寒武纪二代芯片发布在即,提前揭秘如何挑战英伟达!
2019-05-06 15:55:50爱云资讯阅读量:443
「寒武纪在训练领域的低精度整数运算实现了关键性突破,这会是AI 芯片领域的重大消息。长久以来,低精度计算的速度和能耗比优势备受业界关注,但迄今为止尚未有同类产品出现。」
「初创公司要贸然打入云端市场,简直就是自寻死路」。
长久以来,云端的数据中心市场被视为创业公司的禁地,因为英特尔、英伟达、AMD 等巨头林立,竞争太过凶残。
但近年来,云计算势不可挡,云端芯片市场呈现爆发式增长,不乏勇者前来破局。
作为一家发源于中科院计算所、背靠多家「国字辈」资本、估值已经来到30 亿美金的硬核创业公司,寒武纪挑战云端市场的底气十足。
2018 年5 月,寒武纪发布首颗云端AI 芯片,并对外透露获得中国前三大服务器浪潮、联想、曙光的订单。据机器之心了解,滴滴、海康威视也已经成为寒武纪的客户。
与此同时,寒武纪成数亿美元B 轮融资。据机器之心了解,目前寒武纪的估值约为30 亿美元,与今年2 月完成6 亿美元融资后成为「全球最具价值的AI 芯片公司」的地平线不相上下。
一年后,寒武纪二代芯片已经箭在弦上,这颗积蓄了中科院计算所研发实力四年之久的二代或将为行业带来不小震荡。
机器之心独家获悉,寒武纪二代云端芯片或将于本月公布,同时我们采访到寒武纪技术研发相关知情人士、寒武纪云端芯片客户等多方信源,提前揭秘关于该颗芯片的细节亮点和核心技术。
这回有了中文名

据机器之心了解,寒武纪二代云端AI 芯片代号为「MLU270」,延续上一代芯片「MLU170」的MLU(Machine Learning Unit)系列。今年初,寒武纪已经为旗下芯片注册两大中文商标名,分别是「思元」、「玄思」。综上,寒武纪二代云端AI 芯片中文名为「思元270」。
在今年的新品议程表上,虽然还名列有其他芯片,但「思元270」及其板卡将会是重头戏。这也表明寒武纪将从终端向华为等品牌商授权IP 的模式,转向主打云端市场的芯片方案提供商。
在芯片架构方面,寒武纪二代芯片将从上一代的「MLUv01」升级为「MLUv02」。考虑到视频数据正呈现爆炸性增长,成为数据中心的任务主流,寒武纪在「思元270」里内建视频解码单元,瞄准海量的视频处理市场专门配置。
据机器之心了解,寒武纪「思元270」在今年年初研制成功,制程工艺方面明显抛弃了此前终端市场的激进打法,选择仍然沿用台积电16nm 工艺,定位于「专注云端训练计算」。
对比两大巨头的主流云端产品线,英伟达去年9 月发布并已发货的Tesla T4 采用14nm 工艺,AMD 去年11 月发布的Radeon Instinct MI60 和MI50 采用7nm 工艺,寒武纪这次似乎希望单纯依靠技术路线取胜,不再如去年对于7nm 工艺寄予厚望。
「让英伟达难受」
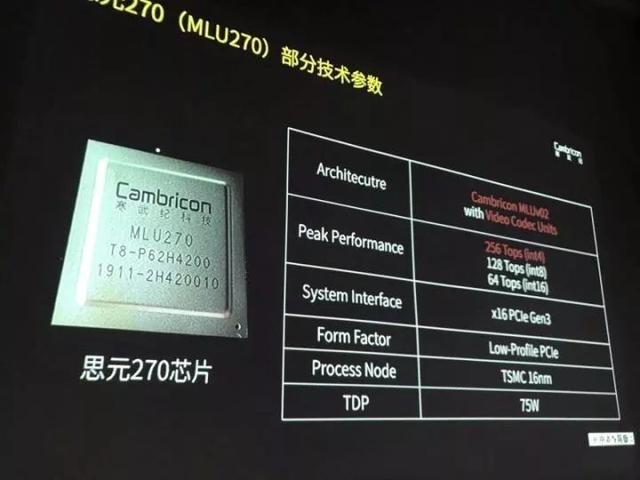
在芯片性能方面,「思元270」的性能参数有意向业界标杆英伟达Tesla T4 看齐。
据机器之心目前了解到的情况来看,「思元270」可支持INT16/INT8/INT4 等多种定点精度计算,INT16 的峰值性能为64Tops(64 万亿次运算),INT8 为128Tops,INT4 为256Tops。
对比Tesla T4,FP16 的峰值性能为65 Tops,INT8 为130 Tops,INT4 为260 Tops。
功耗方面,「思元270」功耗为75w,与Tesla T4 持平。
但值得注意的是,这些「理论峰值」不过是纸面规格,真正实测水平相比理论峰值通常有一定缩水。据某大体量计算数据中心负责人,同时也是阿里云早期核心技术研发人员李立表示,「T4 在实测过程中,75w 功耗维持不了多久就降一半频率。」
