视语科技王金桥团队荣获2018全球AI挑战赛冠军,演绎算法与工程的完美结合
2018-12-24 17:36:55AI云资讯1044

2018年12月20日,“AIChallenger2018全球AI挑战赛”年度总决赛圆满落幕,视语科技创始人兼董事长、中科院自动化所研究员王金桥带领团队获得“无人驾驶视觉感知”赛道冠军!以高于第二名四倍的成绩遥遥领先,并得到“达到世界级领先水平”的极高评价。美团点评无人配送视觉感知技术负责人陈华清赞叹道,“太强了,这样的成绩让人惊喜”。

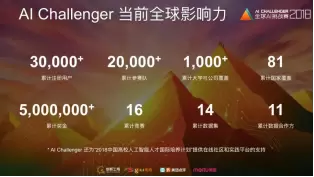
“AI Challenger全球AI挑战赛”是国内规模最大的、最关注前沿科研与产业实践相结合的非商业化数据集和竞赛平台。本次大赛于2018年8月29日正式启动,吸引了来自81个国家的1100所高校和990家公司的上万支团队参赛,而王金桥团队就是这万里挑一的佼佼者,展示了在视觉识别领域的领先水平。
2018年是人工智能落地的元年,人工智能实际上是一个将数学、算法理论和工程实践紧密结合的领域。算法只有深度与场景融合,实现产学研一体化,解决行业痛点才能真正实现人工智能的价值。视语团队从算法设计、数据处理、工程优化等几个方面介绍如何将视觉识别算法与应用场景进行深度融合,打造有温度、有价值的AI技术。
1.算法是核心
科研中算法的比拼相当于华山论剑,讲究的是科学性、原创性和实验效果。而在工程落地中,更注重算法与场景适配性、稳定性、精度和速度。经常需要针对特定场景下的特定任务,定制整体算法框架,对每一个算法细节进行精细打磨,并合理利用算法和场景结合的边界,从而提出一些创新型的思路。
以无人驾驶视觉感知为例,需要同时解决“目标检测”和“可行驶区域分割”两个子问题。而由于计算资源有限,为了追求精度和速度的平衡,算法设计需要考虑多任务学习框架。


接下来,需要深入剖析子问题的难点,对算法各个模块进行定制化设计。比如对于目标检测来说,该应用场景需要尽量提高各类目标的检出率,所以小目标检测就成为难点,这里的小目标包括交通标志、交通灯、远处的行人和车辆等。对于可行驶区域分割来说,主要难点在于类间定义模糊,即可直接行驶区域和可间接行驶区域之间有时候界限并不是很清晰。本质上可行驶区域就是道路,但是对于双车道来说另一侧车道就是背景了,所以对于可行驶区域分割来说需要算法具有较强的上下文语义感知能力。
基于上述分析,视语团队提出了一种多任务耦合神经网络的解决方案。具体来说,针对速度方面的要求,从三方面进行优化:第一是多任务学习,一个网络同时处理检测和分割两个任务,使它们尽可能多地共享耦合特征计算;第二是设计轻量级的多尺度耦合网络,降低网络本身的计算量,并进一步裁剪预测头;第三是代码优化,包括batch输入、GPU解码、CPU解码+流水处理等。考虑到解码部分耗时较高,团队将图片解码放到GPU上进行实现,以充分利用GPU的并发性来加速解码;同时形成前处理(CPU)、网络前向(GPU)以及后处理(CPU)的流水式操作,用网络前向的时间掩盖CPU读图和写图的时间。
为了有效提升模型的精度,团队采用了三种有效的策略。第一是使用特征金字塔,主要是改善小目标检测精度;第二是使用空间金字塔池化ASPP模块,主要是增强网络的上下文语义感知能力;第三是引入数据蒸馏,进一步优化轻量级网络的性能。基于上述策略,团队提出了一个面向多任务的耦合神经网络(MCoupleNet),能够同时处理目标检测和可行驶区域分割两个任务。整个网络包含了5个模块:基础网络、ASPP、特征金字塔、检测分支以及分割分支。基础网络部分是团队自主设计的轻量级网络Inception-56,基础网络和特征金字塔之间通过ASPP模块连接在一起,ASPP模块由一系列采用不同膨胀系数的卷积层组合,可以同时捕捉多种上下文信息,并加入深层监督来引导整个学习过程。
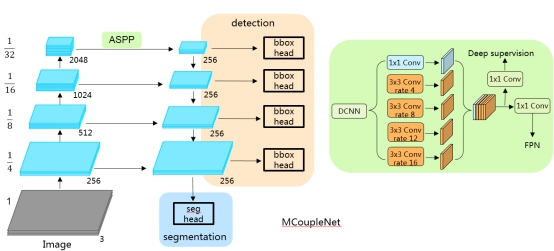
特征金字塔的设计可以参考团队在ACCV16发表的工作以及Facebook发表于CVPR17的论文。ACCV16的论文主要用来处理监控场景下不同尺度的行人,通过自适应的上采样模块在不同分辨率的特征图上处理不同尺度的行人目标,Facebook CVPR17的论文进一步引入lateral connections并且推广到通用目标检测上,是目前比较成熟的解决目标多尺度的算法。团队在此基础上加入基本的检测分支和分割分支,从而组成一个多任务的学习框架。
