百度语音识别新算法准确率提升超30%,鸿鹄芯片彰显AI落地新打法
2019-11-29 15:57:45爱云资讯1150
今年 7 月,在开发者大会上,百度公布了其在 AI 技术上的进展。而短短四个月后,在昨日的百度语音能力引擎论坛上,百度在语音领域再次公开了最新的算法成果。同样引人关注的还有百度鸿鹄芯片的最新进展。
昨日,百度语音能力引擎论坛在北京召开。在论坛上,百度展示了其在语音技术上的最新成果,并公开了语音专用终端芯片——百度鸿鹄的落地情况。此外,机器之心也采访了百度语音首席架构师贾磊。百度通过本次发布说明,深度学习端到端技术依然大有发展空间,软件驱动专用芯片设计成 AI 落地新打法。
语音能力 100 亿次日调用,百度大脑势头正劲
论坛开始,百度 CTO 王海峰博士公布了百度在语音技术方面的最新成绩单。目前,百度语音技术的日调用量已突破 100 亿。

而目前,百度大脑已开发 AI 能力 228 项,接入开发者数量超过 150 万,现已成为国内最大的 AI 开放平台。

王海峰博士还介绍了百度在 AI 方面的两大目标,即「进化」和「赋能」。通过技术的不断进化,推动 AI 的进一步发展,同时通过赋能合作厂商和开发者的方式,创造活跃的 AI 生态环境。
在发布会上,百度语音识别新算法和百度鸿鹄芯片的最新进展最引人注目。它们无疑是对进化和赋能两词最好的注解。
完全端到端,深度学习再次颠覆语音识别
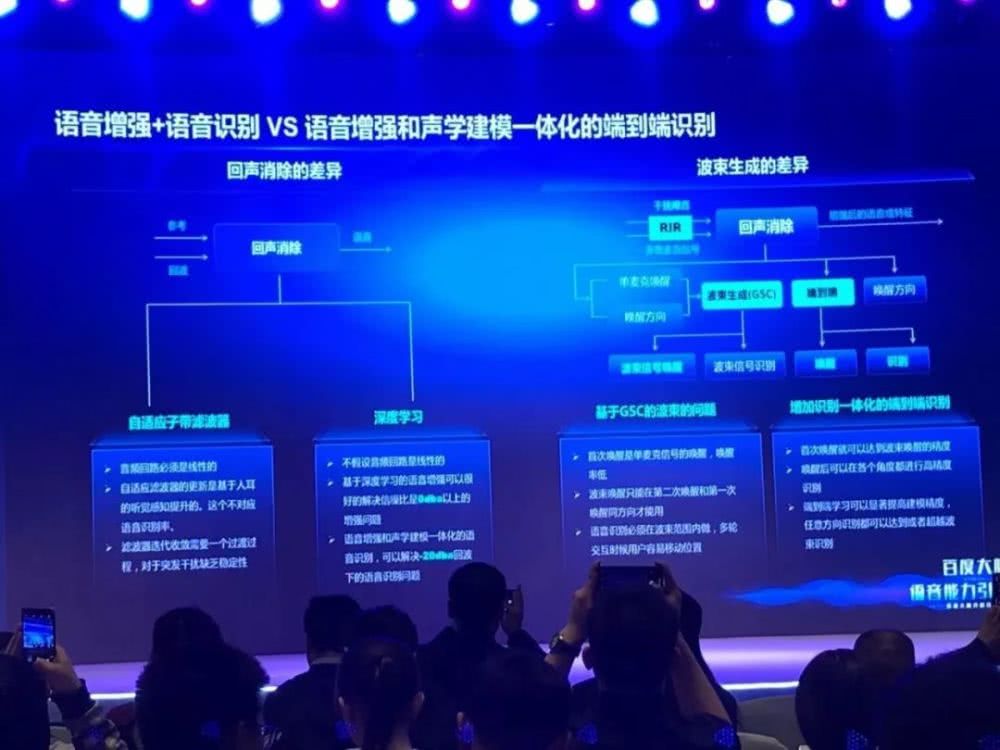
在论坛上,百度语音首席架构师贾磊介绍了百度近一段时间的语音技术突破。其中最受瞩目的便是百度最新研发的「基于复数 CNN 网络的语音增强和语音识别一体化建模」技术。
现有方法面临瓶颈
