AI赋能游戏工业化,网易互娱AI Lab动捕去噪新方法入选SIGGRAPH 2021
2021-08-11 11:05:43爱云资讯1331
当游戏行业仍在聚焦探讨如何让AI真正落地、协助游戏的工业化制作时,网易互娱AI Lab已基于游戏研发制作中的痛点交出了一份令人惊艳的答卷。
在游戏中,各个角色存在大量动作动画资源制作的需求,而让游戏角色获得如同真人一般流畅自然的动作历来是制作者们孜孜不倦追求的目标。近年来,伴随着游戏工业化的趋势,光学动捕凭借其真实性和效率替代了传统的关键帧制作方式,成为许多大制作端游和手游的首选方案。然而,光学动捕最大的弊端之一便是动捕数据清理所带来的巨大工作量,该过程需要依赖人工完成,因此在整个流程中成本占比也最高。尽管此前已有学者提出了基于深度人工神经网络的光学动捕数据自动清洗和解算方案,但该方法的性能还无法满足实际生产环境的要求,且针对动作细节的保真度也存在一定问题。
针对这一实际生产环境中的痛点,网易互娱AI Lab提出了一种针对光学动捕数据的自动清洗和解算方法,可以直接从包含错误和噪音的raw markers中预测出与之对应的clean markers和骨骼动画数据。算法精度和鲁棒性都超越育碧研究院(Ubisoft La Forge)发表在SIGGRAPH 2018的方法,技术创新性处于国际领先水平。利用该方法,传统光学动捕流程中所需的人工工作量可以被大幅降低。近日,网易互娱AI Lab与清华大学合作对该方案进行了系统性技术梳理,并撰写论文《MoCap-Solver:A Neural Solver for Optical Motion Capture Data》,该文章已被SIGGRAPH 2021收录。
论文地址:https://dl.acm.org/doi/abs/10.1145/3450626.3459681
项目地址:https://netease-gameai.github.io/MoCapSolver
技术背景
运动捕捉(Motion Capture),简称动捕(MoCap),指的是将真实演员的肢体动作转换为三维虚拟角色骨骼动画的技术。相比于传统的关键帧动画制作方式,运动捕捉技术有着巨大的优势,既提升了三维动作资源的真实度,又提升了其生产效率,也因此成为了当前影视、游戏行业三维人形动画的标准制作方式。
从技术原理上划分,运动捕捉设备可以分成两种类型,惯性动捕设备和光学动捕设备。其中惯性动捕设备利用固定在演员关节上的加速度传感器来获取演员各个关节的相对运动量;而光学动捕设备则通过大量不同视角的高速相机同步拍摄演员动作,并利用多视角三维重建技术计算贴在演员身上的一批特殊标记点(marker)的三维坐标,之后再基于这些坐标解算出演员每个关节点的位置和旋转信息。惯性动捕设备成本较低,但是由于受到惯性传感器的精度限制,其动作捕捉的精度也明显低于光学动捕设备。此外,由于惯性动捕设备记录的是每个关节相对于上一时刻的相对值,无法获取演员在三维空间中的绝对坐标,这一特性导致惯性动捕设备无法应用于多人同时动捕的场景,因为其无法定位不同演员之间的相对位置关系。由于以上原因,虽然光学动捕设备成本高昂,但却在运动捕捉领域占据绝对统治地位。
利用光学动捕设备进行动捕的流程分为以下几个步骤:
1.演员装扮:演员穿着紧身动捕服装,并在衣服表面需要捕捉的关节附近粘贴一定数量的marker点(标记点),marker点总数以及每个marker点粘贴的位置构成一套marker configuration;
