创纪录!Fast.ai和DIU在18分钟内完成ImageNet训练 成本仅需40美元
2018-08-16 18:12:18爱云资讯阅读量:499
据报道,来自德累斯顿国际大学(DIU)和Fast.ai的研究人员,在18分钟内用40美元成功训练了ImageNet,准确度达到93%。

(图源:Anette von Kapri)
这是一个新的速度纪录,用于在公共基础设施上训练Imagenet达到这种准确性,并且比其专有TPU Pod群集上的谷歌DAWNBench纪录快40%。
这也意味着一个关键的里程碑——只需40美元,几乎所有人都可以在一个相当大的数据集上训练大规模神经网络。
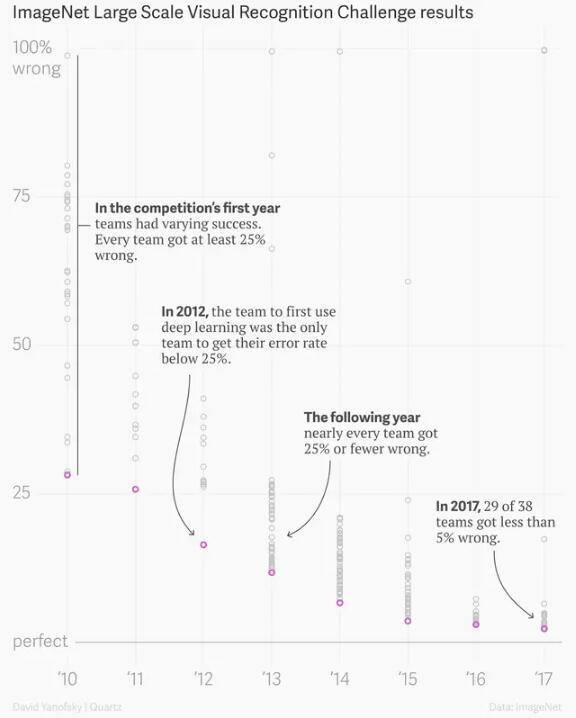
(以往的Imagenet训练结果)
DIU和fast.ai称将发布软件,允许任何人使用该项目中开发的最佳实践轻松地在AWS上训练和监控他们自己的分布式模型。
为了节省时间,团队开发了基础设施,可以轻松地在公共云上托管的机器上运行多个实验——他们使用了16个AWS云实例(每个实例使用8个英伟达V100 GPU)来运行fastai和PyTorch库,以获得最低计算成本。这使得个体研究人员能够以相对较低的成本将他们的系统与广泛使用的计算密集型benchmark进行对比。
许多组织使用复杂的分布式训练系统来进行大型计算,但fast.ai团队却在基础架构中使用最简单的方法实现了目标。“避免像Docker这样的容器技术,或像Horovod这样的分布式计算系统。我们没有使用具有单独的参数服务器、存储阵列、集群管理节点等的复杂集群架构,而只使用具有常规EBS存储卷的单个实例类型。”
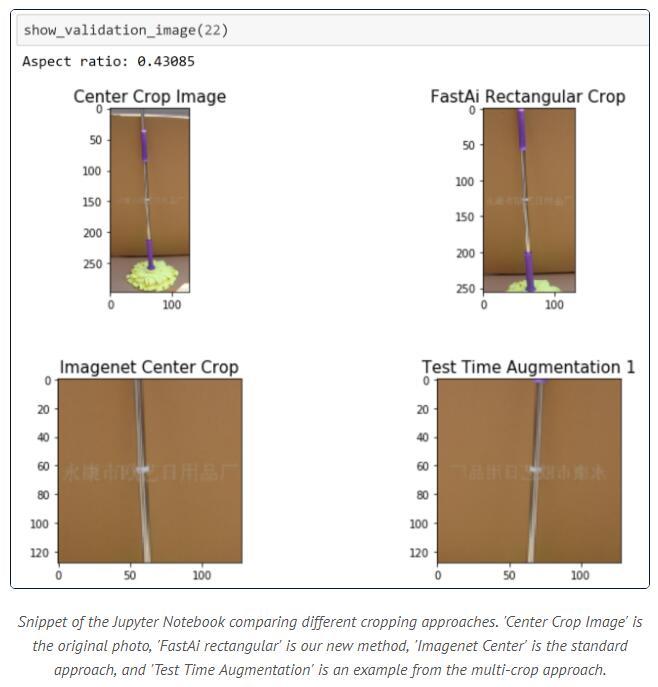
(图源:Fast.ai)
但是,在这种方法中,快速迭代仍然需要面临诸多挑战,比如:
如何在没有大量可持续运行的昂贵实例时,在多台机器上轻松运行多个实验?
如何便捷地利用AWS的EC2 Spot实例(比一般实例便宜70%)?每次使用该实例时都需要从零开始重新设置。
该团队的主要训练方法是:fast.ai用于分类任务的渐进式调整大小和矩形图像验证;英伟达的NCCL库,该库整合了PyTorch的all-reduce分布式模块;腾讯的权重衰减调整方法;谷歌大脑的动态批量大小的一个变体,学习率逐步预热(Goyal等人2018、Leslie Smith 2018)。该团队使用经典的 ResNet-50 架构和具备动量的SGD。
在调度程序上,他们使用了一个名为“nexus-scheduler”的系统来管理机器。Nexus-scheduler由前OpenAI和谷歌员工Yaroslav Butov建造,类似于谷歌的开源系统Kubernetes。
在代码改进方面,设计高效的基础设施的同时,Fast.ai还对传统的训练方法进行了一些巧妙的AI调整,以最大限度地提高训练效率,包括部署一个可以处理可变图像大小的训练系统,它可以对矩形图像进行裁剪和缩放,这样训练便可加速23%,且达 93%的准确度。
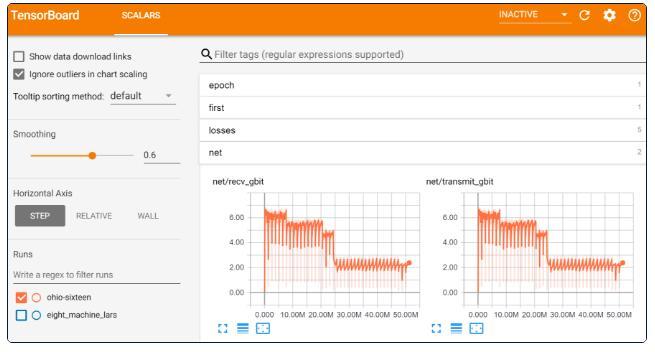
(图源:Fast.ai)
fast.ai在DAWNBench竞赛中取得的主要进展是引入了渐进式图像尺寸调整来进行分类——在训练开始时使用小图像,随着训练的进行逐渐增加图像尺寸。采用这种做法,刚开始的时候模型非常不准确,但它可以很快看到大量图像并取得快速进展。这一新研究还一定程度上改变了批量大小,以更好地利用GPU RAM并避免网络延迟。
此类方法表明,个体或小团队能够轻松地利用容易获得的开源组件构建最佳系统,并以相对较低的成本在公有云上进行计算。这也意味着——更多的科学家可以进入人工智能领域,并进行大型实验来验证他们的方法。
据悉,nexus-scheduler将在8月25日进行首次官方发布。




