百度语音的“一小步”,可能是语音技术“登月计划”的一大步
2019-01-17 17:03:32爱云资讯738

语音作为人机交互的全新入口,已经在过去几年席卷全世界。语音技术的进步,不仅体现在各式各样的智能设备里,还在不断赋能移动设备输入法的变革,依托语音便捷的交互方式,输入法里语音输入也在悄然改变着用户与设备交互的模式。
在技术领域,某些影响深远的技术研发往往被称为「登月计划」。本周,百度在语音领域的「一小步」,也实现了人类语音「登月」的一大步。
在百度输入法发布会上,百度公布了语音领域的四项重大技术突破。这其中,在线语音领域全球首创的流式多级的截断注意力模型(SMLTA,全称为「Streaming trancated multi-layer attention」)成为焦点,这也意味着,学术界谈论多年的注意力模型终于实现了大规模在线商用。

此举意义重大。一方面,这是业界第一个基于注意力模型的在线语音产品,凸显出百度在语音技术研发的领先;另一方面,作为 AI 的基础功能,语音技术在百度 AI 技术赋能产品创新的作用越来越大,这也是当下百度 AI 战略落地的重要观察窗口。
接下来,本文将从此次公布的流式多级的截断注意力模型入手,揭秘这项技术背后的意义,同时结合语音技术赋能百度其他产品线的案例,进一步探讨这家公司的 AI 战略方向。
1. 技术突破:学术界一大难题的落地
过去几年,AI 被诟病的一大原因就是技术落地困难,一项实验室的技术即便再怎么先进,倘若无法再商业化的场景里得以应用,多少都有些当代「屠龙术」的意味。
比如语音领域的注意力模型(Attention模型)。
注意力模型是一种基于对一句话里每个音节或汉字音频特征的机器学习模型。通过机器学习的方法,将音频特征自动挖掘出来。也就是说,这种方法下的语音识别过程,变成了一个字一个字的滚动生成过程。
由于摆脱了传统语音识别的状态建模和按语音帧进行解码,该模型可以直接实现语音和文本一体化的端到端建模,拥有学术界公认的建模精度。
但这个技术长期以来无法得以大规模应用。一方面,无法解决流式解码的问题,传统的注意力模型大都是基于整句的建模,比如 Google 的 LAS 模型就是其中的代表。整个建模过程需要通过云端/服务器的解码能力。这也意味着,当用户通过语音交互时,语音需要上传到云端,这对于移动设备的用户体验影响非常大。
另一方面,如上文所言,在传统的注意力模型里,一般是通过机器学习提取整句音频信息,也就是说语音输入的句子越长,进行特征选择的难度越大。出错的概率越高,而一旦某个环节出现错误,错误的传导还会进一步提过错误率,最终反映在用户体验上的感受则是,用户语音说完一段话后,机器完全理解不了。
这也是此次百度流式多级的截断注意力模型 SMLTA 所要解决的难题。主要包括两个重要的技术突破,其一,利用 CTC 语音识别算法,对连续语音进行自动截断,然后在这一系列语音小段的基础上搭建注意力模型。其二,引入一种特殊的多级Attention机制,实现特征层层递进的更精准的特征选择。
根据百度官方的说法,由于所有计算通过 CPU 实现,不需要额外增加GPU,整个云端的计算资源消耗与此前的语音模型持平。而在输入法精度上,大量数据测试结果显示,相对于早先的模型,相对准确率提升了 15%。
