和 DeepMind 一起考虑如何在 AI 中重现人类的价值观
2018-11-26 10:51:07爱云资讯阅读量:746
但我们同时也面对着一个新问题,就是随着人类用模型做出越来越多的决策,模型所看重的因素真的和设计它的人类所希望的一样吗?又或者,模型完全捕捉了设计者提供的数据中的模式,但数据本身却含有设计者没有意识到的偏见。这时候我们又要怎么办?
DeepMind 安全团队的这篇文章就对相关问题做出了一些讨论、提出了一些见解。它概述了 DeepMind 近期一篇论文《Scalable agent alignment via reward modeling: a research direction》中提出的研究方向;这篇论文试图为「智能体对齐」问题提供一个研究方向。由此他们提出了一个基于奖励建模的递归式应用的方法,让机器在充分理解用户意图的前提下,再去解决真实世界中的复杂问题。雷锋网 AI 科技评论编译如下。

近些年,强化学习在许多复杂的游戏环境中展现出令人惊叹的实力,从Atari游戏、围棋、象棋到Dota 2和星际争霸II,AI智能体在许多复杂领域的表现正在迅速超越人类。对研究人员来说,游戏是尝试与检验机器学习算法的理想平台,在游戏中,必须动用综合认知能力才能完成任务,跟解决现实世界问题所需的能力并无两样。此外,机器学习研究人员还可以在云上并行运行上千个模拟实验,为学习系统提供源源不断的训练数据。
最关键的一点是,游戏往往都有明确的目标任务,以及反映目标完成进度的打分系统。这个打分系统不但能够为强化学习智能体提供有效的奖励信号,还能使我们迅速获得反馈,从而判断哪个算法和框架的表现最好。
让智能体与人类一致
不过,AI的终极目标是帮助人类应对现实生活中日益复杂的挑战,然而现实生活中没有设置好的奖励机制,这对于人类评价AI的工作表现来说形成了挑战。因此,需要尽快找到一个理想的反馈机制,让AI能够充分理解人类的意图并帮助人类达成目标。换句话说,我们希望用人类的反馈对AI系统进行训练,使其行为能够与我们的意图保持一致。为了达到这个目的,DeepMind的研究人员们定义了一个「智能体对齐」问题如下:
如何创建行为与用户意图保持一致的智能体?
这个对齐问题可以归纳在强化学习的框架中,差异在于智能体是通过交互协议与用户进行交流、了解他们的意图,而非使用传统的数值化的奖励信号。至于交互协议的形式可以有很多种,当中包括演示(模仿学习,如谷歌的模仿学习机器人)、偏好倾向(人类直接评价结果,如 OpenAI和DeepMind的你做我评 )、最优动作、传达奖励函数等。总的来说,智能体对齐问题的解决方案之一,就是创建一个能让机器根据用户意图运作的策略。
DeepMind的论文《Scalable agent alignment via reward modeling: a research direction》中概述了一个正面解决「智能体对齐」问题的研究方向。基于过去在AI安全问题分类和AI安全问题阐述方面所做的工作,DeepMind将描述这些领域至今所取得的进展,从而启发大家得到一个对于智能体对齐问题的解决方案,形成一个善于高效沟通,会从用户反馈中学习,并且能准确预测用户偏好的系统。无论是应对当下相对简单的任务,还是未来日趋复杂、抽象化的、甚至超越人类理解能力的任务,他们希望系统都能胜任有余。
