小米、高通押宝的下一个AI风口: 改造机器听觉
2018-07-28 19:42:01爱云资讯1437
许多人认为这次的 AI 复兴主要来自两个领域的突破:机器视觉和自然语言处理,特别是在机器视觉比如人/物的体识别、自动驾驶等,都已经取得很好的表现后,科学家们正在攻克另一个领域—机器听觉。
在众多智能语音助手、智能音箱问世的带动下,提到机器听觉很容易直接让人联想到“关键词唤醒”、“自动语音识别”(ASR),例如先喊一声 Hey Siri、Alexa、小爱同学,呼唤这些智能语音助理,接着对其下指令。其实,机器听觉是一门范畴广泛的领域,从声学系统、脑怎么处理声音、到如何将人类的听觉知识封装在算法中,以及如何把算法组合成一个可模拟听觉的机器。
人类的耳朵除了让我们听得更清楚,还能识别声音的方向,知道发声的物体是什么,或者判断处在一个什么样的环境当中。想要让机器能够具备如同人类耳朵的完整功能,现有技术还是很难实现,像是吵杂环境的多人音源分离、远场语音交互等,大家讲远场识音可以达到 3 米、5 米,但要做到 3 米、5 米有一个前提,就是噪音不能太大。正因技术发展还有巨大的提升空间,不少科学家正通过深度学习来改善,并推动行业的发展。
美国著名发明家和科学家 Richard F. Lyon 在 2010 年发表一篇关于机器听觉的重磅“Machine Hearing: An Emerging Field”,指出机器听觉将成为一个新兴领域。文章指出,“我们的计算机目前基本是聋的,它们对于自己存储和处理的声音几乎没有概念”,“近年来,基于文本的图像或视频分析稳健发展,但声音分析则显得滞后.... 与机器视觉的多样化和活跃度相比,机器听觉领域仍处于起步阶段”。
因此,他利用类似机器视觉建模的方法,来打造一个 4 个主要模块的听觉系统结构:1.外围分析器(peripheral analyzer)、2.听觉图像生成器(auditory image generators)、3.特征提取模块(feature extraction module),这个部分在机器视觉领域,就是把图像作为输入,萃取出多尺度的功能、4.可训练的分类器或决策模块(a trainable classifier or decision module),这个阶段会针对应用程序选用适合的机器学习技术,并利用上阶段提取的特征来做决策。
Richard F. Lyon 指出,要打造一个“智能环境”系统是项大工程,可以通过具听觉的机器来实现,把它们安装在汽车、家庭、办公室的计算机,利用这些“听觉前端”实时添加应用程序、执行任务,而且配合“特征提取”、“机器学习”来实现。现在来看,他成功预言了 8 年后今日的样貌,自动驾驶、智能音箱等都选择以“听觉前端”作为交互的入口。
另外,值得一提 Richard F. Lyon 在 80 年代晚期任职于苹果的先进科技部门,当时苹果曾推出 PDA 产品 Apple Newton,其中的手写识别系统 Inkwell 也是由他开发。他也曾在 Google 工作,从事听觉和声音处理的研究工作。
此外,华人科学家汪德亮,同样是机器听觉的大牛,身为俄亥俄州立大学感知与神经动力学实验室主任的他,不仅是机器视觉、听觉交叉学科的专家,更是把深度神经网络引入机器听觉领域的先驱,例如通过机器学习把嘈杂的说话声样本切割为时频单位(time-frequency units),并从这些单位提取出数十种特征来区分语音和其他声音,接着把特征送到深度神经网络中,借此训练出可以分离出语音单元的模型。最后,把这个程序应用在滤波器上,过滤掉所有非语音的单元,只留下分离后的人声。他的最终目的是希望借此改善助听器的品质。
为了把学术研究成果转化为商业化技术,他以联合创始人的身份创办了专攻机器视觉的人工智能初创公司大象声科。就在几周前,大象声科完成了数千万人民币的 Pre-A 轮投资,领投者出现两个重要名字:小米和高通创投,不难猜想这两家公司的战略意义之外,更代表机器听觉的技术将随着硬件巨头的重视可望进入大规模的落地。
机器听觉仍远落后于人类
视觉跟听觉可说是人类最重要的两个感知能力,机器视觉在许多特殊场景下已经超过人类水平。但是为什么机器听觉的发展速度却不如机器视觉快,仍远落后人类?
