突破传统数据中心算力瓶颈,阿里自研AI集群论文入选体系结构顶会HPCA 2020
2020-03-03 17:57:55爱云资讯721

论文作者之一,阿里巴巴资深技术专家蒋晓维在会议现场分享
1. 摘要
人工智能(Artificial Intelligence)已经被广泛应用在阿里巴巴集团内部的各个业务,包括:搜素推荐、智能翻译、预测服务、城市大脑、自动驾驶等。随着AI业务和算法的持续演进,神经网络的模型规模和训练数据集容量急剧增加,不断挑战底层训练平台的算力极限。大规模高性能AI集群可以为算法模型的训练提供了有力的算力支撑,保证业务算法的先进性。但由于AI业务的特征差异和传统数据中心架构的局限,大规模AI训练集群的扩展性非常差。随着训练集群规模的增长,新增资源在传统数据中心架构下所获得的性能收益不断降低,成本收益显著下降。
为解决这一问题,阿里巴巴进行了高性能AI训练集群EFlops的研发,通过算法架构的协同设计,通信算法的效率达到理论上限,实现了集群规模的近线性扩展。通过和拍立淘团队合作在EFlops系统上,将拍立淘百万分类大模型的训练速度提升4倍,并首次支持千万分类模型的训练;与阿里巴巴机器翻译团队合作,提升阿里巴巴翻译模型精度的同时,将训练时间从100小时降低至12小时。
EFlops架构的集群系统已应用于阿里巴巴计算平台的人工智能训练平台(PAI),服务阿里巴巴的人工智能业务的模型训练,大幅缩短业务模型迭代周期,达到了预期的性能和成本收益,此次论文被收录标志着阿里巴巴在AI基础设施设计领域进入了世界领先水平。
2. 背景
由于深度神经网络的技术突破, AI业务已广泛应用于社会生活的方方面面。围绕AI的技术研究也引起了越来越多的关注,包括AI算法模型、训练框架、以及底层的加速器设计等。然而极少有人从集群架构角度探究过,AI业务的运行模式与传统大数据处理业务的差别,以及AI集群的架构设计应该如何优化。
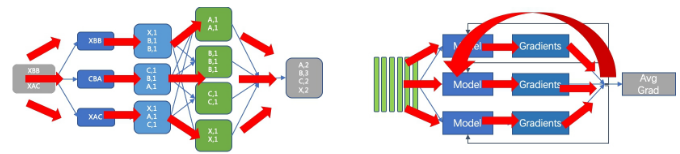

阿里巴巴的研究人员率先对AI业务的运行模式进行了分析,并对AI训练集群的架构设计进行了定制优化,使AI训练业务的训练效率成倍提升。虽然AI业务也存在很强的数据并行度,但与大数据处理业务和高性能计算业务特征存在明显的不同。其核心差别在于:1)AI业务的子任务独立性很低,需要周期性地进行通信,实现梯度的同步;2)AI业务的运行以加速部件为中心,加速部件之间直接通信的并发度显著高于传统服务器。因此,对AI业务而言,传统数据中心的服务器架构和网络架构都存在很多严重的问题。ß
服务器架构问题主要为资源配置不平衡导致的拥塞问题,以及PCIe链路的QoS问题。传统服务器一般配备一张网卡用于节点间通信,为了支持AI业务而配置多个GPU。AI训练经常需要在GPU之间进行梯度的同步,多GPU并发访问网络,唯一的网卡就成为系统的瓶颈。此外,PCIe链路上的带宽分配与路径长度密切相关,长路径获得的带宽分配较低,而跨Socket通信的问题更加严重。

网络架构问题主要在于AI训练中同步通信导致的短板效应。网络拥塞本是一个非常普遍的问题,拥塞控制也已经进行了几十年的研究。但是,阿里巴巴的研究发现,传统的拥塞控制算法并不能解决AI训练集群的通信效率问题。拥塞控制算法的最终目的在于对两个碰撞的流进行限速,使其尽快达到均分物理带宽的目的。但由于AI业务通信的同步性,每个通信事务的最终性能决定于最慢的连接。均分带宽意味着事务完成时间的成倍提升,严重影响AI通信的性能。
3. EFlops关键技术
EFlops系统核心关键技术包括:1)网络化异构计算服务器架构,2)高扩展性网络架构,3)与系统架构协同的高性能通信库。
3.1 EFlops硬件架构
网络化异构计算服务器架构,一方面,通过为每个GPU提供专用的网卡负责与其他GPU的通信,避免了网卡上的数据拥塞;另一方面,基于Top-of-Server的设计思想,将节点内加速器之间的通信导出到节点外,并利用成熟的以太网QoS机制来保证拥塞流量之间的公平性。随着加速器芯片计算能力的快速提升,对通信性能提出越来越高的需求,这种多网卡的网络化异构计算服务器架构将很快成为主流。
在网络架构层面,EFlops设计了BiGraph网络拓扑,在两层网络之间提供了丰富的链路资源,也提供了跨层路由的可控性。

