麒麟芯御用超级新AI IP曝光:性能翻4倍!
2018-09-29 10:32:31爱云资讯阅读量:739

Cadence是一家 AI行业 参与者,他们的Tensilica IP产品仍然非常引人注目,并且出现在流行的SoC中,如HiSilicon的Kirin阵容或MediaTek的芯片组。随着业界试图将基于云的AI推理转移到边缘端设备本身,设备内神经网络推理的市场正在爆炸式增长,以实现更低的功率和更低的延迟。
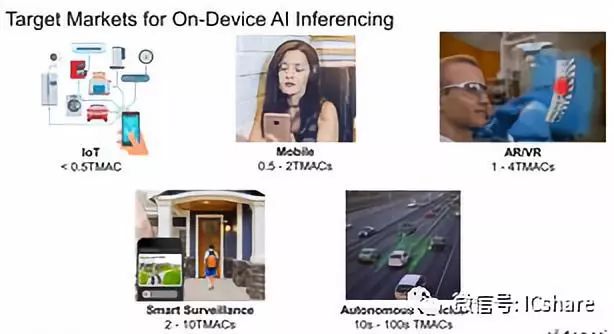

Cadence于本周展示了从 物联网 、移动、AR/VR到智能监控和汽车应用等各个领域的广泛性能需求,并公布了更多有望加速边缘端神经网络推理的产品,并宣布推出一种新的专用“AI”IP,专注于满足各种各样需求的性能和扩展,扩展比以前更高,性能有望达到100 TMACs(万亿矩阵积累操作)。
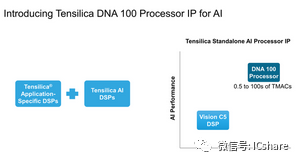
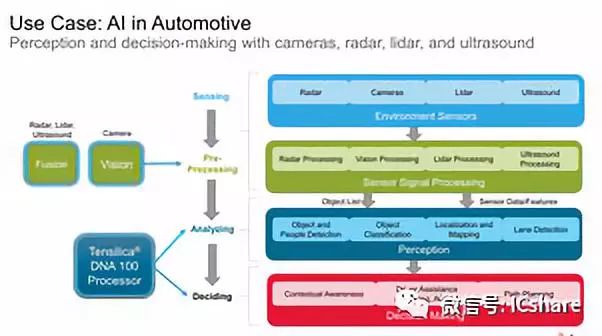
Cadence表示,在汽车动力等应用中将拥有大量传感器,包括 摄像头 ,激光雷达和超声波等,对于推理性能的需求非常急迫。 标准DSP将处理信号处理的主要任务,但实际上对数据有意义的任务将被移交给神经网络加速器,例如处理感知和决策制定任务的DNA 100。
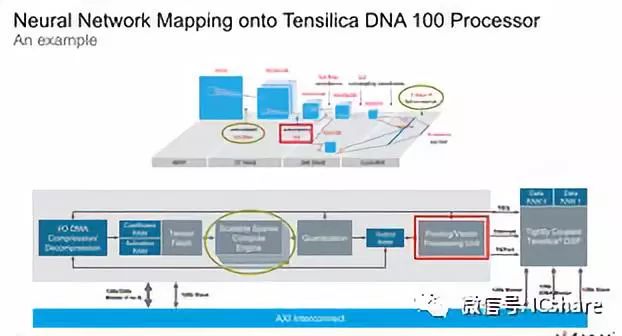
Cadence宣称与具有类似尺寸的MAC引擎的竞争解决方案相比,DNA 100具有高达4.7倍的性能优势。Cadence通过它的稀疏计算架构实现了这一点,这意味着它只计算非零激活和权重,并实现了比竞争对手更高的硬件MAC利用率。
“神经网络的特点是固有的权重和激活的稀疏性,这会导致其他处理器中的MAC通过加载和乘零而不必要地消耗性能。DNA 100处理器的专用硬件计算引擎消除了这两个问题,允许利用这种稀疏性来提高效率和减少计算量。神经网络的再训练有助于增加网络的稀疏性,并通过DNA 100处理器的稀疏计算引擎实现最大性能。”
在架构方面, DNA 100与其他推理加速器看起来很相似,其最重要的处理能力在于Cadence称之为“可扩展稀疏计算引擎”的MAC引擎,它们处理卷积阶段以及完全连接的分类层的任务。
MACs是本地的8位整数,能够在全吞吐量的量化模型上操作,但它也提供了半速率的16位整数和四分之一吞吐量的16位浮点操作。单个MAC引擎/稀疏计算引擎在256/512/1024 MAC中都是可伸缩的,之后IP可以通过添加更多引擎进行扩展,最多可达4个。这意味着最大配置的单个DNA 100硬件块最多包含4096个MAC。
Cadence仍然非常清楚,有些应用场景或神经网络模型可能无法由固定函数IP处理,并且仍然提供了将DNA 100与现有DSP IP耦合的可能性。这两种产品紧密耦合,DSP可以有效地处理更多特殊的的NN层,将内核传递回DNA 100,从而使解决方案具有未来的可扩展性,并可扩展到客户希望的定制层。
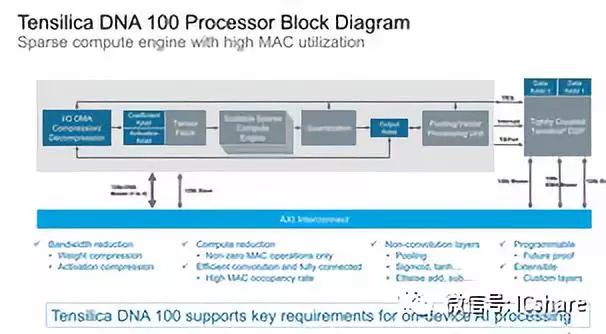
带宽是神经网络推理硬件中的一个关键瓶颈,因此为了获得最佳性能并且不受平台限制,压缩是必不可少的。DNA 100除了通过压缩权重和激活来提供带宽减少功能,在原始带宽方面,IP还提供1到4个AXI 128或256位接口的非常宽的接口选项,这意味着在最宽的配置中最高可达1024位总线宽度。
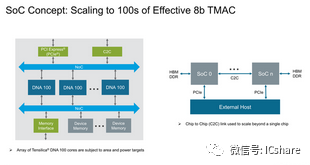
要将IP扩展到4096MACs以上,只需将多个硬件块并排放置到SoC上,就可以大大提高理论计算能力。软件在这里扮演了一个关键角色,因为它能够在不同的块之间正确地分配工作负载。Cadence解释说,这种方式也可以用来加速单个内核/推理,此外他们还设想通过芯片到芯片通信实现可能的多芯片扩展。