据该负责人介绍,他在几个月前已经拿到「思元270」的具体规格和特性,「对比而言,第一代MLU100 是试水,第二代270 就聚焦多了,威力非常大,NV 后面会很难受。」
与此同时,该负责人还指出,「寒武纪的方案在某些领域可能不会特别好使,尚待观察。」
核心技术解密
在「思元270」的性能参数展示上,可以看到寒武纪有意强调其整数计算性能方面的优势。据接近寒武纪技术研发的知情人士王一表示,正是寒武纪在训练领域的低精度整数运算实现了关键性突破。「那将会是AI 芯片领域的重大消息,因为低精度计算的速度和能耗比优势一直受到业界密切关注,但迄今为止尚未有同类产品出现。」
这里需要引入一对运算表示法的概念,整数运算(定点运算)与浮点运算。
它们是计算机计算中最为常用的两种运算表示法,顾名思义,其差异就体现在整数和浮点上,加减乘除运算都是一样的。
整数表示法,即所有位都表示各位数字,小数点固定;浮点表示法,则分成两部分,阶码和尾数,尾数就是数字部分,阶码表示乘幂的大小,也就是小数点位置。所以浮点数在做运算的时候,除了对尾数做加减乘除,还要处理小数点位置。
基于两种不同的运算表示法规则,导致面对同样长度的整数和浮点运算,后者计算模式更为复杂,需要消耗更多的资源去处理,并且二者功耗差距通常是数量级的。简单来说,就是浮点运算占用的芯片面积和功耗相比于整数运算器都要大很多倍。
但浮点运算又有其不可取代性。首先,定点表示法运算虽然直观,但是固定的小数点位置决定了固定位数的整数部分和小数部分,不利于同时表达特别大的数或者特别小的数,可能「溢出」。
而浮点的精度虽然没有定点大,但是浮点运算的小数点位置可以移动,运算时不用考虑溢出,所以科学计算法一般都使用浮点。所谓「溢出」,指超出某种数据格式的表示范围。
此外,具体到使用GPU 做训练,业界通常更倾向于浮点运算单元,主要是因为在有监督学习的BP 算法中,只有浮点运算才能记录和捕捉到训练时很小的增量。由于训练的部分模块对精度要求比较高,所以通常必须是高精度的浮点运算,比如FP32 才能搞定,FP16 都难。
综上,虽然浮点运算相比定点运算在功耗、计算速度、性价比等方面都不占优势,但截止目前,浮点计算在云端的训练场景中仍具有不可替代的特性,并且以高精度运算为主。
那么,如何在不增加芯片面积和功耗的前提下,如何大幅提升芯片做训练的运算能力就成为云端训练芯片的主要研课题之一。
参考计算过程相对简单的推断计算思路,目前该领域的AI 芯片多采用集成大量整数运算器或低精度浮点运算器。
面对计算过程更为复杂的训练计算,业界一直在尝试是否可能用性价比更高的定点运算器实现。「但这个问题在学术界也还没有普适的解决方案。」王一说道。
李立表达了类似的观点,目前大家的研究热点之一,就在于如何全部的定点单元(比如INT8)代替浮点单元,或者以主要的定点单元配合少量的高精度浮点计算单元(比如FP32)做更多的训练任务,目的是达到定点计算的快速度,同时实现接近高精度浮点计算的精度。
谈到目前该方向的研究成果和代表论文,李立表示,行业相关的研究文章已经有一些,不过都不具有普适性。
王一进一步向机器之心透露了关于实现低精度运算的「关键心法」,要做好低精度训练,就要找到一个好的数据表示方法,既能表达最后大的数,又能让0 附近的小量能够更好地表达,因此这个数据表示可能需要有自适应性,能随着训练的过程调整。
他还补充,「低精度训练确实未必要是浮点数,只要能把数域表达好,0 附近的小量表达好,什么样的数据表示都可以。」
综上,寒武纪在大幅度提升训练阶段的计算功耗比方面,很有可能采用的是以整数为主的低精度运算,这在目前已公布的AI 芯片项目中属于首创。
