CVPR NTIRE比赛双冠,网易互娱AI Lab是这样做的
2022-10-11 12:15:40爱云资讯862
近日网易互娱 AI Lab 获得第七届 NTIRE HDR 比赛的全部两个赛道的冠军。网易互娱 AI Lab 一直致力于利用 AI 提升美术生产效率,助力游戏贴图资源自动升级,目前相关技术已应用于贴图、UI 等游戏资源的精度和细节的提升,为多个游戏提供技术支持。本文将详细解读他们的双冠比赛方案。
近日,图像修复领域最具影响力的国际顶级赛事——New Trends in Image Restoration and Enhancement(NTIRE)结果出炉,网易互娱 AI Lab 包揽了高动态范围成像(HDR)任务全部 2 项冠军。NTIRE 比赛每年举办一次,目前已是第七届,主要聚焦图像修复和增强技术,代表相关领域的趋势和发展,吸引了众多来自工业界、学术界的关注者和参赛者,有着非常大的影响力。今年 NTIRE 比赛在计算机视觉领域的顶级会议 CVPR 2022(Computer Vision and Pattern Recognition)上举办。
高动态范围成像(HDR)任务的赛道 1 和赛道 2 分别有 197 个队伍、168 个队伍报名参加,吸引了包括腾讯、头条、旷视、蚂蚁、快手在内的工业界队伍,以及清华大学、中科院、中国科学技术大学、爱丁堡大学、帝国理工等国内外高校。网易互娱 AI Lab 从众多的强队中脱颖而出,斩获该任务的全部 2 项冠军。这是网易互娱 AI Lab 夺得多项国际冠军后,再次登顶国际 AI 竞赛,展现了网易互娱 AI Lab 在人工智能领域的综合实力。
任务描述
消费级的单传感器相机在拍摄照明情况复杂的场景时,难以用一种曝光参数拍摄出曝光正常的照片。由于成像传感器固有的局限性,譬如在高亮度区域因为过曝让画面呈现白色,从而导致这些区域细节的丢失。针对这个问题的解决方法是采用一个扩展的高动态范围(HDR)记录图片,具体做法是在拍摄时分辨拍摄多张不同曝光参数的低动态范围(LDR)图片,然后通过算法把多张图片融合成一张 HDR 图片。
此次比赛的目标是探索高效的 HDR 模型和技术方案,以达到实用化的使用需求。总计两个赛道:(1)保真度赛道:在限定模型计算量(小于 200G GMACs)的基础上,尽可能取得更高的保真度,评价指标是 PSNR-μ;(2)低复杂度赛道:在超过基线模型指标(PSNR-μ与 PSNR)的基础上,尽可能取得更低的计算量和更少的耗时,评价指标是 GMACs。
数据集介绍
本次比赛用的数据集包含 1500 个训练样本、60 个验证样本以及 201 个测试样本,每个样本包括三张 LDR 图片输入,分别对应短、中、长三种曝光水平,以及一个和中曝光对齐的 HDR 图片,数据集是由 Froehlich 等人收集的,他们捕捉了各种各样的具有挑战性场景的 HDR 视频。之前基于深度学习的 HDR 模型取得了不错的效果,譬如 AHDRNet、ADNet 等,但缺点是计算量非常大,以官方提供的基线方法 AHDRNet 为例,计算量在 3000GMACs 左右。因此本次比赛的目的是寻求高效的多帧 HDR 重建方法。
方法概述
由于任务的两个赛道均要求训练高效的 HDR 模型,网易互娱 AI Lab 凭借以往对 low-level 视觉任务和轻量化网络设计的经验积累,在基线模型的基础上,提出了一个 Efficient HDR 网络,包括高效的多帧对齐和特征提取模块两个模块,同时优化了模型的训练方法。
(1)在多帧对齐模块,采用 Pixel Unshuffle 操作在增大感受野的同时减少了特征图的大小,大幅减少了后续的计算量。同时,采用深度可分离卷积替代对齐模块中的普通卷积,大幅提高运算效率。
(2)在特征提取模块,采用深度可分离卷积替代普通卷积,SiLU 激活函数替代 ReLU,设计了一个高效残差特征蒸馏模块(Efficient RFDB)。另外,探索了网络深度与通道数目之间的关系,在限定计算量下层数更深且通道数少的特征提取网络,可以获得更高的评价指标。
(3)在训练方法上,在常规的 128x128 图片输入 L1 Loss 训练后,采用了 256x256 更大尺寸输入 + L2 Loss 进行训练调优。最后,使用基于 SwinIR 搭建的 Transformer 模型作为 Teacher 模型,对前述 CNN 模型进行蒸馏,结合 CNN 和 Transformer 各自的优势进一步提升模型效果。