更重要的是,这不仅是业界第一次提出了流式多级的截断注意力模型 SMLTA,也在全球范围内,实现了基于注意力模型的在线语音识别服务的首次规模化应用。百度已成功将这种注意力模型部署上线到语音输入法全线产品,服务中国数亿用户,也因此,此次技术突破不再仅仅是一个实验室技术的展现,而是成为一个个普通用户都可以享受的技术红利。
2. 赋能:从内到外
一年前的百度输入法升级里,基于 Deep Peak 2模型的语音模型,大幅提升了不同场景下语音识别的准确率。而一年后,输入法升级还带来了离线语音、中英混合输入、普通话方言混合输入的升级。
这其中,离线语音识别的场景最特殊。由于语音识别需要网络的支持,当没有网络或者网络稳定的时候,常常出现语音识别成功率低、识别速度慢等情况。
虽然通过离线语音已解决一部体验问题,但过去离线语音与在线语音相比,准确率相差悬殊,体验得不到根本解决。
针对这一场景,百度语音技术团队优化了输入法上嵌入式识别的 deep peak2 系统,大幅提升了离线语音识别准确率。根据百度透露的数字,目前百度输入法离线语音输入准确率已高于行业平均水平35%,这也让用户可以在没有网络的场景里流畅快速使用。
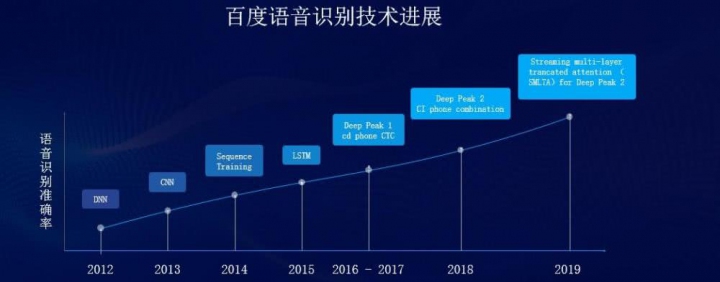
上述注意力模型等一系列技术创新也是百度语音技术推动产品发展的一个缩影。
比如地图。去年 12 月的新版地图里,语音就作为一个重要的交互方式,涵盖了导航路线、地点查找以及小度助手等等。
而在翻译领域,去年 10 月,百度研发的具备预测能力和可控延迟的即时机器翻译系统,实现了两种语言之间的高质量、低延迟翻译。这其中,通过上下文无关音素组合的中英文混合建模单元,让语音识别的方法具有泛化性能好、对噪声鲁棒、中英文混合识别等特点。
与此同时,正如百度高级副总裁、AI技术平台体系(AIG)总负责人王海峰在百度大脑论坛上所言,「百度大脑既带动了百度业务的升级,也在推动社会智能化升级」。与行业其他 AI 巨头们目前的策略一致,语音技术不仅是百度多个产品线创新的动力,也已经并正在通过百度大脑向行业赋能。
以远场识别算法为例,通过麦克风阵列前端处理算法,可以识别目标说话人 3-5米距离的说话。目前,基于语音远场方案技术的「小度机器人人机语音交互点餐」已在上海肯德基旗舰店投入应用。
2018 年的百度世界大会上,百度大脑也带来多个语音技术升级。比如「一次唤醒连续交互」的技术突破,用户只需唤醒一次就可以连续多轮对话,机器能够准确识别用户说话时的犹豫停顿、能够区分并跟随首次唤醒的用户等,用户的体验更自然、流畅,为语音交互提供了更多想象空间。
3. 写在最后
作为当下 AI 的一个单项技能,语音技术依然有巨大的突破空间。一方面,语音识别在安静环境、普通话识别的识别率的确已经比较高了,但在复杂环境以及口音、方言等环境里的识别率还不尽如人意。
另一方面,语音技术不仅是声音与文字之间的转换问题,也不是单纯的软件或硬件问题,面向未来的语音技术是硬软一体、语音语言一体、识别和交互一体。
百度这次推出的流式多级的截断注意力模型SMLTA,无疑是中文在线语音识别历史上的又一次突破。
而未来,百度语音的重要着力点是向下朝低端芯片发展,向上超语音语义一体化和交互发展。最终,百度语音将建立从硬件底层芯片、到上层的智能硬件系统,再到系统软件,语音客户端,语音服务器及后端交互一体化的全链路语音交互技术。
基于百度庞大的用户和丰富的产品,这些技术将让用户享受 AI 的福利,而透过百度大脑,还将持续赋能各行各业。