2.演员标定:构建一个与演员体型相适配的人形模版模型,并获取粘贴在真实演员衣服上的每个marker在该人形模版模型上的位置,模版模型的骨架结构叫template skeleton。构建方式一般为捕捉一小段该演员的简单动作,然后用算法自动去拟合模版模型和marker位置,这个过程也叫range of motion(ROM)标定。当然也可以在motion builder等软件中人工进行这种标定。
3.动作捕捉:演员在被一圈高速红外相机围绕的动捕场景内按照剧本表演出规定的动作,所有相机同步进行拍摄,然后动捕软件利用多视角几何和目标跟踪算法,计算出每一个时刻演员身上每个marker点在三维空间中的坐标;
4.动捕数据清洗:由于遮挡、传感器测量误差、重建和跟踪算法本身的误差等原因,上一步动捕软件输出的marker坐标中往往存在很多错误,需要人工对这些错误进行修复,这个步骤也叫动捕数据清洗。清洗过程需要耗费大量人力,因此该步骤也是传统光学动捕流程中成本最高的部分。
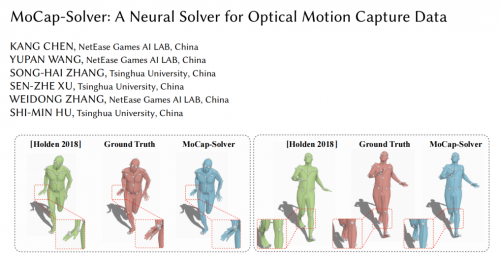
5.动捕解算:利用动捕解算软件、基于步骤2中的演员标定信息,从捕捉到的marker序列中恢复人体各个骨骼关节的位置和旋转信息,从而得到三维骨骼动画数据(也叫skeletal motion或简称motion)。下图对比了从不经过人工清洗的marker数据(左,也叫raw markers)和经过人工清洗的marker数据(右,也叫clean markers)中解算得到的骨骼动画的差别。

6.动作重定向:将解算得到的骨骼动画数据重定向到不同体型的三维虚拟角色上,变成对应角色的动画资源。
目前业界对光学动捕数据的清洗和解算主要依赖vicon blade、vicon shogun、autodesk motionbuilder等商业软件提供内置工具,处理流程与前文技术背景中描述一致,其特点为高度依赖人工对动捕marker数据中的错误进行修正,否则解算出的骨骼动画数据会存在明显的缺陷。典型的处理流程为,先对raw markers进行自动解算得到存在缺陷的骨骼动画,人工对得到对动画进行逐帧预览,寻找存在问题的区间,然后人工纠正该区间内导致解算结果异常的marker点。不断重复这一过程,直到整个动捕动作序列都能被正确解算。
为了解决这一实际生产环境中的痛点,育碧研究院(ubisoft la forge)的研究员Daniel Holden在2018年首次提出了一种基于深度人工神经网络的光学动捕数据自动清洗和解算方案,并发表在图形学顶级期刊TOG上(在SIGGRAPH 2018展示)。然而,育碧的方案虽然可以自动清洗和解算,但是该方法的性能还无法满足实际生产环境的要求。一方面,该方法的鲁棒性不足。该方法高度依赖粘贴在演员躯干上(环绕胸部和腹部的两圈)的少量关键marker(也叫参考marker)的质量。一旦输入的raw markers中包含参考marker的错误,该方法的解算结果就会出现明显错误。而在实际动捕环境下,这些参考marker很容易因为被四肢遮挡而导致捕捉错误。另一方面,该方法对动作细节的保真度也存在一定问题。本质上来说,该方法基于逐帧处理的算法框架,没有考虑相邻动作帧之间在时间和空间上的连续性,导致其输出的动画存在明显的抖动。为了解决这个问题,该方法引入了一个后处理操作对输出的动画进行平滑、从而抑制抖动。但是,这个平滑操作在消除抖动的同时也会抹去动作本身的运动细节,降低保真度。
