7nm工艺竞赛升级 eFPGA架构创新为人工智能加速
2018-12-02 14:24:35爱云资讯1539
人工智能应用的新需求给FPGA带来了历史性的发展机遇,FPGA强大的并行计算能力、高能耗比、灵活的编程等优势,决定其将在人工智能舞台中将发挥重要作用。但同时人工智能强大的数据运算能力、传输存储能力等特性也对成本和功耗能效等提出新要求,如何处理这些问题需要从工艺来着手,核心架构的研发创新以及多种工具的支持,先进制程工艺都可以让芯片性能得到提高,而且功耗更低。并且一旦开始大规模的生产此类芯片,其制造成本就会大大下降,从而获取更高的盈利。可以说先进的制造工艺和核心架构能让FPGA抢占利润更为丰厚的AI市场。目前,大部分的FPGA芯片都是基于28nm和20nm工艺,但随着AI、5G等新应用需求,16nm、7nm等更先进制程的FPGA芯片将在2019年逐步放量,带来FPGA市场的一轮新的竞争。同时也为拥有新工艺技术实力的公司带来新机遇,有望在FPGA长期寡头垄断的市场里撞出新火花。而Achronix就是这其中的后起之秀,其FPGA的硬件加速器器件和高性能嵌入式FPGA半导体知识产权(eFPGA IP)凭借出色的工艺近年来取得的快速发展。

Achronix市场营销副总裁Steve Mensor
近日,《华强电子》记者在采访Achronix市场营销副总裁Steve Mensor时获悉,其第四代新的Speedcore Gen4 eFPGA架构已经推出,采用台积电7nm工艺节点,主要针对新兴人工智能/机器学习和高数据带宽应用的爆炸式需求,将于2019年上半年投入量产。
Steve表示:“Speedcore IP是可以集成到ASIC和SoC之中的嵌入式FPGA(eFPGA)。客户通过定制其逻辑、RAM和DSP资源需求,Achronix接下来就会为其配置满足其需求的Speedcore IP,Speedcore查找表(LUT)、RAM单元模块和DSP64单元模块可以像乐高积木一样进行组合,以便为特定的应用创建优化的可编程功能。在Speedcore IP的交付包中,也包括一个对Speedcore IP进行编程的ACE设计工具个性化版本。与之前一代的Speedcore 嵌入式FPGA(eFPGA)产品相比,Speedcore Gen4的性能提速60%、功耗降低50%、芯片面积缩小65%;新的机器学习处理器(MLP)单元模块为人工智能/机器学习(AI / ML)应用提供高出300%的性能。”接下来Steve为记者详细介绍了Speedcore Gen4新架构主要通过哪些创新来实现能效的显著提升的。
架构性创新是提高系统性能的核心
与上一代Speedcore产品相比,新的Speedcore Gen4架构采用7nm工艺制程,在逻辑单元模块中的布线布局、矩阵乘法、查找表等方面实现了多项创新,从而可将系统整体性能提高60%。
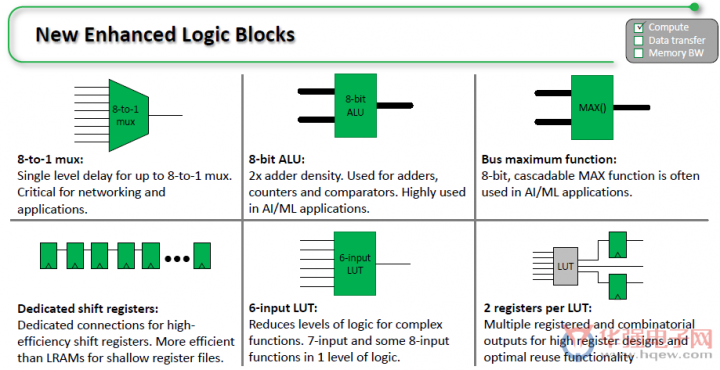
新增强的逻辑模块
其中的路由架构也借由一种独立的专用总线路由结构得到了增强。新的总线路由是高性能专用总线分组路由通道,总线路由与标准路由通道分离,以确保无拥塞。在内存和MLP之间运行的总线优化,创建巨型分布式运行时可配置交换网络。这为高带宽和低延迟应用提供了最佳的解决方案,并在业界首次实现了将网络优化应用于FPGA互连。
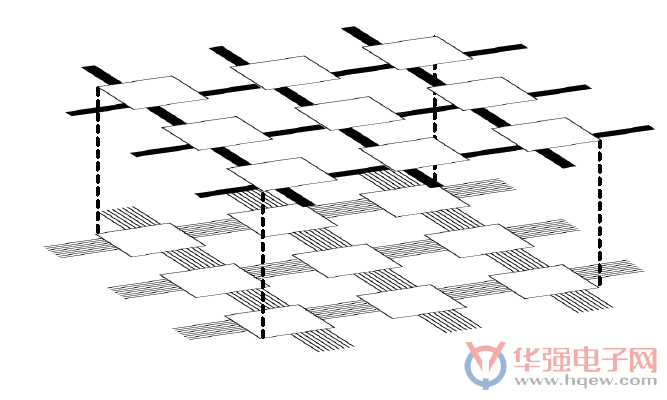
高速核心下一代布线架构