网络结构
网络的整体结构基于官方提供的 baseline 模型 AHDRNet 进一步大幅改进和优化,主要可以分成三个部分:多帧对齐模块、特征提取模块和图像重建模块。基于本次比赛的计算量目标考虑,对网络部分做了以下设计:
1. Pixel Shuffle 层:在多帧对齐模块中使用 Pixel Unshuffle 操作(Pixel Shuffle 的逆操作),在不增加计算量的同时增大了感受野。在图像重建模块中使用 Pixel Shuffle 替代 AHDRNet 中的卷积操作,节省计算量。
2. 深度可分离卷积:在多帧对齐模块和特征提取模块,采用 Depthwise+1x1 卷积的组合替换了网络中的绝大多数卷积。
3. 特征提取基础模块替换:在特征提取模块采用 RFDB+ESA 替换 AHDRNet 中的 DRDB,并采用 SiLU 激活函数替换 ReLU。
4. 深度 vs 宽度:在限定计算量下,平衡特征提取模块深度和宽度取得更好的效果。以 Track1 的约束为标准,所有模型的计算量都在 190G~200G 之间(即更深的网络意味着更少的通道数)。
整体的网络结构图如图 2 所示,Efficient RFDB 的结构图如图 3 所示:

网络结构图
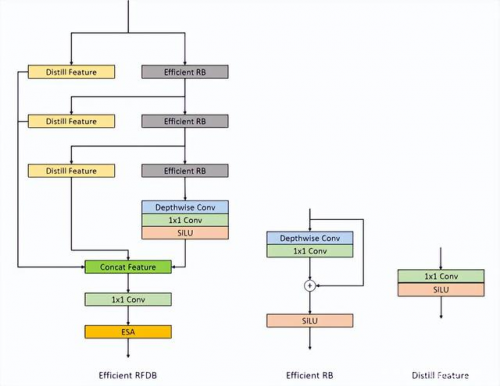
Efficient RFDB 结构图
最后提交的 Track1 和 Track2 模型均采用了上述的模型结构,区别是使用 Efficient RFDB 层数和通道数有所不同,对 Track1,Efficient RFDB 层数和通道数目较多,计算量是 198.47GMACs。对 Track2,Efficient RFDB 层数相近,通道数更少,计算量是 74.02GMACs。
训练过程
目前 HDR 的论文或比赛的主要评价指标是 PSNR-μ,指先对输出图片和标签图片分别做色调映射 tonemapping 操作再计算其 PSNR:
其中,
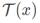
是指 tonemapping 操作。对图像做了以下处理:
其中,
。
主流的方法是对色调映射后的图片求 L1 Loss,譬如去年 NTIRE 比赛的多帧 HDR 比赛冠军 ADNet 是使用 tonemapped 后的图片损失函数,即:
该研究训练过程第一步同上使用 L1 Loss,并在此基础上加了后续三个 finetune 的过程,按顺序分别是:
1. L2 Loss finetune:为了获得更高的评价指标,在微调阶段该研究采用了和 PSNR 计算一致的 L2 Loss 代替 L1 Loss:
2. 大尺寸图片 + L2 Loss finetune:由于最后用了深层的网络设计,网络具有更大的感受野,采用 256x256 替代 128x128 的大尺寸图片进行微调可以让模型取得更好的效果。
3. 知识蒸馏 + 大尺寸 + L2 Loss finetune:使用基于 Transformer 的 SwinIR 中的 RSTB 代替 Efficient RFDB 搭建 Teacher 网络,此阶段损失函数如下:
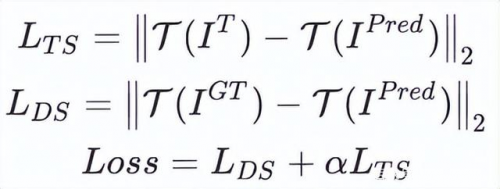
其中,TS 表示 Teacher Surpervision,DS 表示 Data Supervision,最后在实验中
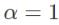
实验结果
赛道 1 中,网易互娱 AI Lab(ALONG)提出的方法在 PSNR-μ和 PSNR 上均是第一。如表 1 所示,主要评价指标 PSNR-μ比第二名高出了 0.172,而第二到第四的 PSNR-μ差距仅为 0.089,相比第五名之后的队伍更是拉开了 0.45 以上的差距。
赛道 2 中,网易互娱 AI Lab(ALONG)提出的方法取得了最低的计算量(GMACs)和最少的参数量(Param)。如表 2 所示,在超过基线方法 PSNR 和 PSNR-μ的基础上,减少了约 40 倍的计算量。相比第二名和第三名有较大领先,仅使用了约一半的计算量。
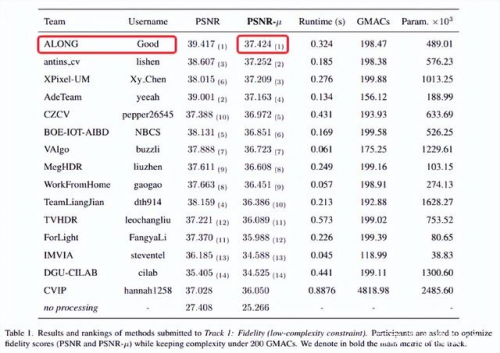
表 1:赛道 1(保真度赛道)结果排名
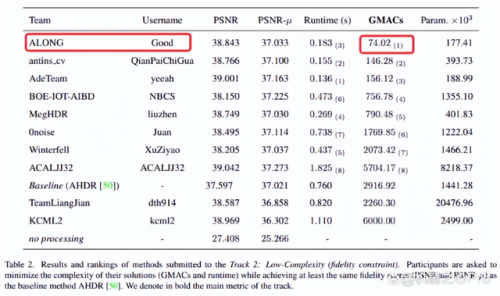
表 2:赛道 2(低复杂度赛道)结果排名