技术思路
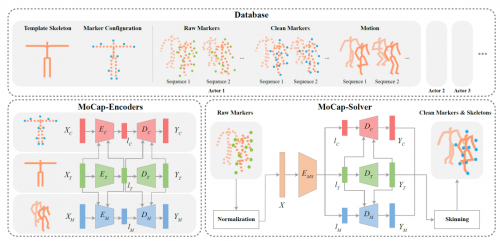
针对育碧方案存在的问题,我们提出了一种全新的算法框架。由于clean markers在三维空间中的位置是由演员体型、动捕marker在演员身体(贴在动捕服)上的分布和演员的动作三方面因素决定的,得到这三个信息,我们就可以通过前向动力学(forward kinematics, FK)和线性蒙皮运算(linear blend skinning, LBS)完全恢复出对应的clean markers。
基于这一观察,我们的核心思路为:利用大量动捕数据,训练一个从raw markers预测上述三方面信息的深度人工神经网络。为了更好的实现这一目标,我们首先设计了一个自编码器(MoCap-Encoders)结构,该自编码器包含template skeleton、marker configuration和motion三个分支,分别对应了演员的体型、marker在动捕服装上的分布、以及演员动作。在大量动捕数据上进行训练后,该自编码器可以将将 template skeleton、marker configuration和motion三种数据编码成低维空间的隐向量,也可以从隐向量中恢复出对应的原始数据。也就是说,MoCap-Encoders从大量数据中学习出了一种关于这三方面数据的更为高效、紧凑的表达。之后,我们再训练一个从raw markers预测这三个分支隐向量的网络(MoCap-Solver),从预测出的隐向量中可以解码出对应的 template skeleton、marker configuration和motion。其中的motion就是需要解算的骨骼动画,再通过前向动力学(forward kinematics, FK)和线性蒙皮运算(linear blend skinning, LBS)就可以计算出对应的清洗后的clean markers。
此外,我们还从真实数据中训练了一个对关键参考marker的质量进行评估的深度人工神经网络,利用该网络挑选raw markers中参考marker可靠性高的帧做刚体对齐,有效避免了算法精度过渡依赖少量参考marker质量的问题,大幅提升了算法的鲁棒性。
技术实现
本方法包含训练阶段和预测阶段,预测阶段直接以光学动捕的raw markers为输入,自动输出清洗后的clean markers和解算出的骨骼动画。这里主要介绍训练阶段的做法,训练阶段包含三个重点步骤:数据准备、数据规范化(normalization),以及深度人工神经网络结构搭建和训练。
1.数据准备


2.数据规范化
由于真实运动包含很多人物根骨骼的全局位移和全局旋转,这极大增加了后续人工神经网络学习的复杂度。例如,同样的动作在不同的位置、朝着不同的方向做,会导致捕捉的marker点三维坐标存在巨大差距。此外,由于遮挡原因,真实动补数据中包含很多跟踪失败的点,其表现为保持在最后一次被成功跟踪的位置不动,随着人物远离该位置,这些点就会变成毫无规律的离群点,也会给后续网络的学习造成干扰。所以数据规范化的目标有两个:离群marker的处理和坐标系规范化。
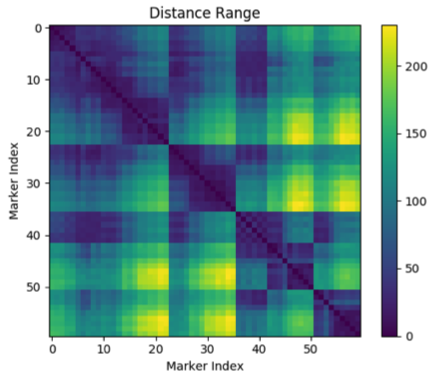
