特斯联推联邦学习算法引擎实现城市及产业数据安全研究
2022-04-11 16:35:58爱云资讯996
数据是人工智能及机器学习的基础。随着人工智能从计算、感知阶段发展到认知阶段,其进一步发展对数据的需求量亦在逐步攀升。然而在大多数行业中,囿于各种各样的原因,数据常常以孤岛的形式存在——即使是在同一个公司的不同部门之间,要实现数据的集中整合也面临着重重阻力——在现实中将分散在各地、各个机构的数据进行整合几乎是不可能做到的事,其成本也十分高昂。此外,随着人工智能的进一步发展,数据的隐私和安全业已成为了世界性的议题。
针对人工智能发展及其所面临的数据孤岛和数据隐私的两难问题,联邦机器学习(Federated Machine Learning)即为能有效帮助多个机构在满足用户隐私保护、数据安全和政府法规的要求下,进行数据使用和机器学习建模的机器学习框架。
日前特斯联所打造的德阳科创中心正式落地运营。德阳科创中心的设立旨在充分贯通学术生态和产业生态,以“成本共担”的方式,为周边的中小微企业提供AI所需的算力、数据、算法模型等核心要素,让各体量、具备不同AI基础的企业均能通过学术机构所研发出的模型,以低代码、模块化的生产方式依据自身的需求,实现自有知识产权算法的孵化及既有成熟算法的调用,而支撑产业算法孵化的原料来自于学术科研生态的研究成果——预训练模型。
通过联邦学习的核心技术,特斯联向学术科研生态提供科研的原料——城市及产业数据——并将算力下沉至数据端,形成联邦学习智算节点,通过九章算法赋能平台为学术科研提供服务。
据特斯联透露,在联邦学习方向,特斯联基于九章算法赋能平台打造了联邦学习算法引擎,以其作为研究型算法孵化平台的核心。目前联邦学习算法引擎已支持横向联邦学习算法和纵向联邦学习算法,通过AI-Research-Studio,向学术科研生态提供基于联邦学习数据使用的API接口。
本文通过城市用电数据以联邦树模型及联邦神经网络的算法实现预测类预训练模型的研究实践,对特斯联打造的联邦学习算法引擎进行介绍。
横向联邦学习:支持跨场域高重叠数据特征机器学习
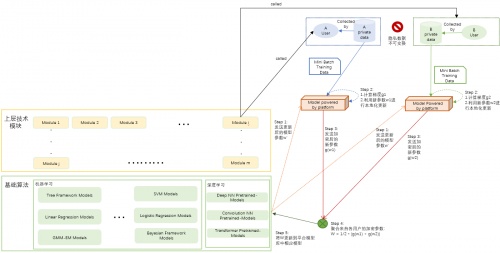
特斯联联邦学习算法引擎横向联邦学习架构图
横向联邦学习主要应用于具有相同特征样本、用户重叠度较少的数据集。
科研人员通过查看数据样例来确定这些数据是否满足科研要求,在满足要求的情况下,通过调用联邦学习的API实现数据的使用。而特斯联联邦学习算法引擎的横向联邦学习内部运行过程主要由如下几步构成:
各智算节点从中心安全可信服务器中下载由科研人员提供需要训练的模型;
每个智算节点利用本地数据训练模型(无需上传本地数据),将数据加密梯度上传至中心安全可信服务器,并由中心安全可信服务器聚合各数据持有方的梯度更新模型参数;
中心安全可信服务器依据贡献度,将更新后的模型返回至各智算节点;
各智算节点更新各自模型,并从第2步重复直至训练完成;
完成训练后,研究人员即可使用模型完成其目标任务。
特斯联所打造引擎的横向联邦学习部分目前已实现基于联邦DNN实现片区用电数据的打通。通过上述横向联邦学习步骤完成训练后,引擎可实现一键部署,并为用户提供相应的API调用接口——后续可直接面向科研人员提供服务,在保证数据安全的前提下实现预训练模型的研究。
纵向联邦学习:面向固定场域低重叠数据特征机器学习

特斯联联邦学习算法引擎纵向联邦学习架构图
与横向联邦学习不同,纵向联邦学习主要应用于具有用户重叠较多而特征重叠较少的特性的数据集。
具体而言,科研人员通过查看数据样例来确定这些数据是否满足科研要求,在满足要求的情况下,通过调用联邦学习的API实现数据的使用。特斯联的联邦学习算法引擎的纵向联邦学习过程由如下几步构成:
中心安全可信服务器通过特定选择及评估机制,将科研人员提供的算法模型打散成多个小模型(如图示中将原模型分解为A-part和B-part两部分),然后分发到每个智算节点下。中心保留模型完整结构信息和各小模型在各方节点的信息;
引擎参考SecureBoost算法的去中心化思想,每个智算节点自行完成加密中间结果的交互,其中包括各数据持有方的小模型计算结果,梯度等;
各智算节点完成加密中间结果的交互后,各智算节点方(如图示A)均可从其他智算节点(如图示B)中收集到加密梯度统计,然后进行聚合产生最优解,再反馈至其他智算节点;重复第2步,共同完成联合建模;