通过奖励建模进行对齐
DeepMind这项研究方向的核心在于奖励建模。他们首先会训练一个包含用户反馈的奖励模型,通过这种方式捕捉用户的真实意图。与此同时,通过强化学习训练一个策略,使奖励模型的奖励效果最大化。换句话说,他们把学习做什么(奖励模型)与学习怎么做(策略)区分了开来。

奖励建模示意图:奖励模型基于用户反馈进行训练,以便更好地捕捉用户意图;同一时间,奖励模型为经过强化学习训练的智能体提供奖励。
过去DeepMind做过一些类似的工作,比如教智能体根据用户喜好做后空翻,根据目标示例将物件排成特定形状,根据用户的喜好和专业的演示玩 Atari 游戏(你做我评 )。在未来,DeepMind的研究人员们还希望可以研究出一套算法,让系统可以根据用户的反馈迅速调整自己去适应用户的行为模式。(比如通过自然语言)
扩大奖励模型规模
从长远来看,DeepMind的研究人员们希望可以将奖励模型的规模扩大至一些目前对人类评估能力来说还比较复杂的领域。要做到这一点,他们必须提升用户评估结果的能力。因此,他们也将阐述如何递归地应用奖励模型:通过奖励模型训练智能体,使其能在用户的评估过程中提供帮助。一旦评估变得比行为简单,也就意味着系统可以从简单的任务过渡至更加普遍、复杂的任务。这也可以看作迭代扩增(iterated amplification)的实例(详情见「超级 AI」的种子?复杂到人类难以评价的问题,可以教会一个 AI )。
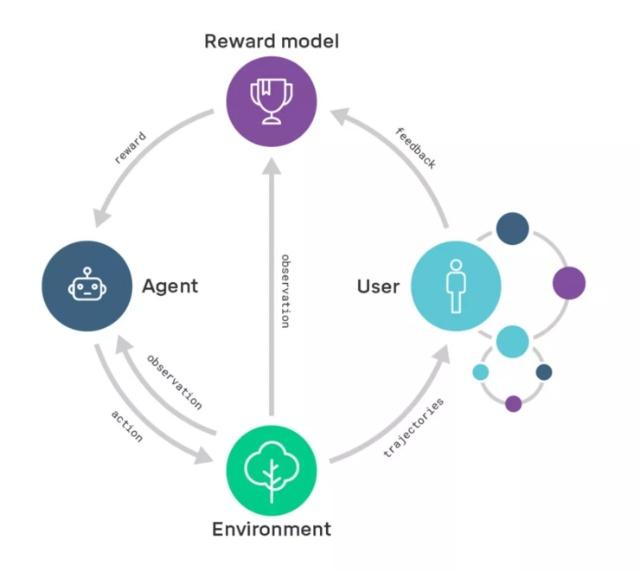
递归奖励模型的示意图:经过递归奖励模型训练的智能体(右边的小圈圈)将帮助用户评估由正在被训练的智能体(右边打圈圈)产出的结果
举例说明,比如想要通过训练智能体来设计计算机芯片,为了评估所提议的芯片设计的可行性,我们会通过奖励模型训练一组智能体「助手」,帮助我们完成芯片模拟性能基准测试、计算散热性能、预估芯片的寿命、发现安全漏洞等任务。智能体「助手」输出的成果帮助用户评估了芯片设计的可行性,接着用户可以据此来训练芯片设计智能体。虽然说智能体「助手」需要解决的一系列任务,对于今天的学习系统来说难度还是有点高,然而总比直接让它设计一个计算机芯片要容易:想设计出计算机芯片,你必须理解设计过程中的每一项评估任务,反之却不然。从这个角度来说,递归奖励模型可以让我们对智能体提供「支持」,使其能在和用户意图保持一致的情况下,去解决越来越难的任务。
研究面临的挑战
如果想将奖励模型应用到复杂的问题上,有几项挑战依然等待着我们去克服。下图展示了5项在研究中可能面临的挑战,对此感兴趣的同学可以查阅DeepMind论文,文中详细描述了这些挑战及对应的解决方案。
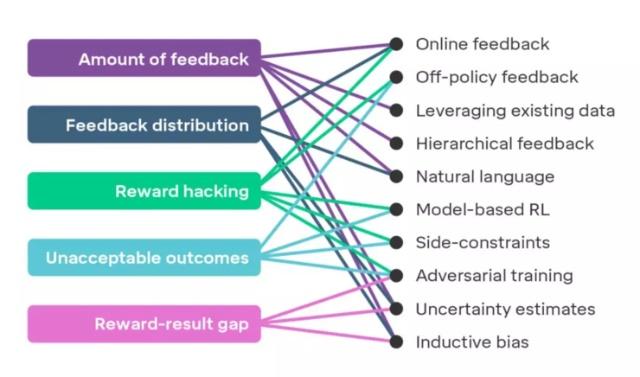
当我们扩大奖励建模时将会遇到的挑战(左侧)以及最有希望的解决方案(右侧)
这提醒了我们关于智能体对齐问题的最后一个关键要素:一旦要在现实世界中投入使用智能体,首先我们需要向用户证明这些智能体已经充分对齐。为此,DeepMind在文中提出了5项有助于提高用户对于智能体信任度的研究途径,它们是:设计选择、测试、可解释性、形式验证和理论保证。他们还有一个充满野心的想法,那就是为产品制作安全证书,证书主要用于证明开发技术的可靠性,以及增强用户使用训练智能体进行工作的信心。