矩阵向量乘法将行划分成块,大型矩阵通常将与矩阵的一行相关联的单个乘积和划分成多个循环。例如: 将32个乘积的和分为8个乘积的四个部分和,累积四个连续的部分和,以计算每行的积的总和。第一个输出的总和在第四个时钟周期结束时完成。对接下来的四个时钟周期进行相同的处理,以计算和组合与第二输出相关联的四个部分和。
基于循环寄存器的块矩阵矢量乘法,循环寄存器允许向量数据被存储和重用。在并行操作中显示多个MAC操作的例子,读取矢量的四个子块并将数据写入循环寄存器文件。
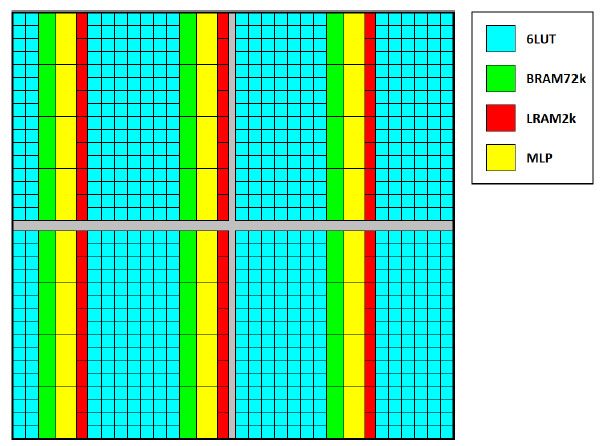
新型纵向连接和MLP级串联路径
其中查找表的所有方面都得到了增强,以支持使用最少的资源来实现各种功能,从而可缩减面积和功耗并提高性能。其中的更改包括将ALU的大小加倍、将每个LUT的寄存器数量加倍、支持7位函数和一些8位函数、以及为移位寄存器提供的专用高速连接。使用LUTS构建附加乘法器,使得有价值的低精度乘法通过最有效的FPGA来实现。
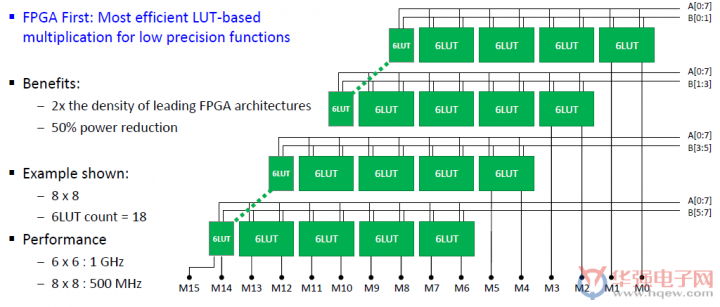
基于GE4LUT的乘法器:比其他FPGA架构更有效
另外,核心架构的研发创新同时能满足多种工具的支持也是非常重要的。Achronix的ACE设计工具中包括了Speedcore Gen4 eFPGAs的预先配置示例实例,它们可支持客户针对性能、资源使用率和编译时间去评估Speedcore Gen4的结果质量;Achronix现已可提供支持Speedcore Gen4的ACE设计工具。Speedcore采用了一种模块化的架构,它可根据客户的要求轻松配置其大小。Achronix使用其Speedcore Builder工具来即刻创建新的Speedcore实例,以便满足客户对其快速评估的要求。
最佳的人工智能/机器学习加速器
正是基于以上新架构的技术,使得Speedcore Gen4对人工智能/机器学习应用的高密度和针对性计算产生了显著增加的需求。与以前的Achronix FPGA产品相比,新的Achronix机器学习处理器(MLP)利用了人工智能/机器学习处理的特定属性,并将这些应用的性能提高了300%。这是通过多种架构性创新来实现的,这些创新可以同时提高每个时钟周期的性能和操作次数。
新的Achronix机器学习处理器(MLP)是一个完整的人工智能/机器学习计算引擎,支持定点和多个浮点数格式和精度。每个机器学习处理器包括一个循环寄存器文件(Cyclical Register File),它用来存储重用的权重或数据。各个机器学习处理器与相邻的机器学习处理器单元模块和更大的存储单元模块紧密耦合,以提供最高的处理性能、每秒最高的操作次数和最低的功率分集。这些机器学习处理器支持各种定点和浮点格式,包括Bfloat16、16位、半精度、24位和单元块浮点。用户可以通过为其应用选择最佳精度来实现精度和性能的均衡。
为了补充机器学习处理器并提高人工智能/机器学习的计算密度,Speedcore Gen4查找表(LUT)可以实现比任何独立FPGA芯片产品高出两倍的乘法器。领先的独立FPGA芯片在21个查找表可以中实现6x6乘法器,而Speedcore Gen4仅需在11个LUT中就可实现相同的功能,并可在1 GHz的速率上工作。
解决带宽爆炸问题 目标市场的现在与未来