大象声科 CEO 苗健彰接受 DT 君采访时解释,视觉是一种遮挡的信号,不论是区分图像、物体、人脸,机器可以容易画出物体的边缘,但是,声音是一种叠加的信号,比如一个场景里面有各种的人声、噪声等叠加在一起,信号能量混在一起之后,想要将其分开就很困难。另一个原因是起初深度学习多被应用在语音识别,而更前端的信号处理部分大约是到 2013 年左右才开始引入 AI。前端处理是指在特征提取之前,对原始语音进行处理,如噪声抑制、回声消除、混响抑制等。
不过,近来行业开始涌现了非常大的需求,越来越多智能硬件、机器人需要语音交互。
传统设计思维过时
在今年 4 月锤子坚果 3 手机发布会上,提到内置了“AI 通话智能降噪”,简单说就是通话听清,背后的技术即是来自大象声科。
降噪,不是项新概念,市场上也有许多降噪耳塞,效果如何总是得体验过才知道,既然并非人人都是锤子用户,为了让一般人可以感受,大象声科其实做了一个录音 APP—VOCPLUS,苗健彰表示,现在录音笔多半不具备降噪功能,遇到吵杂环境往往没辙。不过,APP 只是让大众体验的入口,并没有打算将其商业化,公司定位是面对手机业者的 B2B 生意,真正商业化如锤子手机的降噪就是与 APP 同样的技术。而 DT 君实际试用该款 APP,感觉对于消除环境噪音确实有不错的效果,有兴趣的读者可以自行下载试试。
为什么可以做到很好的效果,是提取噪音进而消除吗?答案其实正好相反。
苗健彰指出,传统信号处理的思路是基于噪音特征,比如噪音的 Pattern 是如何、在频率上有什么特性等,接着设计滤波器,把噪音留在滤网上,剩下的声音就留下来,但这么做存在一个问题,就是世界上的噪声种类变化太多,聚合一起有各种排列组合,而且很多的动态噪音没有办法事先预测何时会出现。
所以大象声科换了一个角度来思考问题:既然人类语音的 Pattern 特征其实很明显,那就把在重点放在人的声音上,让机器只关注人的声音,反而更符合人类听觉的基本原理,当我们与朋友在餐厅吃饭,环境很吵,但人类仍然可以轻松对话,就是因为我们把注意力放在对方身上,这也是为什么人类可以简单解决鸡尾酒会的问题。
盲源分离是机器听觉缺失的一块
他进一步解释,“机器其实缺失的听觉功能是盲源分离(BSS,Blind Source Separation),也就是判断发声音源”。
为了解决鸡尾酒会问题,盲源分离成了近年来信号处理领域的一个研究热点,BBS 是指一种不需要任何预先得到资讯,从感测器所量测到的混合信号(mixtures)中,把信号源(sources)抽取、分离出来的方式,目前在语音信号分离、麦克风阵列信号处理、生医讯号如脑电波(EEG)处理等领域都有不少研究。
盲源分离的基本架构如下图,假设有两个声音源 S1、S2,经过了一个未知的混合过程,麦克风收到了两个声源的混合信号 X1、X2,而 a11、a12、a21、a22 代表声源到麦克风的衰减程度,这些系数皆为未知,这也就是称为“盲”的原因,盲源分离的目标就是在信号和混合过程均未知的情况下,分离出各种音源。
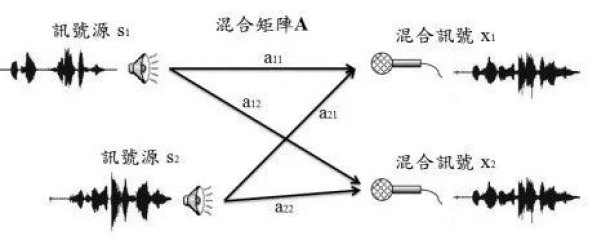
图|盲源分离技术基本概念
Google 双人声分离展现高水准,用视觉辅助听觉
在看不见的情况下,如何把各种各样的音源区分开来,是机器听觉里面的一个挑战,解决这个挑战就有多种思路,“AI 其实提供了一个好的办法”:通过训练让模型能够自主在嘈杂环境底下把声音特征提取出来。
目前来看,大象声科技术强项在分离人声和噪音,解决了手机产品某种程度的鸡尾酒会问题,不过在其他场景仍有待克服,例如智能音箱、电话会议场景等,还需要解决人声跟人声的分类,“多个说话人声分离,甚至还要记录下来,可说是在语音分离上最高级的挑战”。
在多人声分离领域,Google 前阵子展示把两个人对话分离的成果,结合视频的图像来辅助,就是说,在某些复杂且嘈杂的场景下,加入视觉信号分析来做语音分离,是一个趋势。
在今年的 Google IO 大会上展示了一段影片,运动节目里两位来宾情绪激动,说话针锋相对,你一言我一句,声音重叠几乎很难听清楚任何一方在说什么,这种情况常出现在新闻节目、脱口秀、会议上,而 Google 做到将两个人声分离,让用户可以在视频中指定让某人“静音”,只听见另一方的声音。“这在语音分离部分是一个很棒的进展,”,他说。
Google 将此技术称为 Audio-Visual Speech Separation(声音影像的说话分离),最大的特点就在“联合视听模型”,不只是分析人声跟背景噪音,还会分析视频中人物的嘴型与表情。研究团队用了 YouTube 上只有单一讲者的无干扰演讲影片,并将这 10 万个、总时数长达 2,000 小时的影片混入其他演讲影片与背景杂音,以训练多重串流卷积神经网路(Multi-Stream Convolutional Neural Network),进而把各个人物所说的话分离成独立音轨。