完成联合建模后,各智算节点的小模型信息更新至中心安全可信服务器,各智算节点的小模型依旧存储在其本地;
在使用模型预测时,中心安全可信服务器通过基于各小模型节点信息,联合调用各方小模型共同完成推算。
特斯联打造的联邦学习算法引擎的纵向联邦学习部分目前已应用于基于SecureBoost算法通过城市用电数据的接入,实现预测类预训练模型的研究和抽象。在稳定性实验下,基于SecureBoost算法所实现的城市用电预测模型和传统本地训练模型的结果进行对比,预测结果误差在8%左右;在准确率实验下,多纵向节点联合建模的城市用电预测模型相对于单节点建模的结果进行对比,性能提升了30%,即多纵向节点联合建模的预测结果相较于标签结果的误差更小。特斯联将这一模型进行抽象化封装,以应用于跨行业的更多场景。
通过用电数据抽象预测类预训练模型
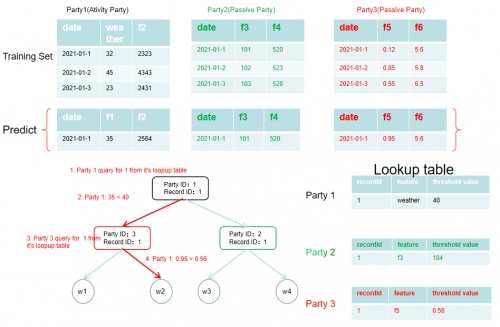
城市用电量预测算法图示
具体在城市用电案例下,由于数据的保密性,联邦学习算法引擎得到的特征都经过脱敏处理。在具体的操作过程中,首先,我们考虑一个具有三个parties(参与方)的系统,如图所示,其中party2和party3为passive parties(被参与动方),party1是一个activity party(主动方)。我们首先通过前述算法训练得到一个树模型,并生成对应的lookup table(查找表)。为了预测在2021年1月1日的用电量,三个参与方将协作工作,由主动方调动被动方完成。首先从根节点开始,通过[party id:1, record id:1]的记录,主动方可以知道其所控制节点的划分,主动方则可通过其对应的查找表找到对应的划分属性和阈值。通过这一过程我们可以发现相应节点是通过属性weather(天气)进行划分的,且划分阈值为40,因此该节点落下左节点,依次类推,一直到达叶子节点。而这个模型通过抽象转化可应用于其他行业的预测领域。通过前述过程可进一步达到去中心化效果,实现数据的跨行业使用,训练过程中无需数据拥有方的直接参与,科研机构即可使用上述能源数据实现跨界的预测算法研究,解决单边数据规模小和标签样本少的问题,同时,也降低了能源数据泄露的几率,提升数据的安全性。
提升数据可及性及安全性,联邦学习推动AI与各行各业深度渗透
事实上,针对用电数据的模型化抽象仅是特斯联联邦学习数据应用场景的冰山一角,特斯联将行业数据根据技术分类进行抽象,按视频图像、自然语言处理、推荐预测、知识图谱进行归类划分,通过API对科研机构、高校提供数据服务。科研机构高校将研究的成果以预训练模型的形式通过九章算法赋能平台的弱监督大模型技术向产业提供低门槛、高质量的人工智能算法孵化功能。
在特斯联看来,能够盘活城市中庞大的沉默数据资源,使数据真正有效地为行业所应用即为其打造科创中心最大的价值。特斯联德阳科创中心负责人认为,作为人工智能发展的三大核心要素之一,数据是人工智能得以不断向前发展的基础,“可以说未来行业的发展与数据的可及性、安全性是正相关的。通过打造联邦学习算法引擎,我们希望在确保数据隐私的同时,为各个行业尤其是中小微企业降低数据获取的门槛,推动AI与各行各业更深度地绑定。这也是推动AI普惠化发展必经的一段路程。”
相关文章
- 特斯联助力蔡甸谋划智能产业发展新格局
- 特斯联机器人:园区是机器人无法逾越的大山吗
- 阿联酋航空引入特斯联机器人,简化机场登机手续办理
- 特斯联携手科知中心:打造数智转型“德阳新模式”
- 特斯联参与国家重点研发计划重点专项获批立项
- 特斯联智慧照明控制系统赋能鄂州港智慧升级
- 特斯联入选专精特新高质量发展项目名单
- 特斯联机器人与通州法院达成首期合作,共同打造智慧法院
- 特斯联杨旸受邀出席O-RAN nGRG研究组会议
- 特斯联杨旸:前沿技术与既有体系有效融合是技术转化的关键
- 对话首席 | 特斯联邵岭:ChatGPT的现状和商业化前景
- 特斯联泰坦机器人成功入选“低速无人驾驶场景落地案例TOP50”
- 特斯联机器人布局社区场景,打通消费界限
- 中国低速无人驾驶行业团标发布 特斯联任参编单位
- 特斯联重庆AI CITY顺利封顶!加速智能城市网络规模化落地
- 特斯联助推“双碳”落地,实现不可替代价值





