阿里云机器学习平台PAI论文高效大模型训练框架Whale入选USENIX ATC´22
2022-07-13 10:47:49爱云资讯1409
近日,阿里云机器学习平台PAI主导的论文《Whale: Efficient Giant Model Training over Heterogeneous GPUs》,高效大模型训练框架Whale入选USENIX ATC'22。Whale通过对不同并行化策略进行统一抽象、封装,在一套分布式训练框架中支持多种并行策略,并进行显存、计算、通信等全方位的优化,来提供易用、高效的分布式训练框架。
USENIX Annul Technical Conference (USENIX ATC),是计算机系统领域国际顶级学术会议 (CCF-A),自1992年举办第一届USENIX ATC会议以来,至今已成功举办30多届,在学术和工业界都有巨大的影响力。USENIX ATC2022将于2022年7月11日召开。此次入选意味着阿里云机器学习平台PAI自研的深度学习分布式模型训练系统达到了全球业界先进水平,获得了国际学者的认可,展现了中国机器学习系统技术创新在国际上的竞争力。
Whale是阿里云机器学习PAI平台自研的高效、通用、硬件感知的大模型分布式训练框架,现已开源,开源后的名称是EPL(Easy Parallel Library)。Whale通过统一的策略抽象来实现各种分布式策略的表达,并通过硬件感知和自动计算图改写及优化完成高效的分布式模型实现。
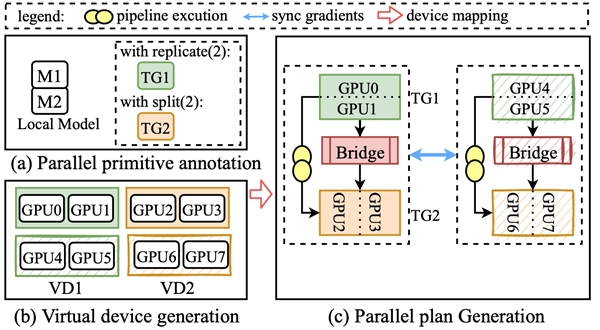
随着模型参数规模飞速增长,模型效果也在逐步提高,但同时也为训练框架带来更大的挑战。当前的业界分布式训练框架只支持少量的并行策略,缺乏一个统一的抽象来支持所有的并行策略及其混合策略。同时实现复杂的并行策略需要大量的模型代码改造和对底层系统的理解,大大增加了用户的使用难度。由于集群中异构GPU计算能力和显存的差异,静态的并行化策略无法充分利用异构资源实现高效训练。
针对这些问题,Whale抽象并定义了两个分布式原语(replicate和split) 。用户可以通过在模型上添加几行原语标记,即来表达和转换各种并行化策略及其组合,极大降低了分布式框架的使用门槛。Whale runtime将用户的标记信息融合到计算图中,自动完成模型的并行化优化。同时Whale提供了基于硬件感知的自动化分布式并行策略,优化在异构GPU集群上分布式训练性能。Whale的设计很好地平衡了模型用户的干预和系统优化机会,让每一个算法工程师都能轻松高效训练分布式大模型任务。借助Whale,阿里达摩院M6模型使用512张V100 GPU在10天内即可完成10万亿多模态预训练模型。
Whale起源于阿里内部业务,在阿里内部已经支持图像、推荐、语音、视频、自然语言、多模态等业务场景。并且能无感支持模型规模横向扩展,最大完成了10万亿规模的M6模型训练。同时Whale已经集成在阿里云机器学习平台PAI中,大家可以在阿里云PAI平台上使用Whale。机器学习平台PAI是面向开发者和企业的AI工程化平台,提供了覆盖数据准备、模型开发、模型训练、模型部署的全流程服务。
Whale(EPL)开源地址(https://github.com/alibaba/EasyParallelLibrary),欢迎大家来试用和给出建议。
论文名称:Whale: Efficient Giant Model Training over Heterogeneous GPUs
论文作者:贾贤艳,江乐,王昂,肖文聪,石子骥,张杰,李昕元,陈浪石,李永,郑祯,刘小勇,林伟
开源链接:https://github.com/alibaba/easyparallellibrary
论文链接:https://www.usenix.org/conference/atc22/presentation/jia-xianyan
相关文章
- 阿里云与南京大学签署校企合作协议,以“云工开物”支持人工智能人才培养与科研创新
- 阿里云升级Premier级别WhatsApp官方商业解决方案提供商,赋能全球企业高效连接20+亿用户
- 叫叫亮相阿里云AI势能TECH DAY:AI为教育插上想象的翅膀
- 重磅发布!亚信科技、阿里云大模型一体机,让百行千业用上普惠AI
- 接入 DeepSeek、联合阿里云,传音AI战略玩出新高度!
- 阿里云 Chat App 打通模型服务, 0代码接入智能体应用
- AI耳机AIxFU来了!基于阿里云通义大模型深度打磨,性能、智能、价格重新定义行业标准
- 变革通话体验,中国移动携手阿里云通义、华为打造“交互通话”新时代
- 阿里云“上云采购季”开启:AI主流大模型直降88%,超200款云产品爆优惠
- 中国移动阿里云和中兴通讯联合打造的能力开放解决方案荣获GSMA GLOMO “Open Gateway挑战奖”
- 阿里云PolarDB重磅发布云原生与Data+AI新特性,打造智能时代数据引擎
- 恺英网络携手阿里云 共探游戏产业新未来
- 阿里云操作系统控制台上线,追踪隐式资源,巧解内存难题!
- 阿里云推出短信模板 AI 助手,模板审核通过率高达 98%
- 阿里云百炼上线全尺寸DeepSeek模型 所有用户可直接使用
- 阿里云正式成为FinOps基金会顶级会员





