旷视发布全球最大的物体检测数据集 构建高质量AI训练资源库
2019-04-20 13:35:54爱云资讯908
现阶段,缺乏高质量的数据集已经成为制约人工智能领域发展的瓶颈之一,如何构建人工智能数据集已成为各国政府和产业界关注的焦点。其中,美国就将构建行业资源数据集定位为产业界不可能解决需政府层面推动的难题。英国也将提高数据获取性和行业数据访问的便利性列为未来提升英国人工智能能力的首要任务。
我国亦将缺少有效的训练资源库列为影响人工智能发展的痛点问题之一,工信部此前发布的《促进新一代人工智能产业发展三年行动计划》更是明确提出,支持建设面向语音识别、视觉识别、自然语言处理等基础领域及工业、医疗、金融、交通等行业领域的高质量人工智能训练资源库、标准测试数据集并推动共享。
在此背景下,旷视研究院在日前举办的“智源学者计划启动暨联合实验室发布会”上,发布了全球最大的物体检测数据集——旷视Objects365。

图:旷视首席科学家兼研究院院长孙剑介绍旷视Objects365
据旷视首席科学家兼研究院院长孙剑介绍,旷视Objects365是新一代通用物体检测数据集,具有规模大、质量高、泛化能力强的特点。在规模方面,旷视Objects365定义了生活中常见的365个类别,第一批将开放63万张图像,拥有高达1000万的标注框(每张图像的平均标注框为 15.8个),而这个数量级分别是目前全球最权威的物体检测数据集——MS COCO的5倍和11倍。
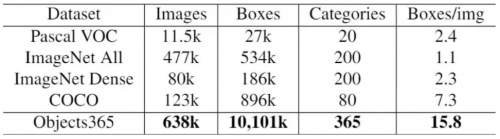
图:旷视Objects365与大型经典数据集的基本对比
同时,在研究过程中,由于算法优化的上限严重依赖于基准数据集的质量,因此旷视研究院在打造旷视Objects365时设计了一套标注流程,通过标注员严格的资质审核,以及对目标物体严谨、科学的分类保证每一张图片的标注质量。
此外,作为一个优秀的预训练数据集,旷视Objects365预训练模型在使用过程中,可以轻松超越现有算法的精度,显著加速收敛过程,表现出极强的泛化能力。在执行COCO、VOO Det、CityPersons等检测任务时,在VOC Seg和ADE等分割任务上均有显著提升。
相较于算法,高质量的数据能对深度学习带来更大的提升,对计算机视觉模型的训练产生更大影响,因而数据共享是集结全行业之力推动计算机视觉发展的关键之举。基于此,旷视Objects365 数据集的发布,将推动通用物体检测技术的发展,为中国人工智能计算机视觉技术的发展与应用注入新活力和新动力。而且,无论从数据规模再到标注质量,旷视Objects365皆为计算机视觉基础技术通用物体检测树立了新的里程碑。
在未来,旷视还将进一步推动数据集的构建。据孙剑透露:“虽然旷视Objects365已是目前世界上最大的物体检测数据集,但我们的目标是在未来3年内将这个数据集从现在的60万,扩大到200万图,超过2000多万框,进一步扩大这个数据集。”
相关文章
- 北安协走访旷视,见证AI驱动下的安防创新布局
- 接入DeepSeek,旷视AIS算法生产平台5.0版全新发布!
- 旷视中标!AI+驱动北京城市感知管理跃升
- 以大模型驱动 旷视与中国移动共创多元场景价值
- 阿里云、旷视等超60个安全类SDK拥抱鸿蒙,助力开发者全方位保障应用安全合规
- 致远互联与旷视科技达成战略合作 筑牢企业协同运营安全防线
- 始于算法,终于生态!看旷视企业业务的新玩儿法
- 旷视科技签约蓝湖MasterGo,开启国产设计软件“共创”新时代
- NeurIPS 2021 | 旷视提出:空间集成 ——一种新颖的模型平滑机制
- 旷视推出边缘侧产品鸿图、魔方,为建筑智慧升级提供“过硬保障”
- 沉浸式环游AI世界 旷视智·世界校园体验官福利满满
- 旷视科技科创板首发上市获通过 拟募资60.18亿元
- 旷视首席科学家:AI 技术十年跃迁的三个核心问题
- 电瓶车起火事故频发 旷视将免费开源检测算法助力守护小区平安
- 旷视与金隅集团签署战略合作协议,携手打造AIoT工程样板
- 凭借行业领先动态鲁棒性,旷视MegBot-S800斩获LT峰会创新产品奖