为了处理离群marker,我们首先提取序列中每一帧所有marker之间的距离矩阵(如上图),该矩阵记录了所有marker两两之间的欧式距离,然后选择距离矩阵最接近所有帧的距离矩阵平均值的那一帧作为序列的参考帧。之后,将每一帧与参考帧的距离矩阵进行对比,所有导致该帧的距离矩阵与参考帧的距离矩阵存在30厘米以上差异的marker点都被标记为离群marker点。离群marker点的坐标会被替换成新的位置,新的位置可以使对应帧的距离矩阵与参考帧的尽量接近。这些新的位置可以通过简单的数学优化方法得到。
坐标系规范化的目的是消除根骨骼全局平移和旋转,因此需要marker的坐标由世界坐标系转换到局部坐标系。为此,我们参考了[1]中的做法,以躯干附近(环绕胸部和腹部的两圈)的一批marker为参考marker(如下图),然后对序列整体的全局平移和旋转进行修正。方法为在序列中选定一个参考帧,计算一个刚体变换使得参考帧的这批参考marker的位置与T-pose下的参考marker的位置尽量对齐(也叫刚体对齐)。通过这个操作,序列中所有帧的坐标系就由世界坐标系变换到了由T-pose定义的局部坐标系。
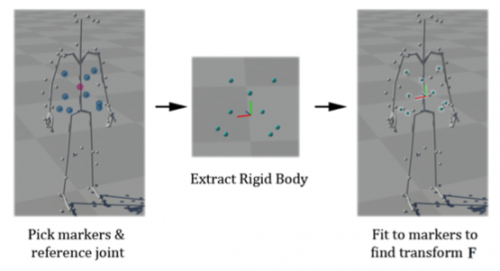
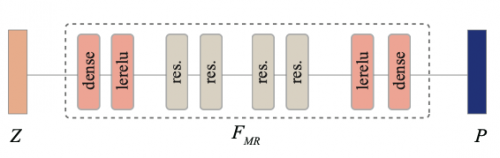
但是,这个操作高度依赖参考帧中的那批参考marker的质量,一旦参考帧的参考marker中存在噪音和错误,坐标系规范化的效果就会大打折扣,整套算法的精度和鲁棒性都会大幅降低。为了解决这个问题,本发明训练了一个对参考marker的质量进行评估的深度人工神经网络,并利用这个网络挑选参考marker可靠性高的帧做参考帧进行刚体对齐。该网络的结构如下:

3.深度人工神经网络结构搭建和训练
接下来,我们利用上述数据和规范化方法训练一个深度人工神经网络结构,该网络包含两个模块,如下图所示:
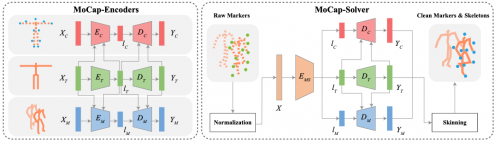
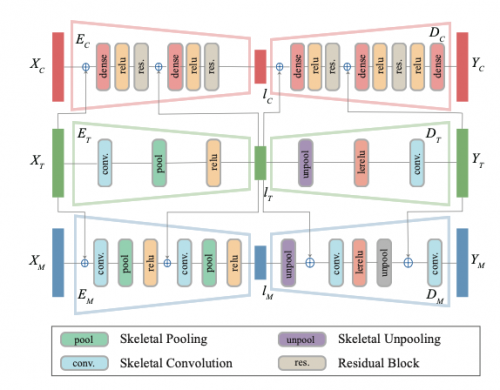
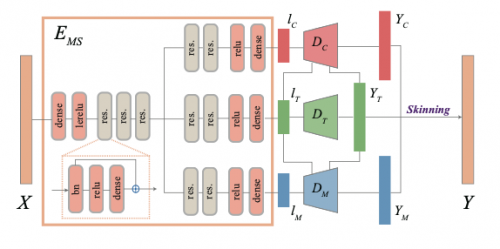
其中MoCap-Encoders为一个自编码器,包括三个分支,分别对应template skeleton、marker configuration和motion。训练完成的自编码器既可以将 template skeleton、marker configuration和motion三种数据编码成低维空间的隐向量,也可以从隐向量中恢复出对应的原始数据。MoCap-Encoders的网络结构如下图所示:


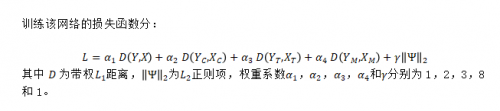
应用/效果展示
本项目的训练数据来源于公司采集的大规模真实动捕数据,可以大于30fps的速度对光学动捕数据进行自动清洗和解算,满足了工业上速度要求,解算得到的骨骼动画的骨骼点平均位置误差小于1cm,平均旋转误差小于4度,满足了游戏动画制作的精度要求。相比于目前业界领先算法,本项目算法在动作保真度和重构marker点精度上领先,统计得到本算法的预测结果只有低于1%的帧出现了工业生产不可接受的视觉瑕疵,而目前业界领先算法则为10%。另外,本算法的鲁棒性优于业界领先算法,实验结果表明本算法对演员躯干附近关键marker点精度的鲁棒性比目前业界领先方法好。目前本项目算法已经集成在公司动捕数据处理的工作流中。