目前主要的远场语音识别方案主要将语音识别分为两个步骤:数字信号处理和语音识别。具体而言,用户首先需要对语音识别终端进行唤醒,当设备收到信号后,采用声学模型和硬件对波束来源进行定位,定位后再继续接收目标声音。
接收到目标声音后,识别终端通过方位信息,增强目标信号并压制干扰信号,从而将增强后的信号,输入到语音识别声学建模模块中。
这一方法主要存在两个问题。首先,语音增强算法大都是基于 mse 准则优化语音的听觉感知,听觉感知变得更清晰,并不一定对应识别率提升。其次,此方法需要首先唤醒语音识别终端,并要求说话者的位置保持固定。如果在识别过程中目标信号源发送移动,或波束方向上存在噪声,则识别准确率会大幅下降。
深度学习让信号处理和语音识别终成一体
而百度提出的新算法不再需要首次唤醒。在识别开始时,目标声音信号直接被多路麦克风输入到模型中,采用复数个 CNN 网络提取声音信号中的多种特征,包括不同麦克风输入信息的特征,和跨频率耦合的声学特征。在这一过程中直接实现了前端声源定位、波束形成和增强特征提取。特征提取后,直接进行声学建模,并生成最终的文字结果。

据贾磊介绍,这一算法从根本上打通了前端的信处理和后端语音识别过程,真正实现了端到端的语音识别解决方案。该算法具有以下优势。其一,这一算法不需要事先根据前一个唤醒词的方向来定人的说话方向,定出人说话方向之后,再做波束生成,这样的话,波束生成只能对下一句话的唤醒或者是识别有提升作用。这个方法是根据当前唤醒词或者是语音指令,一次性的同时做声源定向和波数生成。使得当前这一个次唤醒或者是识别就能够显著提升。
其次,由于使用 CNN 网络捕捉多种特征,因此能够最大程度捕捉声音波形中的最本质特征信息,尤其是跨频波形特征等,因此能够模型具有更好的学习能力,性能也更好。
