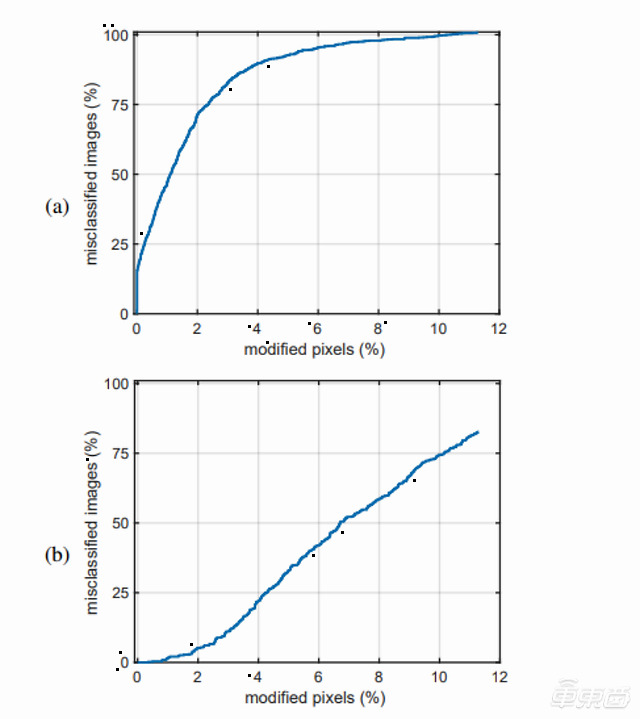
▲a:分类器把假图像识别为真;b:分类器把真图像识别为假。把像素翻转1%,就会有一半的假图像被判定为真;把像素翻转7%,就会有一半的真图像被判定为假。
第二种是损失最大化攻击(Loss-Maximizing Attack),即定义一个更简单的目标函数,更大限度地提升合成图像被判定为真的概率。
结果显示把未压缩图像的像素翻转40%,AUC值就会从0.966降到0.27。
第三种是通用对抗性补丁攻击(Universal Adversarial-Patch Attack)。失真最小化攻击方法有有一个局限性:攻击者需要花费0.1秒为每个图像定制攻击方式。为了弥补这一局限性,研究人员创建了一个单一的可视噪声模板补丁。这个补丁可以叠加在任何假图像上,有效增加了假图像的迷惑性。
叠加补丁后,分类器的AUC值从0.966降到0.085。
不同于之前三种方法通过对假图像施加扰动来影响分类结果,第四种攻击方法是通用潜空间攻击(Universal Latent-Space Attack),即对图像的潜在空间进行攻击。最终把分类器的AUC值从0.99降到0.17。

▲a为通用对抗性补丁攻击效果,b~d为通用潜空间攻击效果。图中所有假图像都被分类器误判为真
三、限制条件进行黑盒攻击,AUC值降至0.22以下
论文指出,现实中的社交网站、约会网站等,并不会公开其鉴定分类器的算法,因此很难进行前面所说的白盒攻击。
面对这种情况,研究人员进行了黑盒攻击。黑盒攻击假设对方知道攻击的存在,并且掌握了一般的防御策略。
研究结果显示,即使在这种限制性较强的黑盒攻击条件下,鉴定分类器也很容易受到对抗性因素影响。经过黑盒攻击,分类器的AUC数值下降到0.22以下。
结语:现有分类器有局限性,仍需深入研究
谷歌公司和加州大学伯克利分校研究团队证明,只要对虚假图片适当加以处理,就能使其“骗”过分类器。
这种现象令人担忧,论文中写道:“部署这样的分类器会比不部署还糟糕,不仅虚假图像本身显得十分真实,分类器的误判还会赋予它额外的可信度”。
因此,研究人员建议开创新的检测方法,研究出可以识别经过再压缩、调整大小、降低分辨率等扰动手段处理的假图像。
据悉,目前有许多机构正在从事这一工作,如脸书、亚马逊网络服务及其他机构联合发起了“Deepfake鉴别挑战”,期待能探索出更好的解决方案。