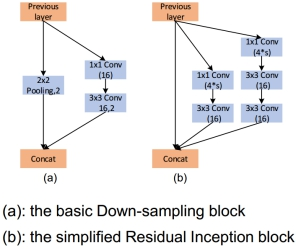
轻量级耦合网络主要包含两个模块:基本的下采样模块和简化版的残差Inception模块。基本的下采样模块主要应用在网络的早期,用来快速下采样从而减少计算量,同时改善特征表达能力。简化版的残差Inception模块使用了更少的通道数,在每次下采样的时候通过两个1x1的维度扩充卷积、动态的增加一倍的通道数,用来补偿空间分辨率损失。不同于MobileNet和ShuffleNet,该轻量级网络中所有的卷积都是常规卷积,没有group卷积和depthwise卷积,因此能够适用于所有的平台,并且有助于减少MAC(memoryaccess cost),同时所有的卷积后边紧跟着BN和ReLu,最终网络的计算量只有143M。
除了基础网络之外,对新加入的特征金字塔也需要进一步的调整。尤其是高分辨率输入下,算法的各个部分都有可能成为计算瓶颈。以720P输入为例,特征金字塔部分的通道数默认为256,网络上采样的倍率为4,对于特征金字塔中的一个3x3的卷积层,其计算量#FLOPS=3*3*256*256*184*320=34.7G,非常大!所以特征金字塔部分也需要进行裁剪,并且对输入分辨率和上采样倍率之间也需要进行权衡。
最终,团队凭借上述原创的算法设计方案,在2018全球AI挑战赛无人驾驶视觉感知赛道中取得了性能的遥遥领先。
2.数据是血液
众所周知,没有人工就没有智能,当今深度学习算法的成功依赖于大规模精确标注的训练数据。因此,数据的采集和标注也是算法落地的关键环节。为了提高算法开发的效率,大多数公司都会为算法团队配备一个数据团队或者通过外包公司,专职负责数据的采集、筛选、标注工具或者平台的开发、标注、数据统计与管理等工作。
不同于学术研究中直接使用公开数据集的方式,实际应用中,经常需要针对特定任务特定场景进行大量数据采集。然后在数据标签类别大于1万的时候,数据标注的成本成级数级增长,而且对于某些稀缺数据,难以收集样本。因此基于小样本的模型训练或者采用弱监督来利用大量未标注的样本成为未来发展的主流,还可以借助3D虚拟合成和GAN生成的方式来生成训练数据。此外,为了充分高效地利用数据,跨任务的数据复用和基于算法的数据清洗也是提升算法开发效率的有效策略。最后,算法在上线使用过程中,源源不断产生的数据也可以反过来进一步推动算法性能的提升。
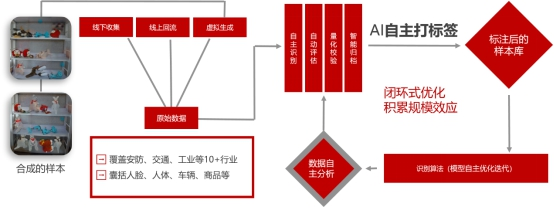
视语团队针对检测、分割、分类等不同计算机视觉任务,利用多年来在安防、交通、零售、工业检测等10多个行业的人脸、人体、车辆、商品、布匹等多类型海量数据积累,推出了国内第一个基于主动学习的半自动化标注平台。以海量数据学习为基础,集主动识别、自动评估、量化校验、智能归档为一体,形成样本自主标注、模型自主更新、数据自主分析的闭环系统。其中的虚拟生成环节,可以实现数据样本自动旋转、自动形变、自动渲染,目标前景背景自动分割、自动标签映射。最终实现100%的标注准确率,有效替代95%的人力标注成本,形成数据采集+算法研发的深度结合,打造闭环系统开发流程。
3.工程是关键
产品和系统的最终部署上线,离不开精心的工程优化。工程化能够在优秀的算法与成熟的应用之间架起一座桥梁,使得算法能够充分发挥其性能优势,使得应用能够达到最优效果。典型的工程优化流程包含硬件的选择、面向特定硬件平台的网络设计、算法底层优化、系统资源合理调度等内容,是需要在算法方案设计之初就综合软硬件特性、应用场景特点综合考虑的问题。
算法的部署首先需要依托特定的硬件载体,其中不同的硬件平台有着截然不同的特性,如何根据应用场景的特点、硬件平台的特性、以及对应的成本/功耗等问题选择合理的硬件平台是算法是否能够成功应用的基础条件。例如Nvidia的大型GPU(如1080Ti、Titan V100等)具有大显存、高计算力等优势的同时也会伴随着高功耗、大空间、高成本等劣势,其通常部署在云端,以云服务的形式提供线上服务支撑,在满足我们日常的网络模型训练任务的同时,可以在后台承担高并发、高复杂度等对算力要求较高的任务,如面向监控市场的视频结构化任务,通常需要并发处理几十路甚至上百路的实时视频流,或者需要20倍速以上处理本地视频文件,这就需要GPU强大算力的支撑。而对于面向移动端(手机、智能前端分析设备、智能摄像头)的应用,则需要更多的考虑受限的算力以及对功耗的控制,因此更倾向于选择低功耗的诸如Arm、FPGA、DSP或者面向神经网络加速的ASIC芯片进行对于场景的适配,如海思的Hi3559A芯片,在集成了神经网络加速引擎NNIE的同时,还具备丰富的外围接口支持(视频编解码、ISP等),是作为智能前端设备主芯片良好选择。而诸如MediaTek3288/3399等Arm芯片虽然算力一般,但却具有低功耗、低成本的优势,在诸如人脸抓拍等特定领域也有着不小的优势。因此,拥有明确、清晰的应用场景定位和需求分析,选择合理的硬件平台,是算法产品化、实用化的首要条件。