另外,模型最终端到端直接输出文字结果,通过字错误率进行调优,因此能够最大限度上优化模型性能。

由于没有了波束定位的环节,这一方面面临的挑战在于,如何能够区分多个声音源,并只识别真正的目标声音源。
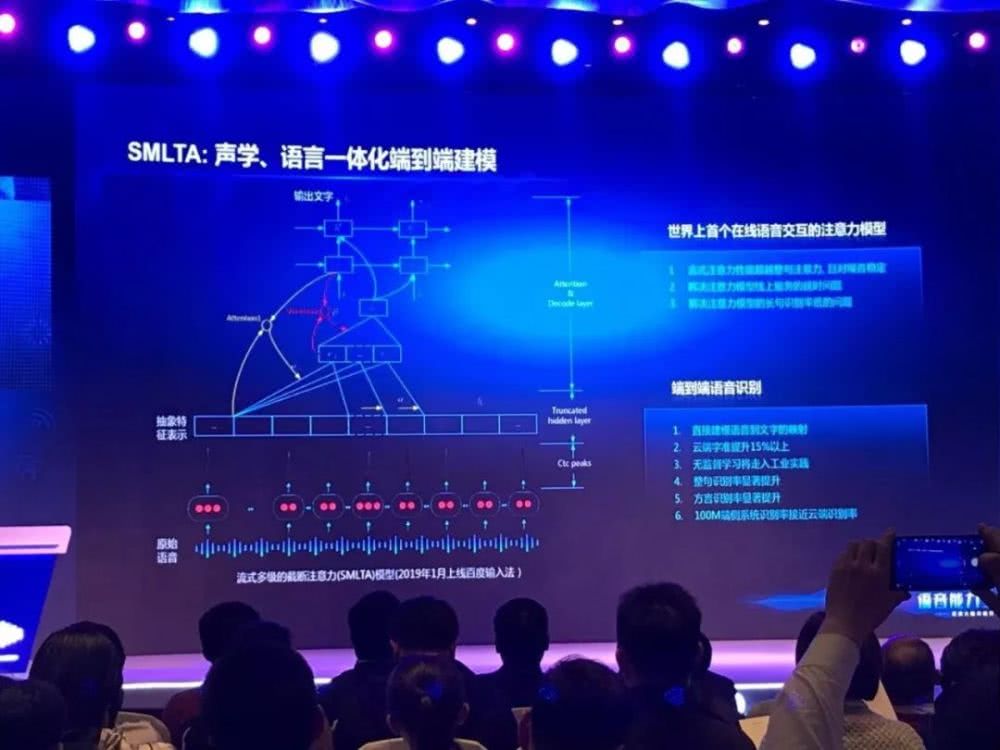
在采访中,贾磊提到,在多个声源存在的情况下,该算法可结合语义信息进行区分。这是因为算法中融合了 SMLTA 架构,能够进行从语音到语言文字的映射,因此可以学习到语义知识。在识别过程中,算法可根据语义,选择正确的 query。

据悉,这一算法的识别准确率(即字错误率)提升超过 30%。和百度鸿鹄 AI 芯片配合使用的情况下,甚至可以提升更多。
在语音转文字方面,百度公开了 SMLTA 算法方面的最新成果。目前该算法能够识别更多方言、中英文混输等场景上也进一步提升。通过和端到端方法结合,百度已彻底实现了从语音输入、信号处理和增强、语音识别到文字输出的完全端到端深度学习解决方案。
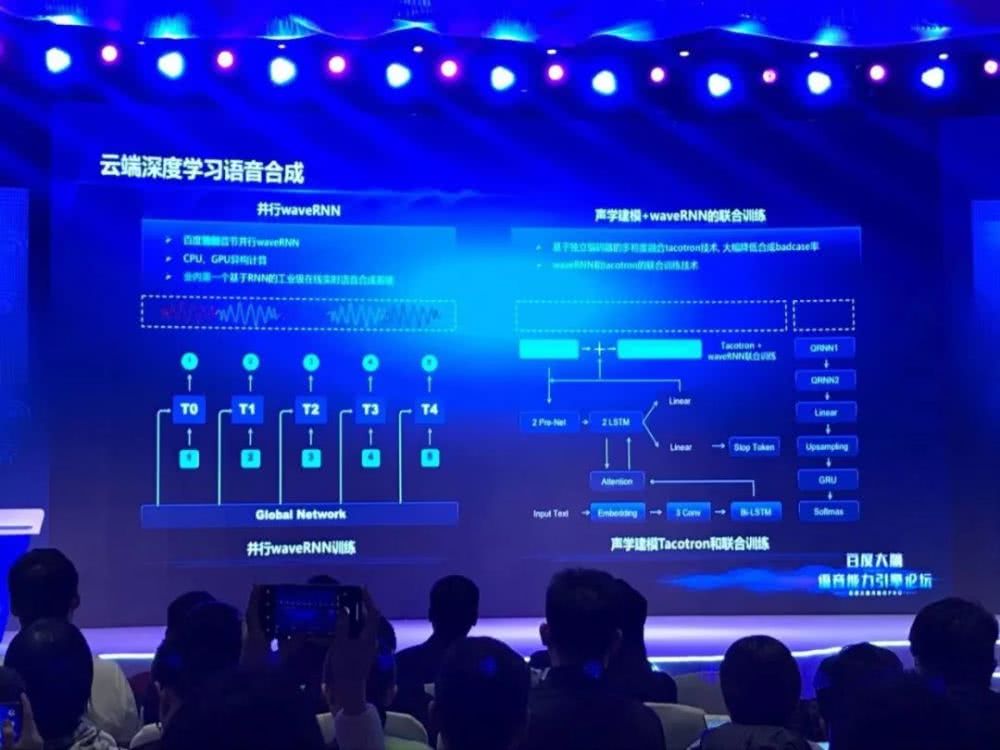
此外,论坛上,贾磊也介绍了百度在语音合成方面的技术进展。通过 WaveRNN 算法的进一步改进,模型可提取人声中的通用特征,结合被合成者特有的声学特征,最终输出合成语音结果。
目前百度已实现无监督的语音合成模型训练,并应用于百度地图产品上。用户只需要输入 20 句话,就可以使用合成语音进行地图导航等操作。
百度鸿鹄芯片:用硬件落地算法
除了最新的语音技术进展,百度也公开了百度鸿鹄芯片的最新进展。百度鸿鹄芯片是百度第一款专门针对语音技术领域开发的 AI 芯片,是百度推动语音识别能力落地应用的新打法。
语音能力集于一芯
据百度度 AI 技术生态部总经理喻友平介绍,百度鸿鹄芯片已集成了语音方面的所有能力,包括波束定位、语音信号增强、回声处理、降噪、语音识别等方面的所有功能。整个芯片提供了完整的解决方案。