那么采用台积电7nm工艺节点的Speedcore Gen4,主要针对新兴人工智能/机器学习和高数据带宽应用的爆炸式需求外,还有哪些目标市场呢?Steve向《华强电子》表示,计算加速度,网络加速,5G基础设施, 智能驾驶这些都是他们的目标市场。这些应用程序具有相同的要求:高性能、低功耗、低延迟、可编程硬件加速器。过去几年,存储和网络主导了FPGA用户群,但未来几年,计算端的需求将远远超过存储和网络,并都将沿着稳定的增长线继续发展,在机器学习,高性能计算,数据分析等领域,FPGA将更有用武之地。Steve尤其看好网络加速和5G市场的应用前景,比如在5G基础设施方面的压缩/减压,非结构化数据匹配 ,数据库加速,适应前沿标准的协议适应性,基带和分裂L1加速,基于人工智能的波束形成,放大器预失真,移动边缘计算这些细分市场都对高性能FPGA有着强烈的需求。
在网络加速方面,固定和无线网络带宽的急剧增加,加上处理能力向边缘等进行重新分配,以及数十亿物联网设备的出现,将给传统网络和计算基础设施带来压力。这种新的处理范式意味着每秒将有数十亿到数万亿次的运算。传统云和企业数据中心计算资源和通信基础设施无法跟上数据速率的指数级增长、快速变化的安全协议、以及许多新的网络和连接要求。传统的多核CPU和SoC无法在没有辅助的情况下独立满足这些要求,因而它们需要硬件加速器,通常是可重新编程的硬件加速器,用来预处理和卸载计算,以便提高系统的整体计算性能。经过优化后的Speedcore Gen4 eFPGA已经可以满足这些应用需求。
另外,对于FGPA成本这个问题,Steve也给出了肯定的答复,采用新架构新工艺的最新Speedcore eFPGA IP,和上一代产品基本持平,不会增加用户成本。对于已量产的Speedcore架构,Achronix可在6周内为客户配置并提供Speedcore eFPGA IP和支持文件。采用台积电7nm工艺节点的Speedcore Gen4将于2019年上半年投入量产,Achronix还将于2019年下半年提供用于台积电16nm和12nm工艺节点的Speedcore Gen4 eFPGA IP。
但Speedcore Gen4已经有市场实例,Micron日前推出GDDR6存储器就是采用Achronix台积电7nm工艺技术的FPGA芯片,实现了高达16 Gb / s的吞吐量。GDDR6针对包括机器学习等诸多要求严苛的应用进行了优化,这些应用需要数万兆比特(multi-terabit)存储宽带,从而使Achronix在提供FPGA方案时,其成本能够比其他使用可比存储解决方案的FPGA低出一半。
相关文章
- Flyme 9.2+7nm芯片?驯龙高手魅族 18X拒绝高价低配!
- 紫光股份7nm路由芯片揭秘:超过500核心、今年底流片
- 三星新手机发布:7nm芯片+7000毫安时大电池
- 外媒:四季度台积电7nm工艺最大客户是高通
- Redmi Note 9搭载天玑800U,7nm中端神U高性能越级
- 加速全民5G普及,联发科发布7nm 5G芯片天玑700
- Intel表态已解决7nm工艺技术问题:进展惊人
- 最新7nm锐龙装机,绕不开技嘉这两款A520主板
- 台媒:台积电大客户将迎来出货旺季,7nm/5nm订单供不应求
- 倪光南:不能用7nm芯片主要影响手机 新基建不受影响
- 世界最大AI处理器升级7nm工艺:85万核心、2.6万亿晶体管
- 中兴:有20年设计经验 没有生产和制造7nm、5nm芯片能力
- AMD三款EPYC Milan CPU工程样片7nm+Zen3架构
- 搭载AMD 7nm处理器,宏碁传奇后浪本享受轻薄体验
- AMD五六代锐龙齐曝光:7nm Zen3连用两代、5nm Zen4再等等
- 寒武纪披露 7nm云端智能芯片预计2021年形成规模化收入