在确定的硬件平台上,如何充分发挥受限的计算资源又会反推算法设计时进行相应的考虑和适配。如面向CPU(x86、ARM)平台时,通常需要更多的采用Depthwise,或者Shuffle Layer等对CPU运算友好的结构进行网络结构设计,而面向FPGA平台时,需要考虑网络结构的可稀疏化、同时网络设计的同时应当考虑低bit量化后的精度保持问题,同时在网络结构的设计中更多的考虑采用可以进行特定数学方法优化实现的(winograd)特殊卷积层,如大小为3*3的卷积核等。而面向特定的硬件计算平台(如Hi3559A)时,模型对量化、常见层的选择则会有更加差异化的要求。
在网络结构确定、算法框架确定的基础上,还需要在算法实现上充分考虑不同硬件平台特性进行特定优化。如Nvidia GPU平台下可以优先考虑TensorRT推理引擎,另外应当尽量选择CUDA编程对算法进行实现,减少CPU-GPU数据交互以提高GPU利用率,调整合适的batch size大小以充分调用GPU计算资源等。而面向CPU平台下的实现通常应当更多的考虑SIMD指令集的优势,如在Intel x86架构下应当充分利用SSE、AVX指令集对算法进行深度优化,或者考虑采用OpenVino计算库对算法进行移植,而面向ARM架构,NEON指令集加速、线程池、内存池技术的应用通常有着巨大的收益。
除此之外,算法的外围开发工作也应当以“算法算力资源优先”的原则进行设计,如在GPU平台下,可以充分利用CPU的闲置资源进行视频编解码操作、设计多级流水结构以降低系统整体耗时等操作也有着很好的实践效果。而针对ARM平台下常见的大小核架构,如何充分调度多核协同工作,设计大核卷积、小核管理等策略也同样十分重要。

无人驾驶视觉感知赛题追求模型的轻量与快速。视语团队在比赛过程中,针对GPU平台在设计了轻量级的神经耦合网络结构、提出了端对端多任务学习框架的同时,就采用了包括算子GPU移植、多作业模块流水化处理、CPU-GPU并发处理等大量的工程优化策略来对算法的实现过程进行改进,使得算法最终在原始算法版本上有超过200%的效率提升,算法在GPU上的部署,正是通过视语团队经过多年积累,所打造的跨平台神经网络高性能推理引擎MNIE进行的。
该平台紧跟边缘计算的发展趋势,在网络设计、模型部署时能够自适应的适配不同硬件平台,追求计算的高性能和低功耗之间的动态平衡。目前MNIE推理引擎支持神经网络模型在GPU、Arm、x86-CPU、FPGA、ASIC专用芯片上的优化部署,以充分发挥对应平台的特性,同时能够很方便的接入一些具有神经网络加速功能的特定设备,如Hi3559a、movidus等。同时该推理引擎在外围提供一套完整的工程化算法部署策略,在诸如视频编解码、片上芯片资源调度方面具有良好的优化。采用该引擎部署的人脸检测算法,能够在诸如树莓派等低端ARM设备上实现720P的实时人脸检测。
视语科技的参赛队员均来自于中科院自动化所模式识别国家重点实验室。中科院自动化所在人工智能领域排名全球第七,国内第一,而模式识别国家重点实验室是国内人工智能领域的国家级实验室。团队具有20余年的核心技术积累,并在公安、交通、娱乐、零售和工业等各个垂直领域进行了广泛的技术验证和应用,已经具有上百家上市公司、政府和行业客户,包括杰创、联想、京东、华为、影谱、京东方等多家上市公司,拥有坚实的数据、理论、算法和用户基础。团队与科学院创立了中科视语科技有限公司,针对智慧交通、智能商业和智能制造三大领域探索算法和场景的深度整合,通过全平台神经网络计算引擎和视觉智能计算操作系统提供面向场景的全行业解决方案和一体化软硬件产品服务。目前已经推出了交通产品包括车纹识别一体机、重型货车监控系统、视觉交通信息调查设备;智慧纺织产品包括:智能视觉验布机、智能理管机等。通过软硬一体化设备的销售和持续的智能系统平台服务,整合上下游资源,积累用户资源,逐步布局产业,深入挖掘细分行业场景,占领大众市场,打造有价值、有温度的人工智能。