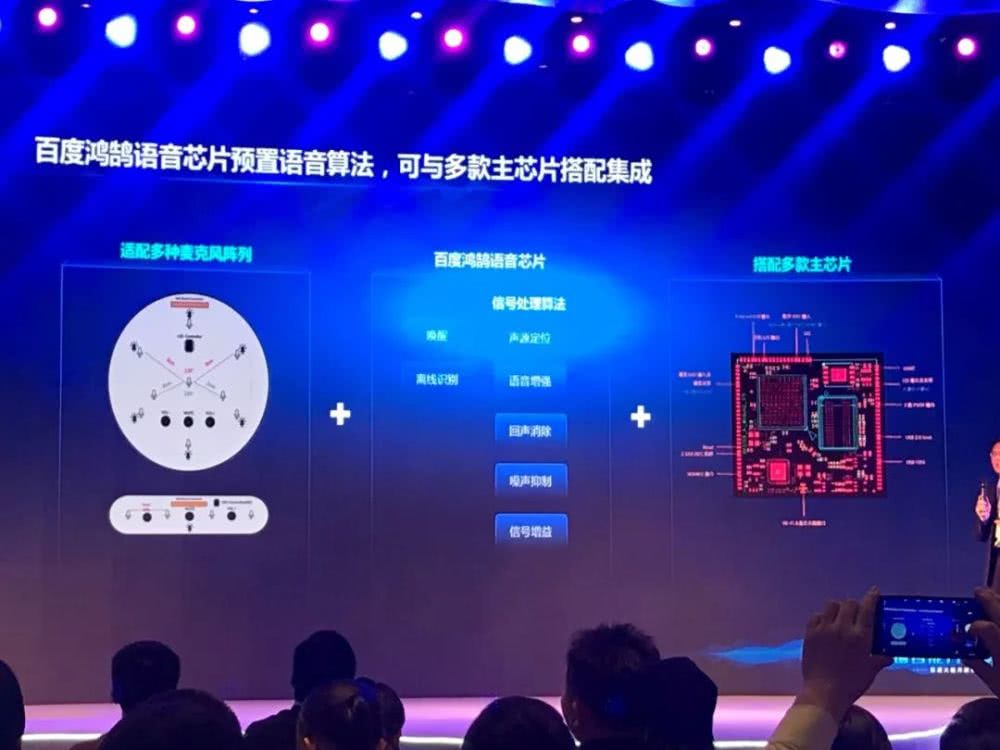
目前,百度鸿鹄芯片已提供了相关的硬件模组,包括安卓开发板等。同时,百度也邀请到了合作厂商,展示集成了百度鸿鹄芯片的智能家电——如创维智能电视等,在语音识别赋能后产生的新交互体验。

目前,百度已经完成了百度鸿鹄的智能音箱的产品原型。产品使用双麦克结构,将百度鸿鹄芯片作为语音处理芯片,来处理所有的语音的功能和任务,并最终集成到远场语音交互方案中。
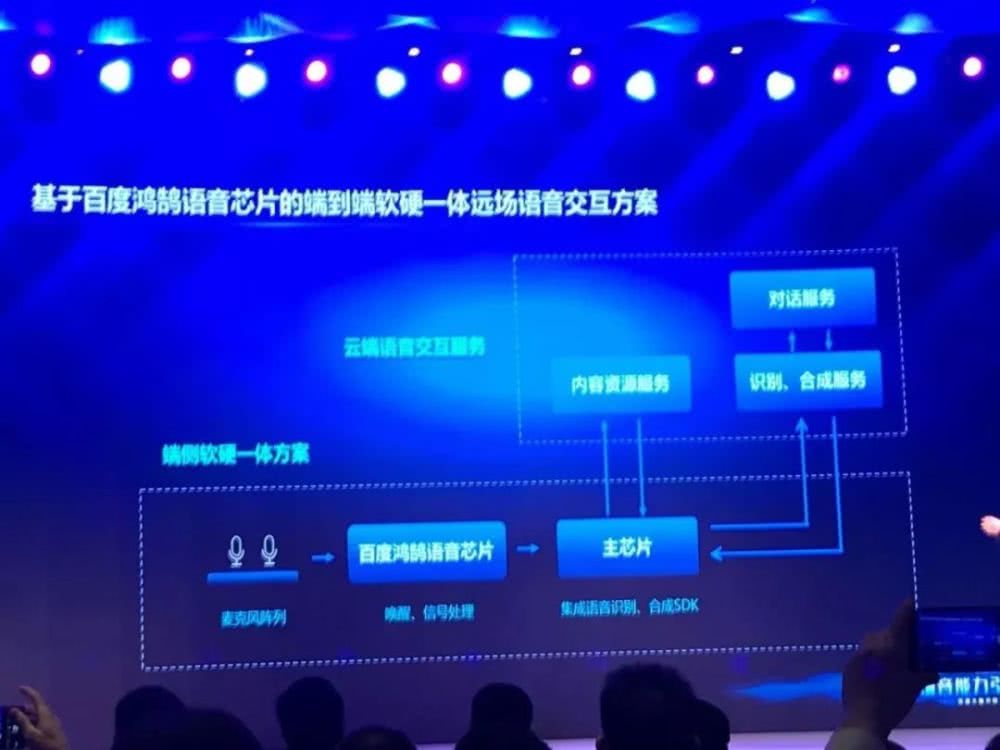
专用芯片让语音识别模型真正落地
为什么要为语音技术设计专用芯片,通过发布可以看到,百度鸿鹄芯片能够满足了落地深度学习算法的要求。首先,深度学习需要大量的内存占用、计算并行化能力,更要求芯片的 Cache 足够大,模型的加载速度要够快。ARM 架构的通用芯片在这些指标上多有不及,只有专门为深度学习设计的架构和指令集能够让模型在专用硬件上发挥更好的性能。
同时,相比 ARM 架构芯片,百度鸿鹄芯片可以更加低功耗。百度本次发布的新算法在百度鸿鹄芯片上,在待机状态下功耗不足 100mW。我国节能家电标准要求待机状态功耗不高于 0.5W,有了百度鸿鹄芯片,各类家电可以集成语音识别能力,也同时满足节能家电的认证标准。
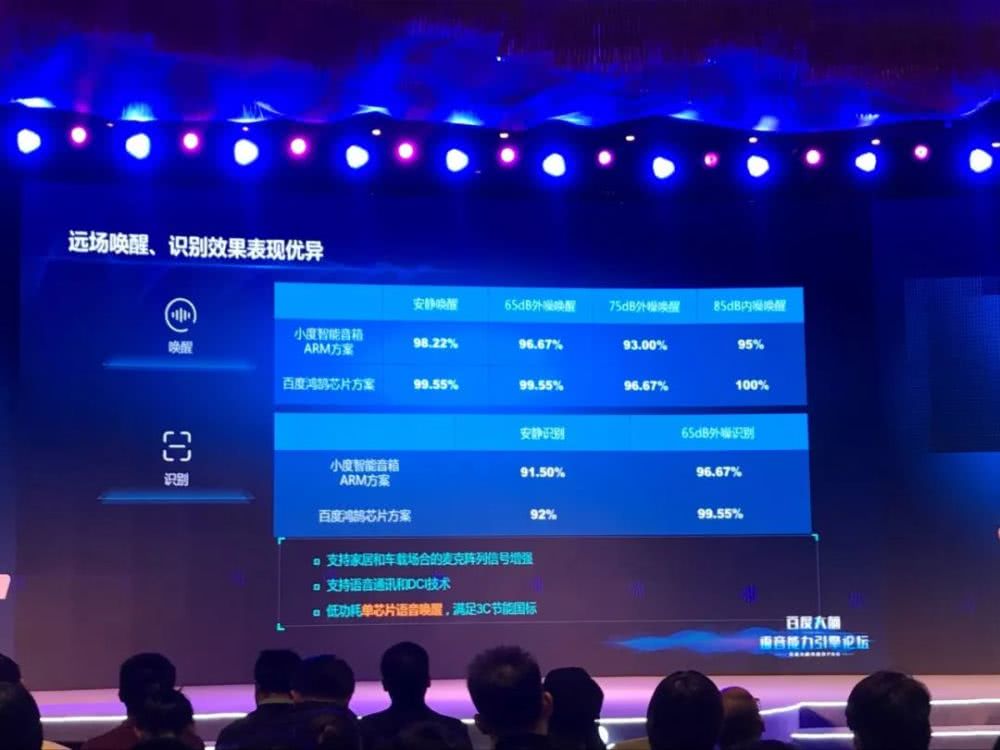
据贾磊介绍,本次公开的端到端算法在百度鸿鹄芯片上只占用 200K 的内存,可完全实现终端语音识别功能。
这样一来,以百度鸿鹄芯片为载体,以算法为核心,百度实现了通过提供硬件和算法的方式,将语音能力赋予合作商和开发者,实现了整体解决方案的开源开放。