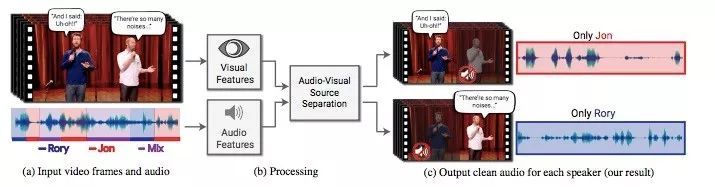
图|谷歌的 Audio-Visual Speech Separation 技术

图|用视频中的嘴型、表情来协助完成语音分离
其他的趋势还有像是机器可以从声音去判断用户的情绪是好是坏,或是机器透过听觉,它可以自己知道身处在一个什么样的环境当中,甚至是当它如果听不清楚的时候,它可能会主动告诉你:“对不起,我听不太清,可以把音乐关小一点吗”,这些都是机器现在不具备的能力,但在未来有机会拥有。有了这些技术功能,智能音箱可能就不会再闹笑话。
分头让人、机器听得更清楚,考量推出机器听觉芯片
目前大象声科主要技术是分离人声与非人声,但也逐步投入多人声分离的研究。而机器听觉的 AI 训练其实跟机器视觉概念类似,同样要提供大量的声音数据,男女、小孩、高低音等都是必要的,同样也需要给予标注(label)数据,例如发声源、发声时间的起始。
另外,人声具有一些特点,例如,发声范围分为 20~2 万赫兹之间、大约 24 个频段。第二、人声是连续地。机器学习的优势就在于,通过大规模数据的堆积,机器能够自己寻找到这些特征,进而判断,例如判断环境是户外或室内、在车内还车外,在车内有开窗或没开窗等,这对于车载交互就很有帮助。
大象声科想要解决的两大问题:一是让“人”听得更清楚,针对手机通讯、云通讯等领域所推出的智能通话降噪解决方案,能够帮助用户过滤掉通话环境中的背景噪音,让对方听得更清晰;另一个是让“机器”听得更清楚,为机器打造一双智能耳朵,赋予其更灵敏的机器听觉。大象声科推出的智能交互解决方案,包含智能降噪、语音唤醒、声纹识别等核心算法,能够为智能音箱、机器人、智能车载等行业带来更自然的语音交互体验。据了解,除锤子的坚果3之外,今年年底前,这两大解决方案也会逐渐在其他手机、智能家居和机器人等产品上进行商业落地。
公司主要采用软件授权的商业模式,将算法软件授权给 OEM 厂家,嵌入在手机的数位讯号处理器(DSP )芯片、麦克风芯片上,或直接把它封装成一个 SDK,提供给语音类软件运营商。不过随着市场需求提升,“有计划将算法和硬件结合起来,与芯片厂家合作定制一个专门、适合我们算法的芯片,一方面可以进一步提高方案的性能,还可以帮助客户降低系统总成本,缩短产品上市时间”,苗健彰说。

图|大象声科 CEO 苗健彰(图片来源:DT 君)
不过由于大象声科的团队背景是以软件见长,而做硬件需要长期积累和大量投入,但他认为,“所谓语音芯片就是听觉芯片,什么样的公司做听觉芯片最合适的?其实是对于机器听觉算法有很强认知的公司,因为知道这个算法需要一个什么样的算力载体”,因此,大象声科也希望找到能够一同合作的伙伴。
当智能手机问世后,世界进入了触屏交互时代,很有潜力的新一代交互方式则落到了语音身上,特别是在双手被占据的场景中,用说的比用摸的更方便,像是开车、工厂、医疗场景,语音交互可能会慢慢存在于未来各种各样的设备中,“我们的技术在于将微弱的人声从嘈杂的背景当中提取出来,无形植入未来任何一台需要“听”的智能设备当中,这种存在其实是观察不到的”,就像是老子《道德经》中所言:大象无形,大音希声。
相关文章
- 小米SU7 Ultra通过中汽研地狱级测试 麒麟电池“性能激进、安全保守”
- 高通CEO安蒙访问小米汽车工厂,出席中国发展高层论坛
- 京东与小米签订智能摄像三年2000万台目标
- 独家供屏小米15 Ultra等旗舰产品,TCL科技中小尺寸业务加速崛起
- 小米对讲机3 畅聊版上市:3W功率+超长待机,商用户外两相宜
- 人形机器人浪潮催生行业“鲇鱼效应”,小鹏/小米/微美全息技术革新跨界博弈
- 小米SU7 Ultra与麒麟电池勇闯新豪华市场 “颠覆者cp”太燃了
- 大米和小米启动RICE AI生态合作计划:赋能100家机构
- 京东发售小米Buds 5 Pro耳机 先人一步为消费者带来高品质耳机体验
- 真我Ultra级黑科技将亮相MWC:小米15 Ultra即视感
- 小米在常熟建设产教融合基地,携手350所院校共同培养智能硬件专业人才
- 国补遇上小米科技年货节,福利满满过大年
- 小米智能摄像机视频通话版正式上市:3.5英寸大屏、一键呼叫视频
- AI辅助孤独症儿童个性化干预,大米和小米最新研究成果在重要期刊发布
- 小米将推出电动SUV汽车YU7,预计2025年六七月上市
- 大米和小米、亚马逊云科技联合创新 为上千万特需儿童带来首套AI解决方案