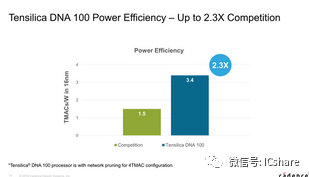
就DNA 100的性能而言,Cadence再次强调其架构的实际性能明显高于具有相同数量MAC的等效竞争架构。这里的“有效TMACs”是一个奇怪的指标,以雷锋网获取的信息来看,根据权重和激活数据是否经过编译器和培训的修剪,有效性能也在2倍到3倍之间浮动。

Cadence展示了ResNet50的性能,其DNA 100配置为最大4K MAC配置,具有4TMAC的原始硬件性能。根据官方数据,DNA 100的性能比竞争解决方案高出4.7倍,它的性能达到了2550fps,而竞争对手的性能为538fps。在能耗比方面,DNA 100相比竞争解决方案也具有2.3倍的优势。当然,测试中的网络经过了修剪,以在DNA 100上达到最好结果。
在软件方面,Cadence提供了一个完整的软件栈和神经网络编译器来充分利用硬件,包括网络分析器和优化器以及所需的设备驱动程序。Cadence最近还宣布,它将支持Facebook的Glow编译器(一个跨硬件平台的机器学习编译器)。
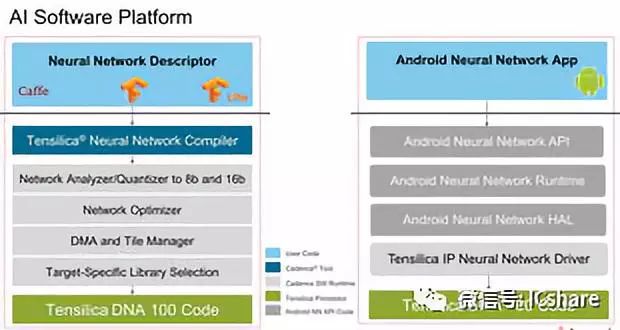
DNA 100的硬件IP将在2019年初获得许可,产品最早将在2020年底左右面世。