本次论坛上,百度还介绍了其语音生态中的很多新产品和应用,说明了百度 AI 生态的日臻成熟。
语音技术落地体现百度新打法
通过本次论坛发布可以看出,百度的 AI 落地新打法已呼之欲出。在新技术的开发上,百度全面采用深度学习方式,进一步扩展 AI 能力和应用场景。在技术的落地环节,则通过软件驱动硬件发展的方式,让专用硬件承接算法模型,最终实现技术赋能。
深度学习推动跨学科融合
在谈到基于复数 CNN 网络的语音增强和语音识别一体化建模技术时,贾磊表示,这一技术说明了深度学习在推动跨学科融合方面的能力。
换句话说,通过端到端技术,百度实现了信号处理和语音识别两个部分的融合。在前端信号处理的过程中,不再需要考虑声学模型和相关的先验知识,从语音信号的输入到输出文字完全模拟人类的认知过程。
采访中贾磊表示,尽管目前深度学习看似进入到了「平台期」,但在端到端跨学科整合方面,其仍有很大的发展空间。
软件驱动芯片设计
在算法落地赋能方面,可以看到百度用「软件驱动芯片设计」的发展战略。在百度大脑开放了众多 AI 能力的时候,百度根据算法对硬件的要求,定制相应的硬件设备。相比传统的芯片厂商,这些专用芯片都是根据模型的大小、特性和计算方式特殊定制的,只有掌握算法细节的厂商才能够定制开发。
这样的算法落地方式无疑有着独特的优势。首先算法能够和硬件深度结合,通过硬件开放的方式融合到各类场景中,发挥最佳的性能。
此外,硬件能够提供更为端到端的解决方案,显著降低算法落地的成本。例如,百度鸿鹄芯片整合了语音识别中的所有能力,提供了综合的解决方案。这样在落地算法的过程中,合作商不再需要关心各种算法的运行情况,以及和硬件适配的相关问题。
同时,专用芯片的功耗更低,在保证模型性能的同时,不会对集成的系统(如家电产品等)带来很高的功耗。