3.2 通信算法设计
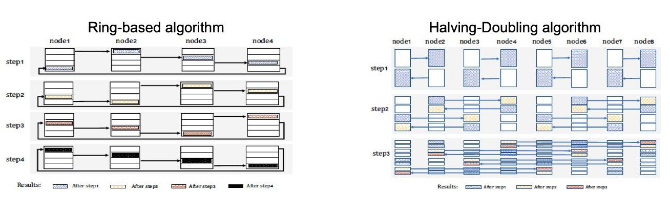
Allreduce是数据并行训练场景下的最主要集合通信操作,其中常用的通信算法包括Ring-based和Halving-Doubling等(后文以Ring、HD作为简称)。
Ring算法的主要流程包括:1)接收左侧节点发送来的一个chunk数据,2)并与本地数据进行制定allreduce操作,生成allreduce操作的中间值,3)将上一个step生成的中间值发送给右侧节点;4)将接收和发送的数据chunk指针进行更新。HD算法主要流程包括:1)将所有节点按照距离进行配对,2)每个节点发送一半数据给配对节点,并接收另一半数据进行allreduce操作,3)每个新的step,所有节点重新配对;其中,配对的距离加倍,而传输的数据量减半(也就是上一个step接收数据的一半)。
可以看到,Ring和HD算法在数据传输量上没有区别,都是2S;其中S是Message的大小。从通信次数角度看,Ring算法需要N-1个Step的通信,而HD算法只需要log2N个Step;其中N是参与节点个数。而Ring算法只需要N个连接,而HD算法需要N*log2N个连接。需要特别指出的是,HD算法的每个Step只需要N/2个连接。
结合HD算法的特性对BiGraph拓扑进行分析:BiGraph拓扑两层交换机之间存在N/2个物理链路,而HD算法每个step需要N/2个连接;而且,BiGraph拓扑两层交换机之间最短路径的确定性。基于此,EFlops设计了与BiGraph架构适配的通信算法Halving-Doubling with Rank-Mapping(HDRM),实现逻辑连接和物理链路之间的一一映射,完全消除网络拥塞,达到极致的通信性能。需要强调的是,若采用CLOS网络拓扑,EFlops系统的通信算法也同样适用,差异在于BiGraph有更优的组网成本。
4. EFlops测试数据
实验结果表明:在64-GPU系统规模下,EFlops的HDRM算法小包(比如1KB Message)通信性能,是Ring算法的6倍;对大包(比如256MB Message),HDRM算法带宽比Ring高10Gbps。EFlops的HDRM算法性能受系统规模影响最小,体现出最好的规模扩展性。

相关文章
- 阿里云升级Premier级别WhatsApp官方商业解决方案提供商,赋能全球企业高效连接20+亿用户
- 叫叫亮相阿里云AI势能TECH DAY:AI为教育插上想象的翅膀
- 重磅发布!亚信科技、阿里云大模型一体机,让百行千业用上普惠AI
- 接入 DeepSeek、联合阿里云,传音AI战略玩出新高度!
- 阿里云 Chat App 打通模型服务, 0代码接入智能体应用
- AI耳机AIxFU来了!基于阿里云通义大模型深度打磨,性能、智能、价格重新定义行业标准
- 变革通话体验,中国移动携手阿里云通义、华为打造“交互通话”新时代
- 倍益康亮相阿里巴巴国际站跨境出海生态大会,拓展国际市场商机
- 阿里正式推出AI旗舰应用 新夸克发布“AI超级框”
- 阿里云“上云采购季”开启:AI主流大模型直降88%,超200款云产品爆优惠
- 中国移动阿里云和中兴通讯联合打造的能力开放解决方案荣获GSMA GLOMO “Open Gateway挑战奖”
- 阿里开源模型万相2.1引爆视频赛道!谷歌/微美全息加入全模态AI开源新时代!
- 阿里云PolarDB重磅发布云原生与Data+AI新特性,打造智能时代数据引擎
- 恺英网络携手阿里云 共探游戏产业新未来
- 阿里云操作系统控制台上线,追踪隐式资源,巧解内存难题!
- 阿里云推出短信模板 AI 助手,模板审核通过率高达 98%