未来的研究方向
虽然DeepMind的研究人员们深信递归奖励模型会是智能体对齐训练非常有前景的一个研究方向,然而他们目前无法预估这个方向在未来会怎么发展(需要大家进行更多的研究!)。不过值得庆祝的是,专注智能体对齐问题的其它几种研究方向也同时有别的研究人员正在做出成果:
模仿学习短视强化学习(Myopic reinforcement learning)(http://www.cs.utexas.edu/~bradknox/TAMER.html)逆强化学习(Inverse reinforcement learning)(http://ftp.cs.berkeley.edu/~russell/papers/colt98-uncertainty.pdf)合作逆强化学习(https://arxiv.org/abs/1606.03137)迭代扩增(复杂到人类难以评价的问题,可以教会一个 AI )通过争论学习(人和人吵架生气,但 AI 和 AI 吵架反倒可以带来安全 )智能体基础组件设计(Agent foundations)(https://intelligence.org/files/TechnicalAgenda.pdf)DeepMind也在文中探讨了这几种研究方向的异同之处。
如同计算机视觉系统对于对抗性输入的鲁棒性研究对当今的机器学习实际应用至关重要,智能体对齐研究同样有望成为机器学习系统在复杂现实世界进行部署的关键钥匙。总之,人类有理由保持乐观:虽然学术研究上很可能会在试图扩大奖励模型时面临挑战,然而这些挑战都是一些有望解决的具体技术性问题。从这个意义上说,这个研究方向已经准备就绪,可以对深度强化学习智能体进行实证研究。
协助课题研究取得进展是DeepMind日常工作中很重要的一个主题。如果作为研究者、工程师或者有天赋的通才,有兴趣参与DeepMind的研究中来,DeepMind也欢迎他们申请加入自己的研究团队。
相关文章
- DeepMind开发AI程序员,称可达人类中等水平
- DeepMind最新论文:强化学习“足以”达到通用人工智能
- DeepMind进军多伦多,以寻找优秀的人工智能研究人员
- DeepMind巨亏42亿,AI公司为何难有“好下场”?
- 首届剑桥国际青年学术论坛开幕 第四范式携手DeepMind、华为共话AI技术革新
- DeepMind首次在所有57款雅达利游戏上超越人类玩家
- DeepMind研究人员研发出了一种解决机器人控制问题的混合方案
- 谷歌的DeepMind在医学上采用了人工智能的混合路径
- DeepMind联合创始人离职加入谷歌 曾负责健康团队
- Waymo合作DeepMind AI算法开发速度提升1至2倍
- Google和DeepMind正在使用人工智能来预测风电场的能源输出
- 谷歌人工智能DeepMind,高中数学考了个不及格
- 谷歌和DeepMind最新成果:使用人工智能软件预测并提高风能“价值”
- DeepMind一直想做的事,彩云科技做到了!
- 谷歌人工智能公司 DeepMind 介绍阿尔法狗升级版 AlphaZero
- 和 DeepMind 一起考虑如何在 AI 中重现人类的价值观