从这些新打法中可以看出百度的坚持和创新探索。不变的是百度对深度学习算法的坚持。即使目前深度学习看似进入平台期,但百度持续推动深度学习以端到端的方式进入新的场景,逐渐取代需要过去传统学科长期积累和大量先验知识的领域。
与此同时,百度仍在探索 AI 落地的新形式。鸿鹄芯片的公布无疑是其以互联网企业的方式进入到芯片设计领域的新思路。围绕算法对算力和硬件的需求,定制专用的硬件,让算法更好地发挥性能优势,也在同时降低厂商合作落地 AI 的成本和门槛,实现其让 AI 进化和赋能行业生态的目标。
相关文章
- 重新定义出行体验,雅迪携手百度地图打造“所见即所达”
- 鸿蒙版百度地图融合DeepSeek,一句话get智慧出行服务
- 向新而行 合作共赢 百度短剧实现精品化突围
- 2025中关村论坛丨百度王海峰:看到通用人工智能曙光
- 新技术新赋能 百度短剧助力优质内容破圈成长
- 百度发布文心4.5与X1大模型,微美全息软硬协同算力生态树立AI典范
- 无代码+多智能体协作!百度“秒哒”全量上线,人人皆可程序员
- 首发AI搜索功能!华为Pura X上的鸿蒙版百度重构AI搜索体验
- 百度营销全面接入DeepSeek,一键生成广告创意、商家智能体交互再升级
- 百度与宁德时代:牵手成功!
- 百度短剧:生态赋能下的行业新航向——从流量盛宴到长效价值重塑
- 苹果加快引爆技术竞赛新格局,百度/微美全息DeepSeek开源生态重构商业版图
- 双引擎驱动:百度百舸携手昆仑芯,保障DeepSeek稳定安全部署
- 百度成功点亮昆仑芯三代万卡集群,将于近日点亮3万卡集群
- 百度商家智能体年度回顾:帮助万千商家省人、省钱、省心
- 强强联合!美的与百度本地生活达成战略合作,超2万家门店将入驻本地生活