实际上,寒武纪在计算机计算领域的开创精神和技术积淀由来已久。早在2014 年—2016 年期间,寒武纪创始人兼CEO 陈天石、陈云霁两兄弟的研究就基本奠定了神经网络芯片的经典设计思路,也就是现在常谈到的AI 芯片架构。
当时他俩的「DianNao 系列」论文横扫体系结构学术圈: Diannao(电脑)是ASPLOS'14 最佳论文(亚洲第一次),DaDiannao(大电脑)是MICRO'14 最佳论文(美国以外国家的第一次)……

而在大洋彼岸,美国两家风头正劲的AI 芯片公司Graphcore、GTI(Gyrfalcon Technology, Inc.)正是沿用了DianNao 系列论文的基本思路,采用大量堆叠的简单计算单元以实现复杂的云端计算。(机器之心曾进行过相关报道,《一款芯片训练推理全搞,Hinton 为其背书,Graphcore 完成2 亿美元融资》、《30 年前的「CNN 梦」在这颗芯片落地,能效比高出Tesla10 倍| CES 直击》)
此外,要切数据中心市场的蛋糕,一套完备成熟的软件生态也是其核心竞争力的重要体现。英伟达之所以能够在云端训练领域成为绝对主流,其CUDA 软件生态的基础功不可没。
据机器之心了解,寒武纪从2016 年起逐步推出了寒武纪NeuWare 软件工具链,该平台终端和云端产品均支持,可以实现对TensorFlow、Caffe 和MXnet 的API 兼容,同时提供寒武纪专门的高性库,可以方便地进行智能应用的开发,迁移和调优。
到今年,该软件工具链进行了哪些层面的迭代值得关注,比如是否可兼容更为流行的框架Pytorch 等。
「云芯」之争一触即发
尽管前述了寒武纪的种种硬核技术护体、大资本和客户加持,但想要真正在数据中心市场扎下根,以实现陈天石去年在发布会上谈到的目标:到2020 年底,力争占据中国高性能智能芯片市场的30% 份额,仍然面临着异常残酷的市场竞争。
整体上,英特尔在数据中心服务器芯片市场仍然牢牢占据着的95% 以上份额。
而随着深度学习计算和人工智能技术逐步兴起的云端训练市场,同样被巨头绝对垄断。目前90% 以上的云端加速采用英伟达GPU,AMD、FPGA 占据非常小的份额,剩余市场还在被国内外芯片创业公司不断瓜分。
据机器之心了解,近期还有一家国内知名AI 算法公司将要入局云端推理芯片市场。据德勤最新出炉的报道显示,到2022 年,全球人工智能训练市场的规模将达到约170 亿美元,云端推理芯片市场的规模将达到70 亿美元。
可以预见,2019 年,AI 芯片之争将从端燃及云上,云端的大体量、高增速市场势必迎来更多强劲玩家。
相关文章
- 寒武纪积极助力人工智能的实际应用落地
- 寒武纪AI训练卡MLU370-X8荣获2023年度卓越创新产品奖
- 寒武纪统一的平台级基础系统软件打破开发壁垒
- 寒武纪通用型智能芯片:技术壁垒高但应用面广
- 寒武纪:通用型智能芯片在性能和功耗上存在优势
- 寒武纪:具备云、边、端芯片产品和生态开发协同优势
- 寒武纪2022年业绩说明会:研发成果显著,核心技术持续突破,知识产权积累创新高
- 寒武纪入选星辰20:2023中国AI算力层创新企业
- 寒武纪灵活多样产品满足多元市场需求
- 寒武纪:通用型智能芯片对人工智能具备较好普适性
- 寒武纪云边端产品线日益完善 商业场景逐步落地
- 寒武纪行歌获博世创投投资 合作双赢加速发展
- 寒武纪思元370入选2022世界人工智能大会SAIL奖TOP30
- 寒武纪2022年半年报:营收增长24.6% 商业客户批量出货
- 提前布局新兴场景 寒武纪抢占发展先机
- 宏观市场双推下 寒武纪拟定增募资加码高端智能芯片





